


















.png)
GPU 推理性能与成本分析:RTX 4090 、P40 及云端A100、H100 GPU 对比
随着大语言模型进入实际应用阶段,开发者在硬件选型时面临双重挑战:既要满足实时推理的速度需求,又要控制日益增长的算力成本。本文基于对 Deepseek 系列模型(1.5B/7B/14B/32B/70B/671B)的实测数据,通过对比消费级显卡与云端 GPU 的量化指标,揭示不同规模模型下的硬件性能规律。(测试视频与原始数据见文末参考资料)
一、Lambda Labs GPU 实例创建及测试
1. 登录控制台
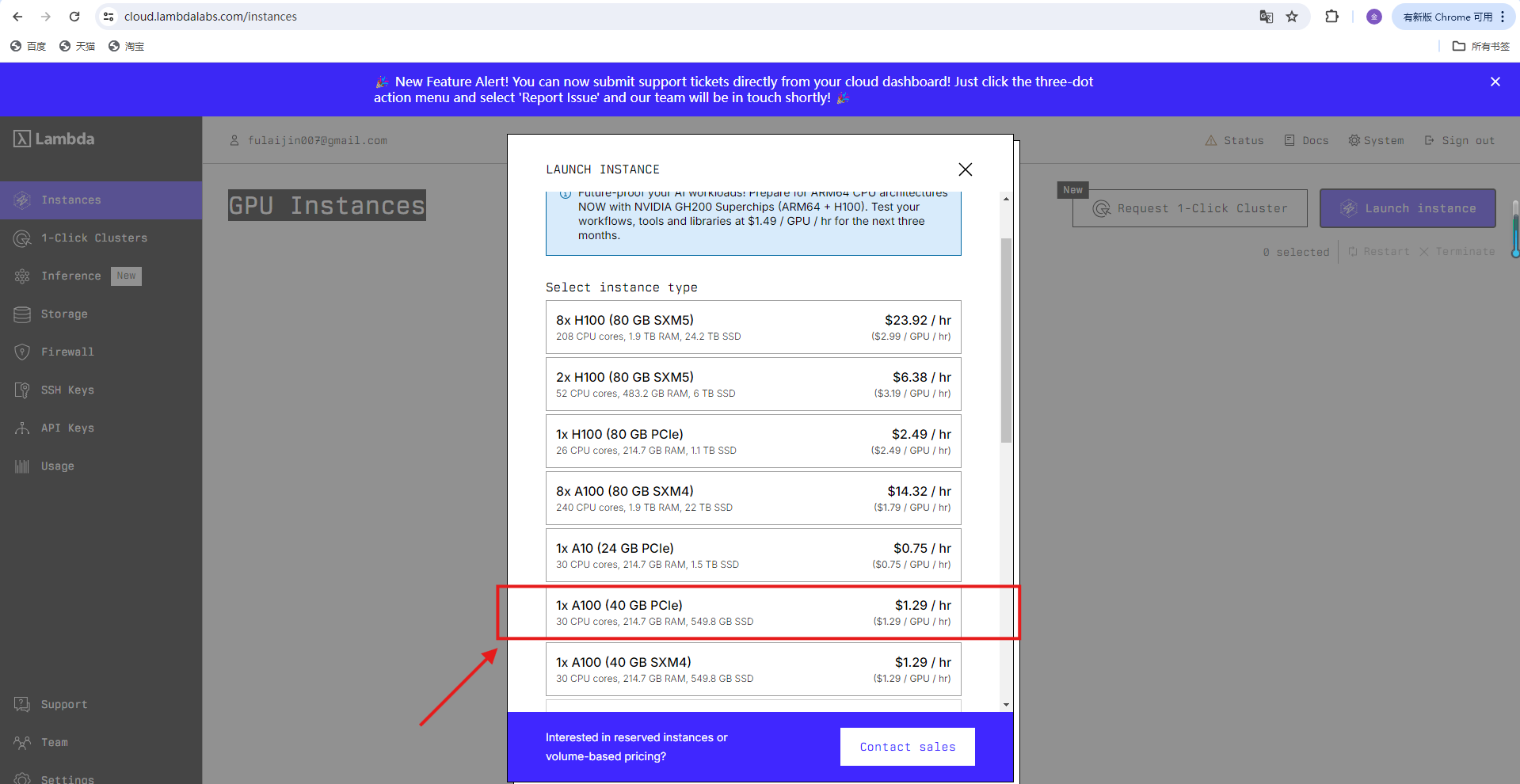
访问 Lambda Labs 控制台 → 选择「Instances」→ 点击「Launch instance」

选择需要租用的型号,并点击创建。并等待部署完成后,点击launch进入操作界面。
2.下载ollama模型,测试deepseek不同模型
选择Terminal,进入命令行模式。
安装ollama:
curl -fsSL https://ollama.com/install.sh | sh测试命令:
ollama run deepseek-r1:1.5b --verbose
ollama run deepseek-r1:7b -- verbose
ollama run deepseek-r1:14b --verbose
ollama run deepseek-r1:32b --verbose
ollama run deepseek-r1:70b --verbose
ollama run deepseek-r1:671b --verbose监控 NVIDIA GPU 的状态:
$ nvidia-smi
$ watch -n 1 nvidia-smi3.测试结果
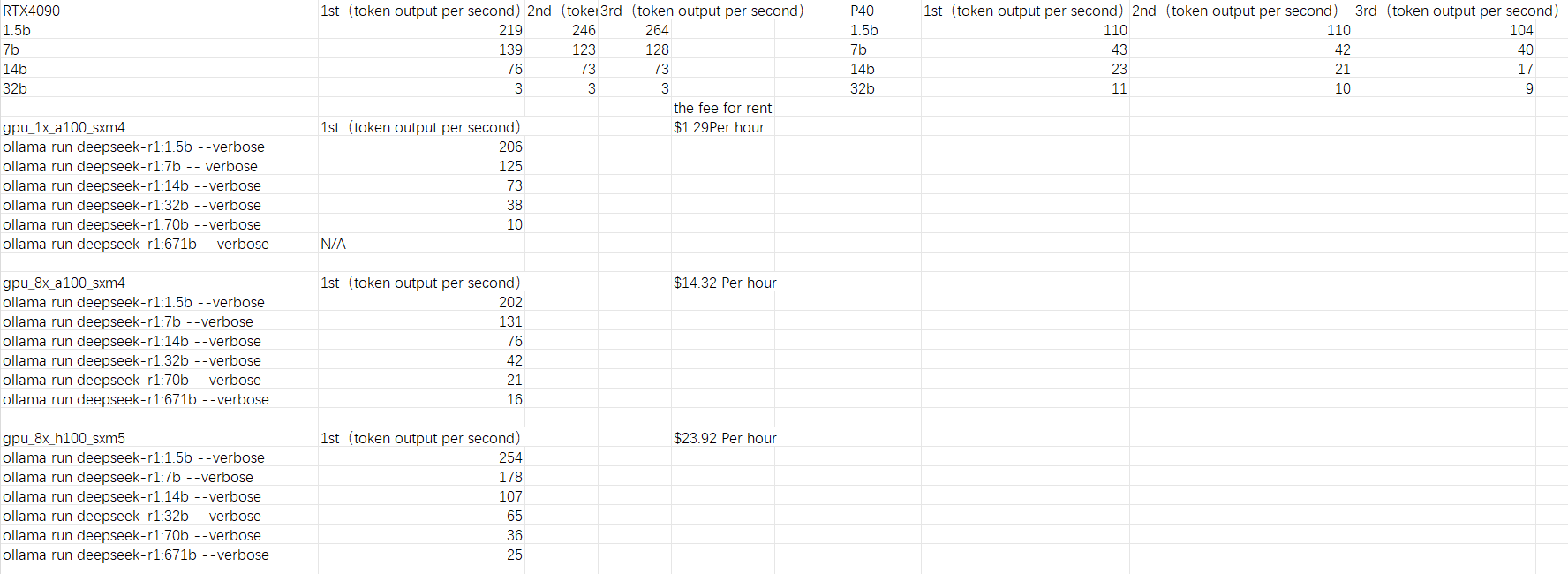
二、消费级显卡:RTX 4090 vs. P40
经过测试,RTX 4090 在多数模型规模下的推理速度显著优于 P40,尤其在中小型模型中优势更为明显:
对于更大的70B、671B的deepseek模型,这两款显卡运行比较吃力。
关键结论:
中小模型首选 RTX 4090:1.5B-14B 模型中,RTX 4090 性能可达 P40 的 2-4 倍,适合需要快速响应的场景(如实时对话)。
大模型 P40 性价比凸显:32B 模型下,P40 性能反超 RTX 4090,可能与显存带宽或优化适配有关,适合预算有限的大模型推理。
二、云端 GPU:A100/H100 集群性能与成本
云端 GPU 提供更强的扩展性,但需权衡时租成本与性能:
关键结论:
轻量任务优选单卡 A100:运行 1.5B 模型时,1x A100 的性价比远超集群,适合个人开发者或小规模应用。
大模型需集群支持:70B/671B 模型在 8x H100 上可达 21-25 tokens/s,但成本陡增,适合企业级高负载场景。
H100 性能优势显著:同规模模型下,8x H100 比 8x A100 提速约 20-50%,但需评估成本增量是否合理。
三、GPU 详细对比表格
四、硬件选型建议
个人开发者/小团队
模型规模 ≤14B:优先选择 RTX 4090,低成本获得高推理速度。
模型规模 ≥32B:考虑 P40 组建多卡集群,平衡显存与成本。
企业级应用
常规负载:采用 8x A100 集群,兼顾吞吐量与成本。
极致性能需求:选择 8x H100 集群,尤其适合千亿参数模型实时推理。
云端成本优化策略
通过弹性伸缩(如 AWS 竞价实例)降低闲置时段的资源浪费。
对延迟不敏感的任务(如批量处理)可优先使用 1x A100
附录
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝
