


















.png)
OpenAI Realtime API 费用全解析:实测每分钟成本与优化指南
OpenAI的API以其强大的语言处理能力吸引了众多开发者,但许多人对它的费用结构感到困惑。尽管官方说明中提到“按Token计费”,但对于大多数开发者来说,Token的概念并不直观。更常见的问题是:“如果按分钟计算,使用OpenAI Realtime API究竟要花多少钱?”
为了拨开迷雾,我通过Vapi平台对两款主流模型进行了深度实测,用真实数据揭示成本真相,并提供可落地的优化方案。
一、为什么开发者更关心“每分钟通话费用”?
1.1 Token计费的天然门槛
OpenAI的费用公式看似简单(输入Token + 输出Token × 单价),但在实际开发中,开发者常被以下问题困扰:
难以预估开销:1000字文本需要多少Token?5分钟语音对话会消耗多少?
模型差异不透明:
Realtime-gpt-4o-mini-preview-2024-12-17与Realtime-gpt-4o-preview-2024-12-17的Token单价差异多大?隐藏成本陷阱:系统提示词等固定成本如何影响长期支出?
1.2 业务场景的真实需求
在实时语音客服、智能助手等场景中,每分钟成本才是决策核心:
成本预算:若每分钟费用0.5,10分钟通话仅需5;若升至2,成本暴增至20。
性能取舍:高性能模型体验更流畅,但费用可能翻8倍(实测数据见后文)。
规模化挑战:1000次/日的通话,费用差距可达$1500/日,直接影响商业可行性。
二、Token机制:从技术定义到成本映射
2.1 什么是Token?
技术定义:Token是文本处理的最小单位,OpenAI使用BPE算法拆分文本。
英文示例:
"Hello, world!"→["Hello", ",", "world", "!"](4 Tokens)中文示例:
"你好,世界!"→["你", "好", ",", "世", "界", "!"](6 Tokens)
2.2 费用计算公式
单次调用成本 = 输入Token数 × 输入单价 + 输出Token数 × 输出单价
以Realtime-gpt-4o-preview为例:
输入单价:0.00004/Token(即0.00004/Token(即40/百万Token)
输出单价:0.00008/Token(即0.00008/Token(即80/百万Token)
若处理1000输入Token+500输出Token,成本为:(1000×0.00004) + (500×0.00008) = $0.08
2.3 如何计算Token数量?
OpenAI提供了tiktoken库,帮助开发者精确计算Token数量。例如:
import tiktoken
# 初始化编码器
encoder = tiktoken.get_encoding("cl100k_base")
# 计算Token数量
text = "你好,世界!"
tokens = encoder.encode(text)
print(len(tokens)) # 输出:6三、实测数据:不同模型与配置的分钟级成本
3.1 测试方法论
为了更直观地理解OpenAI Realtime API的费用,我们在OpenAI Playground进行了实际测试。测试中,我们选择了两种不同的OpenAI模型:
Realtime-gpt-4o-mini-preview-2024-12-17
Realtime-gpt-4o-preview-2024-12-17
每种模型分别测试了两种配置:
无系统提示词
携带约1000个单词的系统提示词(例如菜单或对话流程)
每次测试完成后,我们从平台的Usage上计算每种配置的实际费用和Token消耗情况,共得到四条测试记录。
3.2 经济型模型(Realtime-gpt-4o-mini-preview-2024-12-17)实测结果
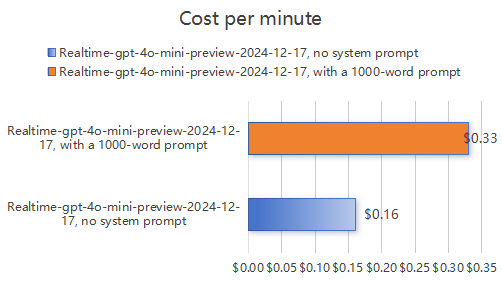
详细分析:
无提示词场景:对应每分钟$0.16的费用。
携带提示词场景:系统提示词(约1300个Tokens)作为固定成本,总费用达$0.33。
3.3 高性能模型(Realtime-gpt-4o-preview-2024-12-17)实测结果
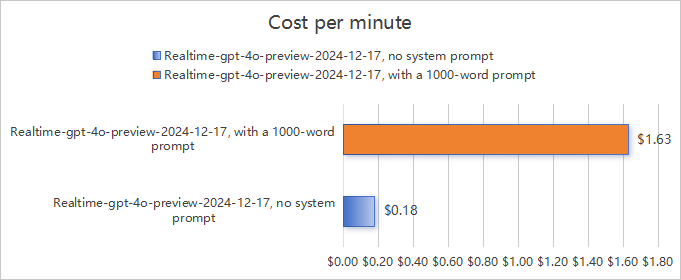
详细分析:
无提示词场景:对应每分钟$0.18的费用。
携带提示词场景:系统提示词(约1300个Tokens)作为固定成本,总费用高达$1.63。
3.4 核心发现
固定成本叠加:系统提示词作为输入Token持续占用配额,每次调用均需计费。
模型差异:Mini模型性价比更高,即使携带1300左右token长度的提示词,每分钟仅需$0.33;Preview模型性能更强,但Token单价更高,且处理长文本时消耗更多Tokens,需谨慎使用提示词。
四、成本优化:从代码到架构的实战策略
4.1 提示词瘦身三原则
删冗余:
# 优化前:冗余描述 prompt = "欢迎光临!我们是一家成立于2010年的连锁餐厅,主打汉堡、披萨和沙拉..." # 优化后:精简核心 prompt = "菜单:汉堡($10)、披萨($12)、沙拉($8)"效果:Token数从200降至40,费用减少80%。
结构化:用JSON替代自然语言
{ "menu": [ {"name": "汉堡", "price": 10}, {"name": "披萨", "price": 12} ] }效果:Token数减少65%,解析效率提升。
动态加载:按需调用提示词模块
if user_intent == "查询菜单": load_prompt("menu_prompt.json") elif user_intent == "售后咨询": load_prompt("service_prompt.json")
4.2 模型选择的黄金法则
简单场景(FAQ、订单查询):
首选
Realtime-gpt-4o-mini,成本可控在$0.33/分钟内。
复杂场景(医疗咨询、多轮对话):
使用
Realtime-gpt-4o,但需通过分段加载提示词将费用压制在$1/分钟以下。
4.3 技术级管控方案
Token硬限制:
response = openai.ChatCompletion.create( model="gpt-4o-mini", messages=messages, max_tokens=150 # 强制缩短回复 )成本熔断机制:
if current_cost > $1.0/minute: switch_model("gpt-4o-mini") # 自动降级
五、总结:在性能与成本间找到平衡点
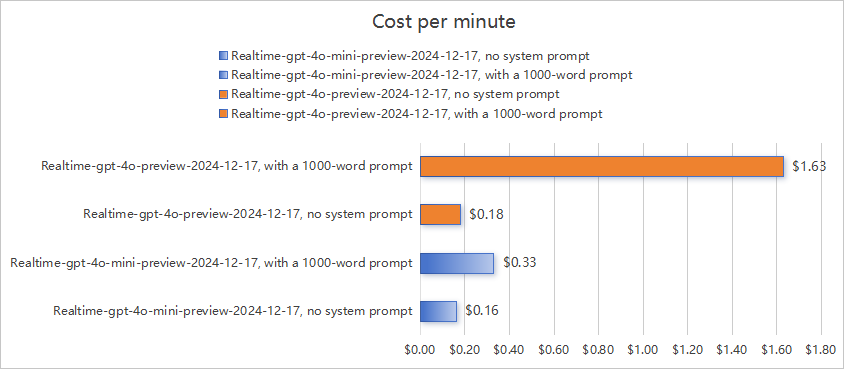
通过实测数据可见,OpenAI Realtime API的成本控制核心在于三点:
提示词的精简与动态化
模型选择的场景适配性
实时监控与熔断机制
建议开发者遵循以下原则:
80%简单场景用Mini:将成本压制在$0.3/分钟内。
20%复杂场景用Preview:通过架构优化避免成本失控。
通过本次实测,我们清晰看到系统提示词与模型选择对成本的巨大影响。开发者需根据业务需求,在性能与成本间找到最佳平衡点。如果您需要进一步的技术支持或测试数据,欢迎在评论区留言!
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝
