



















深入掌握Redis:从原理到实践的全方位指南
本文总体架构


一、引言:为什么学习Redis?——解码现代高性能系统的核心基石
在数字经济的浪潮中,数据以每秒数亿次的速度在全球网络中奔涌。当淘宝在“双十一”创下每秒58.3万笔订单的世界纪录,当抖音直播间百万用户同时点赞互动,当《原神》全球玩家在开放世界中实时协作——这些现象级场景的背后,都隐藏着一个关键技术:Redis。这个诞生于2009年的内存数据库,如今已成为互联网基础设施中不可或缺的“涡轮增压器”。它不仅重新定义了数据处理的性能边界,更在技术演进史中书写了从边缘工具到核心组件的逆袭传奇。
1.1 技术革命:从磁盘到内存的范式颠覆
传统关系型数据库(如Oracle、MySQL)的架构设计,始终围绕磁盘I/O展开。即便通过索引优化、读写分离等手段,单机QPS(每秒查询数)也很难突破2万,且响应时间常在10毫秒以上。这种性能天花板在移动互联网时代遭遇致命挑战:
社交平台的实时消息推送需要毫秒级延迟
金融支付系统要求每秒处理数十万事务
物联网设备每秒产生百万级传感器数据
Redis的破局之道在于彻底重构存储范式。它将数据完全置于内存,通过单线程事件循环模型消除多线程锁竞争,配合非阻塞I/O复用技术(Linux的epoll、BSD的kqueue),在主流服务器上轻松实现15万QPS的超高性能。这种设计看似违背“多核时代应充分利用CPU”的常识,却因极简架构减少了上下文切换开销,反而在多数场景下比多线程方案更快。正如Redis之父Salvatore Sanfilippo所言:“CPU从来不是Redis的瓶颈,网络和内存才是”。
1.2 商业价值:万亿级市场的技术支点
根据DB-Engines 2024年最新统计,Redis在键值存储领域以53.2%的使用率遥遥领先,超过MongoDB、Cassandra等同类产品的总和。这种统治级地位源于其创造的商业价值:
成本杀手:用1%的资源承载100%的流量
电商巨头拼多多在2023年“618”大促期间,通过三级缓存架构(Nginx+Lua本地缓存 → Redis集群 → MySQL),仅用200台Redis节点就支撑起峰值每秒120万次的商品查询请求。若直接使用MySQL,需要至少5000台服务器,硬件成本相差25倍。这种“内存换磁盘”的经济学,让企业能以千万级投入撬动百亿GMV。创新引擎:重构产品体验的技术杠杆
当网易云音乐用Redis的有序集合(Sorted Set)实时更新歌曲排行榜,用户每首歌曲的播放都会触发ZINCRBY命令,系统在0.3毫秒内完成分数更新并返回最新排名。这种“所见即所得”的交互体验,使得用户留存率提升17%。而在微博热搜场景中,Redis的HyperLogLog结构以12KB内存存储1.8亿用户ID,实现UV统计误差率<1%,帮助运营团队精准捕捉热点趋势。故障防火墙:避免百万级损失的容灾方案
2022年某跨国银行因数据库主从延迟导致账户余额显示错误,引发客户集体诉讼,单日损失达230万美元。此后该银行在核心交易链路引入Redis集群,利用其同步写机制(WAIT命令)确保至少3个副本写入成功,将数据不一致风险降低至0.0001%。这种金融级可靠性,使得Redis在证券、支付等领域的渗透率两年内增长300%。
1.3 生态演进:从缓存中间件到全场景数据平台
Redis的野心远不止于缓存。自4.0版本引入模块化架构后,它已蜕变为支持多模型的数据平台:
实时机器学习:RedisAI模块允许直接加载TensorFlow/PyTorch模型,对用户行为数据实时推理。某短视频平台利用此功能,将推荐模型推理延迟从23ms降至1.7ms。
时空数据引擎:GEO模块支撑美团骑手路径规划,通过
GEORADIUS命令在50毫秒内找出3公里内空闲骑手,配送时效提升40%。文档数据库:RedisJSON支持JSON文档存储与嵌套查询,某医疗平台用其存储患者电子病历,查询效率比MongoDB快8倍。
向量搜索引擎:2023年发布的RedisVL模块支持十亿级向量相似度搜索,帮助ChatGPT类应用实现长文本语义检索,准确率提升34%。
这种生态扩张的背后,是Redis社区每年超过1500名开发者的持续贡献。从最初仅4万行代码的轻量级工具,到如今支持流处理(Stream)、时序数据(TimeSeries)、图计算(Graph)的超级平台,Redis正在重定义“数据库”的边界。
1.4 开发者生存法则:不懂Redis,何谈架构?
在LinkedIn 2024年发布的《全球开发者技能报告》中,Redis以89%的提及率位居“后端必备技能”榜首。这种需求源于两个残酷现实:
面试的“龙门关卡”
阿里资深技术面试官张勇透露:“所有P7及以上岗位候选人,必须能白板手写RedLock算法,并解释时钟漂移对分布式锁的影响。”高频考点包括:持久化机制如何选择?
缓存穿透/雪崩的工业级解决方案
Cluster模式下数据迁移原理
生产环境的“达摩克利斯之剑”
某电商平台曾因未设置内存淘汰策略,导致Redis内存溢出,全站瘫痪11小时,直接损失超2亿元。此类事故催生出新的职业方向——Redis性能调优师,顶尖人才日薪可达5000美元。
1.5 未来十年:站在算力革命的风口
随着5G和边缘计算的普及,全球数据量正以每年28%的速度暴增。Redis的响应速度优势将在三大领域爆发:
元宇宙实时交互:Unity引擎已集成Redis-Stack,实现百万玩家同屏时的亚毫秒级状态同步
自动驾驶决策:特斯拉FSD系统用Redis缓存高精地图数据,将路径规划延迟压缩至0.8毫秒
量子计算预处理:IBM量子实验室使用Redis集群管理量子比特状态数据,预处理效率提升22倍
在这场算力革命中,掌握Redis不再是为了应对面试,而是为了在技术浪潮中抢占先机。当你读完这篇博客时,全球Redis节点已处理了超过2.1亿次请求——这个数字,或许就是你的下一个机会。
二、Redis基础知识
2.1 Redis是什么?
Redis(Remote Dictionary Server) 是一个开源的 内存数据结构存储系统,被广泛用作数据库、缓存和消息中间件。其核心设计围绕 高性能 和 灵活的数据结构,支持多种数据类型(如字符串、哈希、列表等),并能在内存中快速处理大规模数据。以下是 Redis 的三大核心定义:
2.1.1 内存数据库(In-Memory Database)
Redis 的 数据主要存储在内存(RAM)中,而非传统数据库依赖的磁盘。这使得其读写速度达到 微秒级(μs),远超磁盘数据库(如 MySQL 的毫秒级响应)。
性能示例:单节点 Redis 每秒可处理 10万+ 次读写请求,延迟低至 0.1ms。例如,新浪微博使用 Redis 缓存用户动态,支撑每秒 120 万次请求。
持久化机制:为防止数据丢失,Redis 提供两种持久化方式:
RDB(快照):定期生成全量数据镜像(如每小时备份一次),适合灾难恢复。
AOF(追加日志):记录每次写操作,可配置为每秒同步一次(
appendfsync everysec),数据丢失风险低至秒级。
适用场景:高频读写(如缓存、实时计数器),但不适合存储超大规模数据(受限于内存容量)。
2.1.2 键值存储(Key-Value Store)
Redis 以 键值对(Key-Value) 形式组织数据,键(Key)为唯一标识符,值(Value)支持多种数据结构。
键的设计:
推荐使用
业务:类型:ID的命名规范(如user:1001:profile),便于管理和查询。支持自动过期(
EXPIRE命令),通过 惰性删除(访问时检查过期)和 定期删除(每秒随机扫描部分键)释放内存。
值的灵活性:
值不仅可以是简单字符串,还可以是哈希、列表、集合等复杂结构。例如:
# 存储用户信息(哈希) HSET user:1001 name "Alice" age 30 # 存储最新文章列表(列表) LPUSH news:latest "头条新闻
多数据库支持:默认提供 16 个逻辑数据库(
SELECT 0-15),但实际应用中更推荐通过键名前缀隔离业务。
2.1.3 数据结构服务器(Data Structure Server)
Redis 的核心竞争力在于其 内置的 8 种数据结构,每种结构支持原子操作,可直接解决复杂业务问题:
| 数据结构 | 特性 | 应用场景 | 示例命令 |
|---|---|---|---|
| 字符串(String) | 最大 512MB,支持二进制数据 | 缓存、分布式锁 | SET user:1001 "Alice" EX 3600 |
| 哈希(Hash) | 字段级操作,内存高效(ziplist 编码) |
存储对象属性 | HSET product:2001 price 599 stock 50 |
| 有序集合(Sorted Set) | 按分数排序,支持范围查询 | 排行榜、延迟队列 | ZADD leaderboard 1500 "playerA" |
| 列表(List) | 双向链表,支持阻塞弹出(BLPOP) |
消息队列、最新动态 | LPUSH orders "order_1001" |
| 集合(Set) | 无序唯一元素 | 标签存储、共同好友 | SADD user:1001:tags "科技" "编程" |
| 位图(Bitmap) | 位操作 | 日活统计、签到记录 | SETBIT active:20231001 10000001 1 |
| HyperLogLog | 基数统计,误差 <1%(如 12KB 内存统计 1.8 亿用户) | UV 统计 | PFADD uv:20231001 "user1001" |
| 地理空间(GEO) | 存储经纬度,支持范围搜索 | 附近的人、商家推荐 | GEOADD cities 116.40 39.90 "北京" |
2.2 Redis vs 其他数据库
2.2.1 Redis vs MySQL:内存与磁盘的终极较量
| 维度 | Redis | MySQL |
|---|---|---|
| 存储介质 | 数据主要存储在内存(RAM),通过异步持久化到磁盘 | 数据存储在磁盘(B+树索引优化读写) |
| 读写性能 | 微秒级响应(10万+ QPS),适合高频操作 | 毫秒级响应(1万+ QPS),依赖磁盘IO |
| 事务支持 | 仅支持简单事务(无回滚) | 完整ACID事务(原子性、一致性、隔离性) |
| 数据结构 | 8种复杂结构(如Sorted Set、HyperLogLog) |
二维表结构,支持复杂SQL查询 |
| 扩展性 | 通过分片(Cluster)横向扩展,但内存成本高 |
通过主从复制和分库分表扩展,适合PB级数据 |
选型建议:
选择Redis:高频读写——如缓存热点数据(商品详情页)、实时计数器(点击量统计);低延迟需求——游戏排行榜、分布式锁(秒杀系统)。
选择MySQL:复杂查询——多表关联分析、金融交易流水;数据持久化——需长期存储且数据规模超内存容量。
2.2.2 Redis vs Memcached:缓存领域的王者之争
| 维度 | Redis | Memcached |
|---|---|---|
| 数据结构 | 8种(如List、Sorted Set、Geo) |
仅字符串(值最大1MB) |
| 持久化 | RDB快照 + AOF日志(数据可恢复) |
无持久化(重启后数据丢失) |
| 内存管理 | 动态回收过期数据(TTL+LRU) |
固定内存块分配(需重启释放) |
| 适用场景 | 多功能缓存、消息队列、实时分析 |
简单缓存(静态HTML片段、临时会话) |
选型建议:
选择Redis:多功能需求——如消息队列(List)、实时排行榜(Sorted Set);数据安全——需持久化防止重启丢失(如用户会话)。
选择Memcached:纯缓存场景——如CDN节点缓存静态资源(图片、CSS);极致简单性——无需复杂功能,追求部署轻量。
2.2.3 Redis vs MongoDB:结构化与非结构化的博弈
| 维度 | Redis | MongoDB |
|---|---|---|
| 数据模型 | 键值+结构化数据(如Hash/List) |
文档模型(类JSON),支持嵌套结构 |
| 查询能力 | 简单范围查询,依赖数据结构特性 | 复杂聚合查询(如$group、$lookup) |
| 扩展性 | 分片扩容受限(内存成本高) | 自动分片(Sharding),适合PB级数据 |
| 写入性能 | 单节点10万+ QPS(内存优势) | 1万~5万 QPS(依赖磁盘持久化) |
选型建议:
选择Redis:实时计算——如在线用户统计(Bitmap)、地理位置服务(GEO);低延迟写入——物联网设备数据采集(每秒万级写入)。
选择Memcached:复杂文档存储——如电商商品详情(多规格、多属性嵌套);大数据分析——需执行MapReduce或聚合管道。
2.2.4 何时选择Redis?何时不适用?
选择Redis的五大场景:
高频读写:缓存热点数据(如商品详情页),QPS超过1万
低延迟需求:实时排行榜(游戏积分)、分布式锁(秒杀系统)
复杂数据结构:社交关系(Set交集)、消息队列(List)
实时计算:在线用户统计(Bitmap)、UV统计(HyperLogLog)
地理位置服务:附近的人、商家推荐(GEO命令)
避免使用Redis的四大场景:
数据规模超内存:若数据量超过集群内存容量(如PB级日志),优先选MongoDB
复杂事务需求:需多表关联+回滚(如金融交易),MySQL更合适
长期存储+复杂分析:需执行JOIN或窗口函数,选Hadoop或ClickHouse
低成本存储:内存成本是磁盘的10倍以上,冷数据建议存MySQL或MongoDB
✒️笔者推荐的黄金组合与混合架构:
热数据:Redis缓存(会话、计数器) + 冷数据:MySQL/MongoDB持久化存储
混合架构:Redis前置加速(如实时排行榜) + 磁盘数据库兜底(如订单历史)
警惕边界:Redis不是万能的,需根据数据规模、查询复杂度、成本综合选型
2.3 核心数据结构与命令
2.3.1 键(Key)命令
Redis 是 key-value 型数据库,键(Key)命令是 Redis 中经常使用的命令。常用的键命令如下所示:
| 命令 | 语法 | 参数说明 | 示例 | 返回值说明 | 典型场景 | 注意事项 |
|---|---|---|---|---|---|---|
| DEL | DEL key [key ...] |
删除一个或多个键(支持批量操作) | DEL user:1001 product:2001 |
返回成功删除的键数量 | 清理过期数据、批量删除无效键 | 删除不存在的键不会报错,返回 0 |
| DUMP | DUMP key |
序列化指定键的值,返回序列化后的二进制数据 | DUMP user:1001 |
序列化字符串或 nil(键不存在) |
数据迁移、持久化存储前的序列化操作 | 需结合 RESTORE 命令恢复数据 |
| EXISTS | EXISTS key [key ...] |
检查一个或多个键是否存在 | EXISTS session:abc123 |
返回存在的键数量(如 1 或 0) |
验证缓存有效性、检查资源是否存在 | 支持批量查询(Redis 3.0.3+) |
| EXPIRE | EXPIRE key seconds |
为键设置过期时间(秒) | EXPIRE cache:product:2001 3600 |
1(成功)或 0(键不存在/未设置) |
缓存自动失效、会话超时管理 | 若键已设置过期时间,会覆盖旧值 |
| EXPIREAT | EXPIREAT key timestamp |
设置键在指定 UNIX 时间戳(秒级)过期 | EXPIREAT order:20231001 1696118400 |
1(成功)或 0(键不存在) |
定时任务触发、固定时间点数据清理 | 时间戳需为整数(如 date +%s 获取当前秒级时间戳) |
| PEXPIRE | PEXPIRE key milliseconds |
为键设置过期时间(毫秒) | PEXPIRE temp:data 5000 |
1(成功)或 0(键不存在) |
高精度超时控制(如分布式锁) | 5 秒 = 5000 毫秒 |
| PEXPIREAT | PEXPIREAT key timestamp-milliseconds |
设置键在指定 UNIX 时间戳(毫秒级)过期 | PEXPIREAT log:20231001 1696118400000 |
1(成功)或 0(键不存在) |
毫秒级定时任务(如金融交易系统) | 毫秒级时间戳可通过 date +%s%3N 获取 |
| KEYS | KEYS pattern |
模糊匹配键(如 * 匹配所有) |
KEYS user:* |
返回匹配的键列表 | 开发环境调试、快速查找特定模式键 | 生产环境禁用!可能阻塞服务,建议用 SCAN 分页遍历 |
| MOVE | MOVE key db |
将键移动到指定数据库(db 范围 0-15) |
MOVE temp:data 1 |
1(成功)或 0(目标数据库已存在) |
多数据库管理、临时数据隔离 | 目标数据库必须存在且键未被占用 |
| PERSIST | PERSIST key |
移除键的过期时间,使其永久存在 | PERSIST session:abc123 |
1(成功)或 0(键不存在/无过期) |
取消自动过期策略(如永久配置项) | 仅对已设置过期时间的键生效 |
| PTTL | PTTL key |
返回键剩余过期时间(毫秒) | PTTL cache:product:2001 |
剩余毫秒数,-1(无过期),-2(键不存在) |
高精度过期监控(如实时系统) | 精确到毫秒级,适用于分布式锁续期 |
| TTL | TTL key |
返回键剩余过期时间(秒) | TTL user:1001 |
剩余秒数,-1(无过期),-2(键不存在) |
常规缓存生命周期管理 | 秒级精度,适用于大多数业务场景 |
| RANDOMKEY | RANDOMKEY |
随机返回当前数据库中的一个键 | RANDOMKEY |
键名或 nil(数据库为空) |
数据抽样检查、调试空数据库 | 不保证均匀分布,仅用于简单场景 |
| RENAME | RENAME key newkey |
重命名键(若 newkey 已存在,则覆盖其值) |
RENAME user:old user:new |
OK(成功) |
键名重构、数据版本迁移 | 覆盖风险!确保 newkey 可被安全替换 |
| RENAMENX | RENAMENX key newkey |
仅当 newkey 不存在时重命名键 |
RENAMENX temp:data temp:backup |
1(成功)或 0(newkey 已存在) |
安全重命名(如备份操作) | 避免数据丢失的核心命令 |
| TYPE | TYPE key |
返回键存储的数据类型 | TYPE leaderboard |
类型名称或 none(键不存在) |
动态处理数据(如根据类型执行不同逻辑) | 返回类型为小写字符串(如 "hash") |
2.3.2 String 命令
Strings(字符串)结构是 Redis 的基本数据类型,值value是字符串类型,常用命令:
| 命令 | 语法 | 参数说明 | 示例 | 返回值说明 | 典型场景 | 注意事项 |
|---|---|---|---|---|---|---|
| SET | SET key value [EX seconds] [PX milliseconds] [NX|XX] |
支持:
EX:秒级过期
PX:毫秒级过期
NX:键不存在时生效
XX:键存在时生效
|
SET user:1001 "Alice" EX 3600 NX |
OK 或 nil(条件不满足) |
分布式锁、会话存储 | NX/XX互斥,未指定时覆盖旧值 |
| GET | GET key |
获取字符串值 | GET product:2001:detail |
字符串或 nil |
读取缓存 | 非字符串类型返回错误 |
| GETRANGE | GETRANGE key start end |
截取子串(闭区间,下标从0开始) | GETRANGE log:20231001 0 100 |
子串内容或空字符串 | 日志摘要 | 支持-1表示最后字符 |
| GETSET | GETSET key value |
设置新值返回旧值 | GETSET counter:views "1000" |
旧值或 nil |
计数器重置 | 键不存在时创建新键 |
| GETBIT | GETBIT key offset |
获取二进制位(0/1) | GETBIT active:20231001 10000001 |
0 或 1 |
用户签到统计 | 偏移量超范围返回0 |
| MGET | MGET key [key ...] |
批量获取值 | MGET user:1001 user:1002 |
值列表(含nil) |
批量读缓存 | 非字符串键返回nil |
| SETBIT | SETBIT key offset value |
设置二进制位(0/1) | SETBIT active:20231001 10000001 1 |
修改前的原值 | 布隆过滤器 | 偏移量过大用\x00填充 |
| SETEX | SETEX key seconds value |
设置值+秒级过期 | SETEX session:abc123 3600 "{...}" |
OK |
会话存储 | 等价SET key value EX seconds |
| SETNX | SETNX key value |
键不存在时设置值 | SETNX lock:order_1001 "locked" |
1(成功)/0 |
分布式锁 | 键存在则失败 |
| SETRANGE | SETRANGE key offset value |
覆写字符串内容 | SETRANGE log:error 1024 "ERROR: timeout" |
新字符串长度 | 动态修改日志 | 超长填充\x00 |
| STRLEN | STRLEN key |
返回字节数 | STRLEN log:20231001 |
整数长度(键不存在返回0) |
监控数据大小 | 包含二进制安全字符 |
| MSET | MSET key value [key value ...] |
批量设置键值 | MSET user:1001 "Alice" user:1002 "Bob" |
OK |
批量初始化 | 原子操作,全成功或全失败 |
| MSETNX | MSETNX key value [key value ...] |
全不存在时批量设置 | MSETNX config:port 8080 config:host "127.0.0.1" |
1(成功)/0 |
全局配置 | 任一键存在则全部失败 |
| PSETEX | PSETEX key milliseconds value |
设置值+毫秒级过期 | PSETEX temp:data 5000 "临时数据" |
OK |
限时验证码 | 等价SET key value PX milliseconds |
| INCR | INCR key |
原子性+1 | INCR article:1001:views |
递增后的值 | 阅读量统计 | 键不存在初始为0 |
| INCRBY | INCRBY key increment |
增减整数 | INCRBY inventory:2001 -5 |
新整数值 | 库存扣减 | 支持负数 |
| INCRBYFLOAT | INCRBYFLOAT key increment |
增减浮点数 | INCRBYFLOAT balance:1001 50.5 |
新浮点值 | 金额计算 | 精度问题(如0.1+0.2≠0.3) |
| DECR | DECR key |
原子性-1 | DECR seats:available |
递减后的值 | 名额管理 | 等价INCRBY -1 |
| DECRBY | DECRBY key decrement |
减指定整数 | DECRBY stock:2001 10 |
新整数值 | 批量扣减 | 支持负数 |
| APPEND | APPEND key value |
追加字符串 | APPEND log:20231001 "[ERROR] timeout\n" |
新长度 | 实时日志 | 键不存在时等效SET |
2.3.3 Hash 命令
Hash(哈希散列)是 Redis 基本数据类型,值value 中存储的是 hash 表。Hash 特别适合用于存储对象。常用的命令:
| 命令 | 语法 | 参数说明 | 示例 | 返回值说明 | 典型场景 | 注意事项 |
|---|---|---|---|---|---|---|
| HDEL | HDEL key field [field ...] |
删除哈希表的一个或多个字段 | HDEL user:1001 age address |
成功删除的字段数量 | 动态移除对象属性 | 不存在的字段不计入结果 |
| HEXISTS | HEXISTS key field |
检查字段是否存在 | HEXISTS product:2001 price |
1(存在)/0(不存在) |
验证配置项完整性 | 键不存在时直接返回0 |
| HGET | HGET key field |
获取单个字段值 | HGET user:1001 name |
字段值或nil |
读取对象属性 | 非哈希类型返回错误 |
| HGETALL | HGETALL key |
获取所有字段和值 | HGETALL config:app |
交替列表(如["field1","val1","field2","val2"]) |
读取完整配置 | 大哈希阻塞风险,建议用HSCAN |
| HINCRBY | HINCRBY key field increment |
字段值原子性增减整数 | HINCRBY product:2001 stock -5 |
操作后的新整数值 | 库存扣减 | 字段值必须为整数 |
| HKEYS | HKEYS key |
获取所有字段名 | HKEYS user:1001 |
字段名列表(如["name","age"]) |
获取属性列表 | 大哈希建议分页操作 |
| HLEN | HLEN key |
统计字段数量 | HLEN product:2001 |
整数(键不存在返回0) |
属性数量统计 | O(1)时间复杂度,适合高频调用 |
| HSET | HSET key field value [field value ...] |
批量设置字段值 | HSET user:1001 name "Alice" age 30 |
新增/更新的字段数 | 对象属性存储 | 原子性批量操作 |
| HVALS | HVALS key |
获取所有字段值 | HVALS config:app |
值列表(如["val1","val2"]) |
提取属性值列表 | 大哈希建议分页操作 |
2.3.4 List 命令
List 是 Redis 中最常用数据类型。值value 中存储的是列表。常用的命令:
| 命令 | 语法 | 参数说明 | 示例 | 返回值说明 | 典型场景 | 注意事项 |
|---|---|---|---|---|---|---|
| BLPOP | BLPOP key [key ...] timeout |
阻塞式左端弹出元素(列表为空时最多阻塞 timeout 秒) | BLPOP tasks 30 |
键名和元素,或 nil(超时) |
消息队列 | 多键时按顺序检查,优先返回首个非空列表 |
| BRPOP | BRPOP key [key ...] timeout |
阻塞式右端弹出元素(功能同 BLPOP,方向相反) | BRPOP notifications 10 |
同 BLPOP | 实时通知系统 | 慎用长阻塞,避免连接堆积 |
| BRPOPLPUSH | BRPOPLPUSH source destination timeout |
从 source 右端弹出元素并插入 destination 左端 | BRPOPLPUSH backup:queue main:queue 5 |
元素或 nil(超时) |
安全任务转移 | 适用于需备份/重试的队列 |
| LINDEX | LINDEX key index |
通过索引获取元素(支持负数,如 -1 表示最后元素) |
LINDEX news:latest 0 |
元素值或 nil(越界) |
读取最新头条 | 时间复杂度 O(n),大列表慎用 |
| LINSERT | LINSERT key BEFORE|AFTER pivot value |
在 pivot 元素前/后插入新元素 | LINSERT news:latest BEFORE "头条" "新头条" |
列表长度或 -1(pivot 不存在) |
动态调整内容 | 需确保 pivot 存在 |
| LLEN | LLEN key |
获取列表长度 | LLEN tasks |
长度值(键不存在返回 0) |
监控队列堆积 | O(1) 时间复杂度,适合高频调用 |
| LPOP | LPOP key |
左端弹出元素 | LPOP tasks |
元素值或 nil(空列表) |
非阻塞任务处理 | 需自行处理空队列 |
| LPUSH | LPUSH key value [value ...] |
左端插入一个或多个元素 | LPUSH news:latest "头条新闻" |
操作后列表长度 | 消息发布 | 原子性批量操作 |
| LPUSHX | LPUSHX key value |
仅当列表存在时左端插入元素 | LPUSHX news:latest "新动态" |
列表长度(键不存在返回 0) |
条件性插入 | 需列表已存在 |
| LRANGE | LRANGE key start stop |
获取索引范围内的元素(闭区间) | LRANGE news:latest 0 9 |
元素列表 | 分页查询 | 避免LRANGE key 0 -1(全量遍历) |
| LREM | LREM key count value |
删除前 count 次出现的 value:
count>0:左到右删
count<0:右到左删
count=0:删全部
|
LREM comments 0 "spam" |
实际删除数量 | 清理垃圾数据 | O(n) 时间复杂度,大列表慎用 |
| LSET | LSET key index value |
设置指定索引的元素值 | LSET config:order 0 "new_rule" |
OK 或错误(越界) |
动态修改配置 | 索引必须在有效范围 |
| LTRIM | LTRIM key start stop |
保留指定索引范围的元素 | LTRIM logs:20231001 0 999 |
OK |
控制列表大小 | 结合LPUSH实现固定长度队列 |
| RPOP | RPOP key |
右端弹出元素 | RPOP tasks |
元素值或 nil(空列表) |
非阻塞任务处理 | 操作方向与 LPOP 相反 |
| RPOPLPUSH | RPOPLPUSH source destination |
从 source 右端弹出并插入 destination 左端 | RPOPLPUSH main:queue backup:queue |
元素值或 nil(source 为空) |
任务备份 | 原子性替代 RPOP + LPUSH |
| RPUSH | RPUSH key value [value ...] |
右端插入一个或多个元素 | RPUSH logs:app "[INFO] Started" |
列表长度 | 日志追加 | 与 LPUSH 方向相反 |
| RPUSHX | RPUSHX key value |
仅当列表存在时右端插入元素 | RPUSHX logs:error "[ERROR] Timeout" |
列表长度(键不存在返回 0) |
条件性追加 | 类似 LPUSHX,方向相反 |
2.3.5 Set 命令
| 命令 | 语法 | 参数说明 | 示例 | 返回值说明 | 典型场景 | 注意事项 |
|---|---|---|---|---|---|---|
| SADD | SADD key member [member ...] |
添加一个或多个成员 | SADD tags:article:1001 tech redis |
成功添加数量(重复不计) | 标签系统、好友列表 | 百万级集合建议分批次操作 |
| SCARD | SCARD key |
获取集合成员数量 | SCARD user:1001:followers |
整数(键不存在返回0) |
统计粉丝数 | O(1)时间复杂度,高频友好 |
| SDIFF | SDIFF key [key ...] |
计算第一个集合的差集 | SDIFF user:A:friends user:B:friends |
差集成员列表 | 好友推荐 | 多集合顺序计算(A - B - C) |
| SDIFFSTORE | SDIFFSTORE destination key [key ...] |
存储差集结果 | SDIFFSTORE result A B |
差集成员数量 | 持久化差集数据 | 目标集合覆盖写入 |
| SINTER | SINTER key [key ...] |
计算多个集合交集 | SINTER group:admins group:active |
交集成员列表 | 权限验证 | 大集合建议分片处理 |
| SINTERSTORE | SINTERSTORE destination key [key ...] |
存储交集结果 | SINTERSTORE result A B |
交集成员数量 | 公共数据缓存 | 原子操作,覆盖目标集合 |
| SISMEMBER | SISMEMBER key member |
验证成员存在性 | SISMEMBER user:1001:likes article:2001 |
1(存在)/0(不存在) |
权限检查 | O(1)时间复杂度 |
| SMEMBERS | SMEMBERS key |
获取所有成员 | SMEMBERS tags:article:1001 |
成员列表(如["tech","redis"]) | 获取完整标签 | 大集合禁用!用SSCAN分页 |
| SMOVE | SMOVE source destination member |
跨集合移动成员 | SMOVE temp:blacklist main:blacklist user:1001 |
1(成功)/0(失败) |
数据分类 | 源和目标必须是集合类型 |
| SPOP | SPOP key [count] |
随机移除成员 | SPOP lottery:winners 3 |
被移除成员列表 | 抽奖系统 | count超过大小时删除键 |
| SRANDMEMBER | SRANDMEMBER key [count] |
随机获取成员 | SRANDMEMBER user:1001:recommendations 5 |
随机成员列表 | 随机推荐 | count>0时不重复,count<0可重复 |
| SREM | SREM key member [member ...] |
移除指定成员 | SREM user:1001:blocked user:2001 |
成功移除数量 | 清理黑名单 | 不存在的成员不计入结果 |
| SUNION | SUNION key [key ...] |
计算集合并集 | SUNION group:A group:B |
去重后的并集列表 | 数据合并 | 大集合建议分片处理 |
| SUNIONSTORE | SUNIONSTORE destination key [key ...] |
存储并集结果 | SUNIONSTORE result A B |
并集成员数量 | 持久化合并数据 | 目标集合覆盖写入 |
| SSCAN | SSCAN key cursor [MATCH pattern] [COUNT count] |
增量遍历集合 | SSCAN user:1001:followers 0 MATCH "u*" COUNT 100 |
新游标+匹配成员列表 | 安全遍历大集合 | 游标0表示开始,可能返回重复数据 |
2.3.6 Zset 命令
下表列出了 Redis 有序集合的基本命令:
| 命令 | 语法 | 参数说明 | 示例 | 返回值说明 | 典型场景 | 注意事项 |
|---|---|---|---|---|---|---|
| ZADD | ZADD key [NX|XX] [CH] [INCR] score member [...] |
- NX:仅新增成员 - XX:仅更新成员 - CH:返回变更总数 - INCR:增量模式 |
ZADD leaderboard 1000 "Alice" 950 "Bob" |
新增数量或变更总数(CH) | 实时排行榜 | 大集合性能下降,建议分片 |
| ZCARD | ZCARD key |
获取成员总数 | ZCARD leaderboard |
整数(键不存在返回0) |
统计在线用户数 | O(1)时间复杂度 |
| ZCOUNT | ZCOUNT key min max |
统计分数区间成员 | ZCOUNT leaderboard 800 1200 |
符合条件的数量 | 筛选活跃用户 | 支持(800(不包含)等符号 |
| ZINCRBY | ZINCRBY key increment member |
分数增量操作 | ZINCRBY leaderboard 50 "Alice" |
更新后的分数值 | 游戏得分更新 | 成员不存在时自动创建 |
| ZINTERSTORE | ZINTERSTORE dest numkeys key [...] [WEIGHTS] [AGGREGATE] |
- WEIGHTS:权重 - AGGREGATE:聚合方式 |
ZINTERSTORE result 2 A B WEIGHTS 2 3 |
结果集成员数量 | 多维排行榜合并 | 避免大集合直接计算 |
| ZLEXCOUNT | ZLEXCOUNT key min max |
字典序区间统计 | ZLEXCOUNT users [A [Z |
符合条件的数量 | 用户ID范围统计 | 需所有成员分数相同 |
| ZRANGE | ZRANGE key start stop [WITHSCORES] |
- WITHSCORES:显示分数 - 支持负数索引 |
ZRANGE leaderboard 0 9 WITHSCORES |
成员列表(带分数) | 获取Top10数据 | 避免ZRANGE key 0 -1全量遍历 |
| ZRANGEBYLEX | ZRANGEBYLEX key min max [LIMIT] |
按字典序区间查询 | ZRANGEBYLEX users [A [D LIMIT 0 10 |
成员列表 | 名称前缀查询 | 必须所有成员分数相同 |
| ZRANGEBYSCORE | ZRANGEBYSCORE key min max [WITHSCORES] |
按分数区间查询 | ZRANGEBYSCORE leaderboard 800 1200 |
成员列表(带分数) | 筛选分数段玩家 | 支持+inf符号 |
| ZRANK | ZRANK key member |
获取升序排名 | ZRANK leaderboard "Alice" |
排名索引或nil |
查询玩家排名 | 同分数按字典序排序 |
| ZREM | ZREM key member [...] |
移除指定成员 | ZREM leaderboard "Bob" |
成功移除数量 | 清理过期数据 | 不存在的成员不计入结果 |
| ZREMRANGEBYLEX | ZREMRANGEBYLEX key min max |
按字典序区间删除 | ZREMRANGEBYLEX users [A [D |
被移除数量 | 批量删除用户 | 需所有成员分数相同 |
| ZREMRANGEBYRANK | ZREMRANGEBYRANK key start stop |
按索引区间删除 | ZREMRANGEBYRANK leaderboard 0 99 |
被移除数量 | 清理末尾成员 | 支持负数索引 |
| ZREMRANGEBYSCORE | ZREMRANGEBYSCORE key min max |
按分数区间删除 | ZREMRANGEBYSCORE leaderboard 0 500 |
被移除数量 | 清理低分用户 | 区间符号同ZRANGEBYSCORE |
| ZREVRANGE | ZREVRANGE key start stop [WITHSCORES] |
降序返回成员 | ZREVRANGE leaderboard 0 9 WITHSCORES |
成员列表(带分数) | 高分榜Top10 | 性能同ZRANGE |
| ZREVRANGEBYSCORE | ZREVRANGEBYSCORE key max min [...] |
参数顺序为max min | ZREVRANGEBYSCORE leaderboard 1200 800 |
成员列表(带分数) | 降序分数区间 | 分数高到低排序 |
| ZREVRANK | ZREVRANK key member |
获取降序排名 | ZREVRANK leaderboard "Alice" |
排名索引或nil |
逆序排名查询 | 同分数按字典序逆序 |
| ZSCORE | ZSCORE key member |
获取成员分数 | ZSCORE leaderboard "Alice" |
分数值或nil |
积分查询 | 返回值需转换数值类型 |
| ZUNIONSTORE | ZUNIONSTORE dest numkeys key [...] [WEIGHTS] [AGGREGATE] |
合并多集合数据 | ZUNIONSTORE result 2 A B |
结果集成员数量 | 排行榜合并 | 避免大集合直接计算 |
| ZSCAN | ZSCAN key cursor [MATCH] [COUNT] |
增量遍历成员和分数 | ZSCAN leaderboard 0 MATCH "user:*" |
新游标+成员列表 | 安全遍历大集合 | 非原子操作,数据可能变化 |
到这里一些基础的命令就已经掌握啦🎉,如果读者想要继续深入研究,可以再看看下面的命令~
为了加深理解,这里附一张图(图片来源:关于Redis核心数据结构与高性能原理_redis架构-CSDN博客)
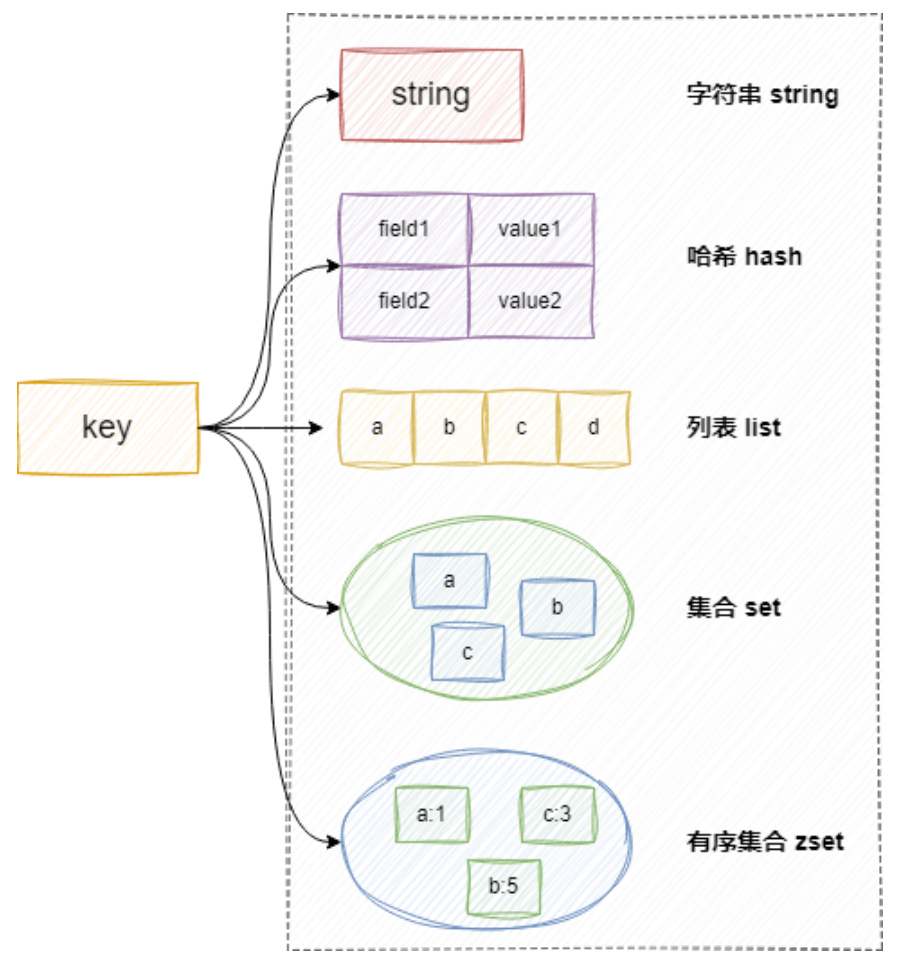
2.3.7 HyperLogLog 命令
| 命令 | 语法 | 参数说明 | 示例 | 返回值说明 | 典型场景 | 注意事项 |
|---|---|---|---|---|---|---|
| PFADD | PFADD key element [element ...] |
向HyperLogLog添加元素(用于基数统计) | PFADD uv:20231001 user1 user2 user1 |
1(基数变化)或0(无变化) | 独立访客统计(UV) | 重复元素不影响基数,误差率约0.81% |
| PFCOUNT | PFCOUNT key [key ...] |
返回基数估算值(支持多键合并统计) | PFCOUNT uv:20231001 uv:20231002 |
估算的基数(整数) | 合并多日UV统计 | 多键等价于先PFMERGE后计算,误差率累加 |
| PFMERGE | PFMERGE destkey sourcekey [...] |
合并多个HyperLogLog到目标键 | PFMERGE uv:total uv:20231001 uv:20231002 |
OK(成功) |
跨时段数据合并 | 合并后占用固定12KB内存,与数据量无关 |
2.3.8 Geo 命令
| 命令 | 语法 | 参数说明 | 示例 | 返回值说明 | 典型场景 | 注意事项 |
|---|---|---|---|---|---|---|
| GEOADD | GEOADD key [NX|XX] longitude latitude member [...] |
- NX:仅新增成员 - XX:仅更新成员 经度(-180~180) 纬度(-85.05~85.05) |
GEOADD shops 116.40 39.90 "store1" |
成功添加的成员数量 | 商家位置存储、POI标注 | 经纬度超范围返回错误 |
| GEOPOS | GEOPOS key member [...] |
查询成员坐标 | GEOPOS shops "store1" |
坐标数组或nil |
地图坐标展示 | 高并发场景建议使用缓存 |
| GEOHASH | GEOHASH key member [...] |
生成地理编码字符串 | GEOHASH shops "store1" |
Geohash字符串列表 | 第三方地图集成 | 存在精度损失可能 |
| GEODIST | GEODIST key member1 member2 [unit] |
单位: m(米)/km(千米) ft(英尺)/mi(英里) |
GEODIST shops "store1" "store2" km |
浮点距离或nil |
配送距离计算 | 成员不存在时返回nil |
| GEORADIUS |
GEORADIUS key lon lat radius unit
|
- WITHCOORD:返回坐标 - WITHDIST:返回距离 - COUNT:结果数量限制 |
GEORADIUS shops 116.40 39.90 5 km WITHDIST |
带附加信息的成员列表 | 附近商家搜索 | Redis 6.2+建议改用GEOSEARCH |
| GEORADIUSBYMEMBER |
GEORADIUSBYMEMBER key member radius unit
|
参数同GEORADIUS | GEORADIUSBYMEMBER shops "store1" 5 km |
带附加信息的成员列表 | 基于现有位置的范围查询 | 大范围查询可能阻塞服务 |
2.3.9 发布订阅命令
| 命令 | 语法 | 参数说明 | 示例 | 返回值说明 | 典型场景 | 注意事项 |
|---|---|---|---|---|---|---|
| PSUBSCRIBE | PSUBSCRIBE pattern [...] |
订阅Glob风格频道模式(如news.*) |
PSUBSCRIBE news.* chat.room* |
逐条返回订阅确认消息(含匹配模式) | 监听多个关联频道(话题分类) | 大量模式订阅增加服务端负载,限制模式复杂度 |
| PUBSUB | PUBSUB <subcommand> |
- CHANNELS [pattern] - NUMSUB [channel...] - NUMPAT |
PUBSUB CHANNELS news.*PUBSUB NUMSUB chat
|
子命令相关输出(如频道列表/数值统计) | 监控订阅量、调试消息分发 | NUMSUB需指定频道,NUMPAT返回全局模式订阅数 |
| PUBLISH | PUBLISH channel message |
向指定频道发送消息 | PUBLISH chat.room1 "Hello!" |
接收消息的客户端数量 | 实时通知(聊天室/系统告警) | 消息无持久化,建议内容≤1MB |
| PUNSUBSCRIBE | PUNSUBSCRIBE [pattern...] |
退订指定模式(无参数退订全部) | PUNSUBSCRIBE news.* |
逐条返回退订确认消息 | 动态调整订阅范围 | 退订不存在模式无副作用 |
| SUBSCRIBE | SUBSCRIBE channel [...] |
订阅明确命名的频道 | SUBSCRIBE news.sports weather |
逐条返回订阅确认消息(含频道名) | 精准接收特定频道消息 | 不支持模式匹配,单客户端可订阅数千频道 |
| UNSUBSCRIBE | UNSUBSCRIBE [channel...] |
退订指定频道(无参数退订全部) | UNSUBSCRIBE news.sports |
逐条返回退订确认消息 | 清理无效订阅 | 客户端断开自动退订所有频道 |
2.3.10 事务命令
| 命令 | 语法 | 参数说明 | 示例 | 返回值说明 | 典型场景 | 注意事项 |
|---|---|---|---|---|---|---|
| WATCH | WATCH key [...] |
监视键,事务执行前被修改则中断 | WATCH account:1001 |
OK |
乐观锁控制(如余额检查扣款) | 需在MULTI前调用,键被修改时事务返回nil |
| MULTI | MULTI |
标记事务开始 | MULTI |
OK |
开启事务块 | 命令进入队列,需EXEC提交执行 |
| EXEC | EXEC |
执行事务块内所有命令 | EXEC |
命令结果数组或nil | 原子性批量操作(如转账) | 被WATCH中断/语法错误时返回nil或部分失败 |
| DISCARD | DISCARD |
取消事务并清空队列 | DISCARD |
OK |
主动放弃无效操作 | 自动解除所有WATCH监视的键 |
| UNWATCH | UNWATCH |
解除所有被监视的键 | UNWATCH |
OK |
手动释放监视锁 | 事务提交/取消后自动执行,一般无需手动调用 |
2.3.11 脚本命令
| 命令 | 语法 | 参数说明 | 示例 | 返回值说明 | 典型场景 | 注意事项 |
|---|---|---|---|---|---|---|
| SCRIPT KILL | SCRIPT KILL |
强制终止正在运行的Lua脚本 | SCRIPT KILL |
OK或错误信息 |
终止死循环脚本 | 仅对只读脚本生效(未执行写操作时) |
| SCRIPT LOAD | SCRIPT LOAD "script" |
预加载脚本到缓存,返回SHA1哈希 | SCRIPT LOAD "return 'hello'" |
SHA1哈希(如"a5a069e2") | 高频脚本性能优化 | 重启后缓存失效,需持久化存储SHA1 |
| EVAL |
EVAL "script" numkeys key [...]
|
- numkeys: 键数量 - key: 键名列表 - arg: 额外参数 |
EVAL "return {KEYS[1],ARGV[1]}" 1 user:1001 age |
脚本返回结果(任意类型) | 原子性操作(库存扣减+日志) | 默认5秒超时,长脚本需用redis.replicate_commands() |
| EVALSHA |
EVALSHA sha1 numkeys key [...]
|
参数同EVAL | EVALSHA a5a069e2 0 |
同EVAL或NOSCRIPT错误 |
减少网络传输开销 | 脚本未缓存返回NOSCRIPT错误 |
| SCRIPT EXISTS | SCRIPT EXISTS sha1 [...] |
检查脚本缓存状态 | SCRIPT EXISTS a5a069e2 |
数组(1存在/0不存在) | 验证脚本可用性 | 结果仅反映当前缓存状态 |
| SCRIPT FLUSH | SCRIPT FLUSH [ASYNC/SYNC] |
清空脚本缓存(Redis 7.0+支持ASYNC) | SCRIPT FLUSH |
OK |
脚本更新后重新加载 | 生产环境慎用!清空后需重新LOAD |
补充说明:
Lua 脚本特性:
原子性:脚本执行期间不会被其他命令中断,适合复杂事务操作。
性能优化:使用
EVALSHA减少网络传输,结合SCRIPT LOAD预加载高频脚本。典型场景:
原子扣减库存:
local stock = redis.call('GET', KEYS[1]) if tonumber(stock) >= tonumber(ARGV[1]) then redis.call('DECRBY', KEYS[1], ARGV[1]) return "SUCCESS" else return "OUT_OF_STOCK" end批量删除匹配键:
local keys = redis.call('KEYS', ARGV[1]) for i=1, #keys do redis.call('DEL', keys[i]) end return keys错误处理:
脚本语法错误会在加载或执行时返回错误信息。
运行时错误(如对字符串执行
INCR)会中断脚本,但 不会回滚已执行的操作。安全限制:
禁用高危操作(如
os.execute()),仅允许 Redis 命令和 Lua 标准库。可通过
redis.set_repl(redis.REPL_NONE)控制脚本是否复制到从节点。超时管理:
默认 5 秒超时,超时后自动终止脚本(可通过
redis.config SET lua-time-limit 10000调整)。长脚本建议拆分为多个小脚本或使用
redis.replicate_commands()分阶段执行。
2.3.12 连接命令
| 命令 | 语法 | 参数说明 | 示例 | 返回值说明 | 典型场景 | 注意事项 |
|---|---|---|---|---|---|---|
| AUTH | AUTH password |
验证客户端密码与服务端是否匹配 | AUTH mySecurePassword123 |
OK 或错误信息 |
安全连接Redis服务 | 密码错误返回(error) WRONGPASS;未设置密码无需验证 |
| ECHO | ECHO message |
返回输入的字符串 | ECHO "Hello Redis!" |
原样返回输入字符串 | 网络连通性测试 | 避免传输敏感信息,可能被日志记录 |
| PING | PING [message] |
可选携带自定义消息 |
PINGPING "health_check"
|
PONG 或指定消息 |
服务存活检测 | 未响应PONG可能表示服务宕机 |
| QUIT | QUIT |
关闭当前连接 | QUIT |
OK |
安全断开连接 | 连接池工具通常自动处理,无需手动调用 |
| SELECT | SELECT index |
切换数据库索引(0-15) | SELECT 1 |
OK |
多业务数据隔离 | 集群模式不支持,频繁切换影响性能 |
2.3.13 管理 redis 服务相关命令
| 命令 | 语法 | 参数说明 | 示例 | 返回值说明 | 典型场景 | 注意事项 |
|---|---|---|---|---|---|---|
| BGREWRITEAOF | BGREWRITEAOF |
异步重写AOF文件以优化体积 | BGREWRITEAOF |
Background append only file rewrite started | AOF持久化优化 | 重写期间磁盘I/O增加,建议低峰期操作 |
| BGSAVE | BGSAVE |
后台异步保存数据库快照到RDB文件 | BGSAVE |
Background saving started | 手动触发持久化备份 | 避免频繁调用,可能导致内存占用激增 |
| CLIENT | CLIENT <subcommand> |
- LIST:列出连接 - KILL <ip:port>:关闭连接 - SETNAME:设置连接名称 |
CLIENT LISTCLIENT KILL 127.0.0.1:6352
|
子命令相关输出(如连接列表) | 调试连接问题 | CLIENT KILL可能中断业务 |
| CLIENT GETNAME | CLIENT GETNAME |
获取当前连接名称 | CLIENT GETNAME |
连接名称或nil |
追踪客户端来源 | 需先用CLIENT SETNAME设置 |
| CLIENT PAUSE | CLIENT PAUSE milliseconds |
暂停客户端命令执行 | CLIENT PAUSE 5000 |
OK |
主从切换数据同步 | 最长可暂停数分钟,超时后自动恢复 |
| CLIENT SETNAME | CLIENT SETNAME connection-name |
设置连接名称 | CLIENT SETNAME "admin_conn" |
OK |
标识管理连接 | 名称需为字符串,不支持特殊字符 |
| CLUSTER SLOTS | CLUSTER SLOTS |
返回集群槽位分配信息 | CLUSTER SLOTS |
槽位分布数组或错误 | 集群运维监控 | 非集群模式返回ERR This instance has cluster support disabled |
| COMMAND | COMMAND |
列出所有命令详细信息 | COMMAND |
命令详情数组 | 开发调试 | 输出信息量大,建议结合COMMAND INFO |
| COMMAND COUNT | COMMAND COUNT |
返回命令总数 | COMMAND COUNT |
整数(如234) | 版本兼容检查 | 不同Redis版本总数不同 |
| COMMAND GETKEYS | COMMAND GETKEYS <full-command> |
解析命令涉及的键 | COMMAND GETKEYS MSET user:1001 "Alice" user:1002 "Bob" |
键列表(如["user:1001","user:1002"]) | 键提取工具开发 | 仅支持部分命令(如SET、MSET) |
| TIME | TIME |
返回服务器当前时间戳 | TIME |
数组(如["1696118400","123456"]) | 分布式时间同步 | 非原子操作,网络延迟影响精度 |
| COMMAND INFO | COMMAND INFO <command-name> [...] |
返回命令元数据 | COMMAND INFO GET SET |
命令详情数组 | 权限管理 | 支持批量查询多个命令 |
| CONFIG GET | CONFIG GET <parameter> |
获取配置参数值 | CONFIG GET maxmemory |
键值对列表(如["maxmemory","0"]) | 运行时配置检查 | 使用*通配符获取所有参数 |
| CONFIG REWRITE | CONFIG REWRITE |
持久化配置到redis.conf | CONFIG REWRITE |
OK或错误信息 |
动态配置持久化 | 需Redis有写文件权限 |
| CONFIG SET | CONFIG SET <parameter> <value> |
动态修改配置参数 | CONFIG SET maxmemory 2gb |
OK或错误信息 |
热更新配置 | 部分参数需重启生效(如daemonize) |
| CONFIG RESETSTAT | CONFIG RESETSTAT |
重置统计信息 | CONFIG RESETSTAT |
OK |
性能测试清零指标 | 仅重置计数器,不影响业务数据 |
| DBSIZE | DBSIZE |
返回当前数据库键总数 | DBSIZE |
整数(如100) | 监控数据库容量 | O(1)时间复杂度 |
| DEBUG OBJECT | DEBUG OBJECT <key> |
返回键存储信息 | DEBUG OBJECT user:1001 |
序列化信息或错误 | 数据存储调试 | 生产环境慎用!可能暴露敏感信息 |
| DEBUG SEGFAULT | DEBUG SEGFAULT |
触发服务崩溃 | DEBUG SEGFAULT |
无返回值 | 测试崩溃恢复 | 仅用于测试环境!导致服务不可用 |
| FLUSHALL | FLUSHALL [ASYNC] |
删除所有数据库的键 | FLUSHALL ASYNC |
OK |
清空测试环境数据 | 高危操作!数据不可逆删除 |
| FLUSHDB | FLUSHDB [ASYNC] |
删除当前数据库的键 | FLUSHDB |
OK |
清理当前数据库 | 结合SELECT切换数据库使用 |
| INFO | INFO [section] |
返回服务器状态信息 | INFO memory |
多行文本状态报告 | 监控服务器健康 | 兼容Prometheus等监控工具 |
| LASTSAVE | LASTSAVE |
返回最近持久化时间戳 | LASTSAVE |
整数(如1696118400) | 验证备份完成 | 时间戳单位为秒 |
| MONITOR | MONITOR |
实时打印所有命令 | MONITOR |
持续输出命令日志 | 调试命令顺序 | 生产环境慎用!高并发可能阻塞服务 |
| ROLE | ROLE |
返回主从角色信息 | ROLE |
角色详情数组 | 主从复制监控 | 主节点返回复制偏移量,从节点返回主节点信息 |
| SAVE | SAVE |
同步保存到RDB文件 | SAVE |
OK |
强制立即持久化 | 阻塞主线程,生产环境优先用BGSAVE |
| SHUTDOWN | SHUTDOWN [SAVE|NOSAVE] |
关闭服务器 | SHUTDOWN SAVE |
无返回值 | 安全停机维护 | NOSAVE强制关闭不保存数据 |
| SLAVEOF | SLAVEOF <host> <port> |
设置主从复制或终止复制 | SLAVEOF 127.0.0.1 6380 |
OK |
主从切换 | 建议使用REPLICAOF(Redis 5.0+) |
| SLOWLOG | SLOWLOG <subcommand> |
- GET [n]:获取慢日志 - LEN:日志数量 - RESET:清空日志 |
SLOWLOG GET 5 |
子命令相关输出 | 分析性能瓶颈 | 需通过CONFIG SET调整阈值 |
| SYNC | SYNC |
主从复制内部命令 | SYNC |
二进制同步数据流 | 主从复制调试 | 用户无需直接调用! |
2.4 各数据结构的应用场景
这个表格在 2.1.3 已经展示过了,这里再 ctrl + v 一下
| 数据结构 | 特性 | 应用场景 | 示例命令 |
|---|---|---|---|
| 字符串(String) | 最大 512MB,支持二进制数据 | 缓存、分布式锁 | SET user:1001 "Alice" EX 3600 |
| 哈希(Hash) | 字段级操作,内存高效(ziplist 编码) |
存储对象属性 | HSET product:2001 price 599 stock 50 |
| 有序集合(Sorted Set) | 按分数排序,支持范围查询 | 排行榜、延迟队列 | ZADD leaderboard 1500 "playerA" |
| 列表(List) | 双向链表,支持阻塞弹出(BLPOP) |
消息队列、最新动态 | LPUSH orders "order_1001" |
| 集合(Set) | 无序唯一元素 | 标签存储、共同好友 | SADD user:1001:tags "科技" "编程" |
| 位图(Bitmap) | 位操作 | 日活统计、签到记录 | SETBIT active:20231001 10000001 1 |
| HyperLogLog | 基数统计,误差 <1%(如 12KB 内存统计 1.8 亿用户) | UV 统计 | PFADD uv:20231001 "user1001" |
| 地理空间(GEO) | 存储经纬度,支持范围搜索 | 附近的人、商家推荐 | GEOADD cities 116.40 39.90 "北京" |
三、Redis架构与核心原理
3.1 Redis 整体架构
Redis 的架构设计围绕 高性能、高可用、数据持久化 展开,其核心模块与交互关系如下:
客户端请求
│
↓
网络层(I/O 多路复用 + 事件驱动)
│
↓
单线程命令处理器(内存操作 + 高效数据结构)
│
↓
持久化模块(RDB/AOF)
│
↓
内存管理模块(jemalloc 分配 + 淘汰策略) 核心组件说明:
网络层:基于 Reactor 模式的事件驱动模型,负责接收和分发客户端请求。
单线程处理器:执行所有命令(GET/SET 等),保证原子性,直接操作内存数据。
持久化模块:异步或同步将内存数据持久化到磁盘(RDB 快照、AOF 日志)。
内存管理模块:控制内存分配与回收,防止 OOM(Out-Of-Memory)错误。
3.2 Redis 核心原理
3.2.1 异步 I/O 与事件驱动:Reactor 模式的实现细节
Redis 的网络层是单线程高并发的核心支撑,其设计灵感来自 Nginx 和 Node.js。Redis 基于 Reactor 模式 实现高并发网络处理,关键步骤:
事件注册:主线程通过
epoll监听客户端 Socket 的可读事件。事件监听:
epoll_wait阻塞等待就绪事件,最大化 CPU 利用率。事件处理:主线程顺序处理请求,执行内存操作并生成响应。
非阻塞回写:结果写入 Socket 缓冲区,由操作系统异步返回客户端。
Redis 6.0+ 多线程优化:
读写分离:网络 I/O 由子线程处理,主线程专注命令执行(配置示例)
io-threads 4 # 启用 4 个 I/O 线程
io-threads-do-reads yes性能提升:吞吐量提升 2~3 倍,适用于 10万级并发连接场景。
3.2.2 单线程模型:极简设计的性能密码
Redis 的 单线程模型 是其设计的核心特征之一,尤其在 6.0 版本之前,所有客户端请求的 命令执行 和 网络 I/O 均由单个线程处理。这一看似“反直觉”的设计,却成就了 Redis 的极致性能:
无锁竞争:多线程架构中,线程间需要通过锁机制(如互斥锁、信号量)协调对共享资源的访问,而锁的争用会导致性能损耗。Redis 单线程直接操作内存数据,天然无锁,避免了锁的开销和死锁风险。
零上下文切换:多线程频繁切换执行上下文(Context Switching)会消耗 CPU 资源(一次切换约 1~2μs)。单线程无需切换,CPU 缓存命中率更高(指令和数据缓存在 L1/L2),执行效率大幅提升。
纯内存操作:Redis 数据存储在内存中,读写速度在 100 纳秒级(机械磁盘访问延迟约 10 毫秒)。即使单线程处理,也能轻松达到 10万级 QPS(每秒查询数)。
高效数据结构:Redis 内置优化数据结构,如 跳表(ZSET 的 O(log N) 查询)、压缩列表(Hash/List 的紧凑存储),减少计算复杂度。对比传统数据库的 B+ 树,跳表实现更简单且无磁盘寻址开销。
但单线程模型必然存在局限性:
CPU 利用率瓶颈:单线程无法充分利用多核 CPU。解决方案:需通过 分片集群(部署多个 Redis 实例)横向扩展。
长命令阻塞:例如
KEYS *扫描全库或处理大 Value 时,后续请求会被阻塞。解决方案:避免使用阻塞命令,用SCAN代替KEYS,或升级 Redis 6.0+ 开启多线程 I/O。
3.2.3 持久化机制:数据可靠性的三重保障
Redis 的持久化机制是内存数据落地的关键,需在性能与可靠性间权衡。
1️⃣RDB(快照)深度解析
生成原理:
写时复制(Copy-On-Write):
BGSAVE创建子进程,共享父进程内存页,仅在数据修改时复制内存页。内存开销:若父进程在 RDB 生成期间修改 50% 的内存,子进程需复制 50% 的内存,可能导致 OOM。
进阶配置:
禁用自动保存:在容器化环境中,手动触发 RDB 生成以避免资源争抢。
save ""压缩优化:启用 RDB 文件压缩(默认开启)。
rdbcompression yes rdbchecksum yes
2️⃣AOF(追加日志)高级策略
重写机制(AOF Rewrite):
触发条件:AOF 文件大小增长超过 100%(
auto-aof-rewrite-percentage 100)。实现原理:
创建子进程遍历数据库生成当前数据的 AOF 命令。
主进程继续处理请求,将新命令写入 AOF 缓冲区和重写缓冲区。
子进程完成后,主进程将重写缓冲区命令追加到新 AOF 文件。
性能调优:
AOF 缓冲区大小:调整
aof-rewrite-buffer-size避免频繁刷盘。操作系统缓存:使用
everysec策略平衡性能与安全。
3️⃣混合持久化的工程实践
文件结构:
[RDB 数据块] + [AOF 命令流]恢复流程:
加载 RDB 部分(快速恢复基础数据)。
重放后续 AOF 命令(补充增量更新)。
适用场景:
高可靠性要求:金融交易日志。
快速恢复需求:大规模缓存预热。
3.2.4 内存管理:资源管控的艺术
Redis 的内存管理策略直接影响服务稳定性与性能。
1️⃣内存分配器(jemalloc)
核心优势:
多级内存池:将内存划分为不同大小的区域(Arena),减少碎片。
线程本地缓存(TLS):每个线程独立管理内存分配,避免全局锁竞争。
碎片整理:
activedefrag yes # 启用自动碎片整理 active-defrag-ignore-bytes 100mb # 碎片超过 100MB 时触发 active-defrag-threshold-lower 10 # 碎片率超过 10% 时触发
2️⃣淘汰策略
LRU 近似算法:
Redis 随机采样 5 个 Key,淘汰最久未访问的 Key。可通过maxmemory-samples 10提高精度。LFU 频率统计:
使用 Morris 计数器算法,8 位存储访问频率(0~255),衰减周期通过lfu-decay-time配置。
config set lfu-log-factor 10 # 控制计数器增长速率
config set lfu-decay-time 60 # 每分钟衰减一次计数器3️⃣内存优化技巧
压缩列表调优:
list-max-ziplist-size -2 # 列表元素数 ≤512 时启用压缩列表 zset-max-ziplist-entries 128 # 有序集合元素数 ≤128 时启用压缩列表Bash短结构优化:
set-max-intset-entries 512 # 集合元素全为整数且 ≤512 时使用 intset共享对象池:
适用对象:小整数(0~9999)和长度 ≤39 字节的字符串。
风险提示:误用可能导致内存泄漏(需通过
OBJECT REFCOUNT监控引用计数)。
✒️实践建议:
生产环境启用混合持久化,并定期验证备份文件。
使用
redis-cli --bigkeys识别大 Key,优化压缩列表参数。监控内存碎片率(
INFO memory),适时触发自动整理。
四、高可用与扩展
4.1 主从复制(Replication)架构设计
Redis 主从复制是构建高可用系统的核心机制,其核心逻辑是将主节点(Master)的数据实时同步到从节点(Slave),确保多个副本间数据的一致性。通过 数据冗余 和 读写分离 实现以下核心目标:
数据备份:从节点作为主节点的镜像,防止数据丢失。
负载均衡:从节点分担读请求,提升系统吞吐量。
故障恢复:主节点故障时,从节点可快速接管服务。
架构特点:
一主多从:一个主节点(Master)可连接多个从节点(Slave),从节点仅处理读请求,主节点处理写请求。
异步复制:主节点处理写操作后立即响应客户端,数据同步通过后台线程异步完成。
数据最终一致性:网络延迟可能导致从节点数据短暂落后,但最终会与主节点一致。
4.1.1 同步流程:全量复制与增量复制
1️⃣全量复制(Full Resynchronization)
适用场景:从节点首次连接主节点;主从节点数据差异过大(如断线时间过长,复制积压缓冲区数据被覆盖)。
全量复制流程:
建立连接与协商同步:从节点发送
PSYNC ? -1命令,请求全量同步。主节点响应FULLRESYNC <runid> <offset>,传递自身运行 ID(runid)和当前复制偏移量(offset)。RDB 快照生成与传输:主节点执行
BGSAVE生成 RDB 文件,期间新写入命令存入 复制缓冲区(Replication Buffer)。RDB 文件通过 Socket 发送至从节点,从节点清空旧数据并加载 RDB。增量数据同步:主节点将复制缓冲区中的增量命令发送给从节点,确保数据完全一致。
流程图解:
[从节点] --PSYNC--> [主节点]
[主节点] --FULLRESYNC--> [从节点]
[主节点] --BGSAVE生成RDB--> [磁盘/Socket]
[从节点] --加载RDB--> [数据同步完成]
[主节点] --发送增量命令--> [从节点] ✒️技术细节与优化:
传输模式选择:磁盘模式(默认),RDB 文件先写入磁盘再传输,适合大内存实例。无盘模式:RDB 数据直接写入从节点 Socket,减少磁盘 I/O 开销(需配置
repl-diskless-sync yes)。性能瓶颈规避:
BGSAVE的fork()操作可能阻塞主线程(尤其是内存超过 10GB 的实例),建议主节点内存控制在 10GB 以内。
2️⃣增量复制(Partial Resynchronization)
适用场景:主从短暂断线后重连,且复制积压缓冲区(Repl Backlog Buffer)包含断线期间的增量数据。
增量复制流程:
断线重连:从节点发送
PSYNC <runid> <offset>,携带主节点 runid 和最后接收的 offset。主节点校验:若 runid 匹配且 offset 在复制积压缓冲区内,返回
CONTINUE并发送增量数据。否则触发全量复制。
✒️增量复制优化:
心跳间隔调整:默认 10 秒,缩短至 1 秒以加快断线检测:
repl-ping-slave-period 1 # 心跳间隔设为 1 秒缓冲区溢出处理:若
repl_backlog_histlen接近repl-backlog-size,需扩容缓冲区。
4.1.2 读写分离与数据一致性
1️⃣读写分离实现方案
客户端配置示例(Java + Jedis):
// 主节点写连接池
JedisPool masterPool = new JedisPool("master-ip", 6379);
// 从节点读连接池列表(负载均衡)
List<JedisPool> slavePools = Arrays.asList(
new JedisPool("slave1-ip", 6380),
new JedisPool("slave2-ip", 6381)
);
// 随机选择从节点
Jedis slave = slavePools.get(new Random().nextInt(slavePools.size())).getResource();
String value = slave.get("key"); 负载均衡策略:
随机轮询:简单但可能导致负载不均。
权重分配:根据从节点硬件配置(CPU、内存)分配权重。
一致性哈希:减少节点变化对路由的影响,适合动态扩容场景。
2️⃣数据一致性挑战与解决方案
问题根源:
异步复制延迟:主节点写入到从节点同步存在毫秒级延迟,从节点可能读取旧数据。
网络分区(脑裂):主节点与从节点断开连接,导致多主写入数据冲突。
解决方案:
强制读主节点:关键业务读请求直接路由至主节点,配置从节点拒绝读请求(
replica-read-only no):Jedis master = masterPool.getResource(); String value = master.get("order:1001");半同步复制(Redis 7.0+):主节点等待至少 N 个从节点确认写入后响应客户端:
min-replicas-to-write 1 # 至少 1 个从节点确认 min-replicas-max-lag 10 # 从节点延迟不超过 10 秒客户端一致性校验:记录写入时间戳,从节点仅返回时间戳不小于该值的数据(需应用层逻辑实现)。
4.1.3 故障切换与手动恢复
1️⃣动故障切换(基于哨兵)
流程详解:
主观下线(SDOWN):单个哨兵检测到主节点无响应(默认 30 秒超时)。
客观下线(ODOWN):超过半数哨兵确认主节点故障(需配置
quorum=2)。领导者选举:哨兵集群基于 Raft 协议选举 Leader。
从节点晋升:选择数据最新的从节点(优先级最高、复制偏移量最大)为新主节点。
哨兵配置示例:
sentinel monitor mymaster 172.16.12.10 6379 2
sentinel down-after-milliseconds mymaster 5000 # 5秒无响应判定下线
sentinel failover-timeout mymaster 60000 # 故障转移超时60秒 2️⃣手动恢复操作指南
适用场景:
哨兵集群故障或配置错误导致自动切换失效。
数据误操作需回滚至特定时间点。
操作步骤:
强制切换主节点:
# 在从节点执行 SLAVEOF NO ONE # 提升为独立主节点数据回滚:从备份文件恢复数据:
# 加载RDB备份 redis-cli -h new-master-ip --pipe < dump.rdb重建主从关系:
# 其他从节点指向新主节点 SLAVEOF new-master-ip 6379
风险控制与验证:
数据校验:使用
redis-check-rdb和redis-check-aof验证备份文件完整性。灰度切换:先迁移部分从节点观察稳定性,再全面切换。
✒️实践建议:
Redis 主从复制通过 全量/增量同步机制 实现数据冗余,结合 读写分离 显著提升读性能,但需在 数据一致性 与 系统可用性 间谨慎权衡。故障恢复依赖哨兵自动化或人工干预,生产环境中需构建完善的监控、备份与演练体系。
4.2 哨兵(Sentinel)架构设计
Redis Sentinel 是 Redis 官方提供的高可用解决方案,用于 自动化监控主从集群状态、故障检测 和 故障转移。其核心目标是在主节点故障时,自动选举新主节点并通知客户端,实现服务无感知切换。
核心功能:
持续监控:检查主节点和从节点是否正常运行。
自动故障转移:主节点故障时,选举新主节点并更新配置。
客户端通知:向客户端推送新主节点地址,实现透明切换。
配置中心:存储集群拓扑信息,提供动态配置管理。
架构特点:
去中心化:哨兵集群由多个节点组成,通过 Gossip 协议交换状态,无单点故障。
多数派决策:故障判定和切换需超过半数哨兵节点达成共识。
事件驱动:基于发布/订阅模式,实时推送节点状态变更。
4.2.1 哨兵集群的监控与自动故障转移
1️⃣监控机制
哨兵通过周期性心跳检测和命令响应监控节点健康状态,具体流程如下:
主观下线(SDOWN):单个哨兵节点通过
PING命令检测主节点无响应(默认超时时间 30 秒)。若超时未收到响应,该哨兵标记主节点为“主观下线”。客观下线(ODOWN):哨兵节点通过
SENTINEL is-master-down-by-addr命令向其他哨兵确认主节点状态。若超过半数哨兵(由quorum参数控制)确认主节点故障,触发客观下线。
监控频率配置:
sentinel down-after-milliseconds mymaster 5000 # 5秒无响应判定主观下线2️⃣自动故障转移流程
领导者选举:
哨兵集群基于 Raft 算法 选举 Leader,由 Leader 执行故障转移。
选举条件:获得半数以上哨兵投票且优先级最高(配置
sentinel leader-epoch)。
从节点晋升:
选择优先级最高(
slave-priority)、复制偏移量最大的从节点为新主节点。若优先级相同,选择 Run ID 字典序最小的节点。
集群拓扑更新:
新主节点执行
SLAVEOF NO ONE脱离从属关系。其他从节点更新配置指向新主节点。
客户端通过订阅
+switch-master事件获取新主节点地址。
完整流程示意图:
主节点故障 → 哨兵主观下线 → 多数派确认客观下线 → 选举Leader → 选择新主节点 → 更新拓扑 → 客户端切换4.2.2 配置示例与选举机制
哨兵集群配置示例,配置文件(sentinel.conf):
# 监控主节点 mymaster,IP 172.16.12.10:6379,quorum=2
sentinel monitor mymaster 172.16.12.10 6379 2
# 5秒无响应判定主观下线
sentinel down-after-milliseconds mymaster 5000
# 故障转移超时60秒
sentinel failover-timeout mymaster 60000
# 故障转移期间,允许最大1个从节点同步延迟10秒
sentinel parallel-syncs mymaster 1
sentinel auth-pass mymaster MySecurePassword # 主节点密码关键参数解析:
quorum:触发客观下线所需的最小哨兵投票数(通常为N/2 + 1,N 是哨兵总数)。parallel-syncs:故障转移后,允许同时从新主节点同步数据的从节点数量(避免主节点带宽过载)。
哨兵集群基于 Raft 算法协议,实现细节如下:
Term(任期):每次选举递增任期号,确保同一任期只有一个 Leader。
投票规则:哨兵节点仅投票给任期号更大或日志更新的候选者。每个任期每个哨兵只能投一票。
心跳机制:Leader 定期发送心跳包维持领导权,超时未收到心跳则触发新选举。
4.2.3 脑裂问题与解决方案
脑裂问题场景描述:
网络分区导致主节点与部分哨兵、客户端隔离,另一部分哨兵选举出新主节点。
结果:两个主节点同时存在,客户端可能向不同主节点写入数据,引发数据冲突。
典型案例:
主节点所在机房网络中断,剩余哨兵选举新主节点,但原主节点仍可写入数据。
解决方案:
合理设置 quorum 和超时时间:
quorum应大于哨兵总数的一半(如 3 节点集群设置quorum=2)。调大down-after-milliseconds减少误判(需权衡故障恢复速度)。限制主节点写入条件:当主节点无法满足条件时,自动拒绝写请求,避免数据分裂。
min-slaves-to-write 1 # 主节点需至少同步1个从节点才能写入 min-slaves-max-lag 10 # 从节点延迟不超过10秒客户端双重验证:写入前检查主节点身份是否与哨兵公布的地址一致。示例代码(Java):
JedisSentinelPool pool = new JedisSentinelPool("mymaster", sentinels); Jedis master = pool.getResource(); if (master.info("replication").contains("role:master")) { master.set("key", "value"); // 确认是合法主节点才写入 }数据修复与人工介入:网络恢复后,对比两个主节点的 AOF/RDB 文件,手动合并冲突数据。使用
redis-cli --cluster fix修复集群状态。
✒️实践建议:Redis Sentinel 通过 自动化监控、多数派决策和 Raft 选举机制 实现高可用,但其核心挑战在于 脑裂防控 和 数据一致性保障。生产环境中需结合合理配置、客户端验证和定期演练,确保故障切换的可靠性与数据安全。
4.3 集群(Cluster)架构设计
Redis Cluster 是 Redis 官方提供的 分布式高可用解决方案,旨在突破单机性能瓶颈,实现 数据分片、自动故障转移 和 水平扩展。其核心目标包括:
数据分布式存储:将数据分散到多个节点,突破单机内存限制。
高可用性:节点故障时自动切换,保障服务连续性。
无缝扩展:动态增删节点,支持业务弹性增长。
4.3.1 数据分片(Hash Slot)
Redis Cluster 采用 虚拟哈希槽(Hash Slot) 机制实现分布式存储,将数据分散到多个节点,解决单机内存限制与负载均衡问题。
1️⃣分片原理与实现
槽位分配:
集群预分 16384 个槽,每个键通过CRC16(key) % 16384计算所属槽位。槽位按需分配给不同节点,例如:节点A:0-5460 | 节点B:5461-10922 | 节点C:10923-16383这种设计使数据分布均匀,避免单点热点问题。
动态扩缩容:
添加新节点时,仅需迁移部分槽位(而非全量数据),例如从节点A迁移1000个槽至节点D,服务不中断。
2️⃣为何选择16384个槽?
内存开销优化:每个节点维护槽位映射仅需 2KB(若用65536槽则需8KB)。
网络效率:心跳包携带槽位信息时,16384槽压缩后仅占2KB,减少带宽消耗。
扩展性平衡:支持最多约1000个节点(每个节点管理约16个槽),满足多数场景。
4.3.2 节点通信(Gossip协议)
Redis Cluster 通过 Gossip协议 实现去中心化通信,保障节点状态同步与故障检测。
Gossip协议核心机制
消息类型:
PING/PONG:周期性发送(默认每秒1次),交换节点状态、槽位信息与故障列表。MEET:邀请新节点加入集群。FAIL:广播节点永久下线,触发故障转移。
故障检测流程:
主观下线(PFAIL):单个节点检测到目标节点无响应(默认15秒超时)。
客观下线(FAIL):半数以上节点确认故障,触发自动故障转移。
优势与局限:
去中心化:无单点故障,适合大规模动态集群。
最终一致性:状态同步存在秒级延迟,不适用于强一致性场景。
4.3.3 集群搭建与扩容(Resharding)
1️⃣集群搭建步骤
节点配置:
cluster-enabled yes # 启用集群模式 cluster-node-timeout 15000 # 节点超时时间(毫秒)初始化集群(6节点示例):
redis-cli --cluster create 192.168.1.10:7001 192.168.1.10:7002 ... \ --cluster-replicas 1 # 每个主节点配1个从节点集群自动分配槽位并建立主从关系。
2️⃣扩容操作
添加新节点:
redis-cli --cluster add-node 新节点IP:端口 现有节点IP:端口迁移槽位:
redis-cli --cluster reshard 新节点IP:端口 --cluster-from 原节点ID --cluster-slots 1000原子迁移:通过
MIGRATE命令逐个迁移键值,阻塞时间极短。
验证均衡性:
redis-cli --cluster check 现有节点IP:端口
注意事项:
性能影响:迁移期间网络带宽与CPU占用较高,建议低峰期操作。
槽位均匀性:确保扩容后各节点槽数偏差≤20%。
4.3.4 客户端路由(MOVED/ASK重定向)
Redis Cluster 要求客户端处理重定向逻辑,实现透明路由。
1️⃣MOVED重定向
触发场景:请求的键所属槽不在当前节点。
响应格式:
MOVED <slot> <目标节点IP:端口>。客户端处理:
更新本地槽位映射表(如 JedisCluster 的
slotCache)。后续请求直接发送至目标节点。
2️⃣ASK重定向
触发场景:槽位迁移过程中,原节点仅存部分数据。
响应格式:
ASK <slot> <目标节点IP:端口>。客户端处理:
向目标节点发送
ASKING命令,临时绕过槽校验。重发请求,仅本次生效,不更新本地缓存。
优化策略:
本地缓存槽位映射:减少重定向次数(如 Lettuce、Jedis 已内置支持)。
智能路由:客户端首次请求可能重定向,后续直接命中目标节点。
五、高级特性与扩展功能
5.1 事务与Lua脚本
Redis 事务提供了一种将多个命令打包执行的机制,但其设计目标并非严格意义上的原子性,需谨慎使用。
5.1.1 事务(MULTI/EXEC)
Redis 事务提供了一种将多个命令打包执行的机制,但其设计目标并非严格意义上的原子性,需谨慎使用。
1️⃣事务执行流程:
开启事务:客户端发送
MULTI命令,Redis 进入事务模式。命令入队:后续命令(如
SET,INCR)暂存到队列,不立即执行。提交执行:发送
EXEC命令后,Redis 按顺序执行队列中的所有命令。取消事务:
DISCARD命令清空队列并退出事务模式。
示例代码:
MULTI SET user:1001:balance 500 INCR user:1001:login_count EXEC2️⃣事务的局限性
非原子性:若事务执行期间 Redis 崩溃,可能导致部分命令未执行(无回滚机制)。事务中的某个命令执行失败(如语法错误),其他命令仍会继续执行。示例:
MULTI SET key1 "value1" INCRBY key1 10 # 错误:对字符串类型执行INCRBY EXEC # 输出:1) OK, 2) (error) ERR value is not an integer无隔离性:事务执行期间,其他客户端的命令可能插入执行(Redis 单线程特性)。
乐观锁依赖:需配合
WATCH命令实现乐观锁,但复杂度较高。
✒️实践建议:
简单场景:非严格原子性操作(如批量更新计数器)。
避免场景:需要强一致性的事务(如转账操作)。
5.1.2 Lua 脚本
Lua 脚本是 Redis 实现原子操作的核心方案,弥补了事务的局限性。
1️⃣Lua 脚本特性
原子性:脚本执行期间独占 Redis 线程,其他命令无法插入。
高性能:单次网络传输:脚本一次性发送,减少网络开销。脚本缓存:通过
EVALSHA执行缓存的脚本,节省带宽。灵活性:支持条件判断、循环、错误处理等复杂逻辑。
示例代码(限流):
-- KEYS[1]: 限流Key(如 rate_limit:api:1001)
-- ARGV[1]: 时间窗口(秒)
-- ARGV[2]: 最大请求数
local current = redis.call('GET', KEYS[1])
if current and tonumber(current) >= tonumber(ARGV[2]) then
return 0 -- 超出限制
else
redis.call('INCR', KEYS[1])
redis.call('EXPIRE', KEYS[1], ARGV[1])
return 1 -- 允许请求
end执行命令:
EVAL "脚本内容" 1 rate_limit:api:1001 60 1002️⃣Lua 脚本 vs 事务
| 特性 | Lua 脚本 | 事务(MULTI/EXEC) |
|---|---|---|
| 原子性 | 严格原子性(全成功/全失败) | 非原子性(运行时错误可能部分失败) |
| 网络开销 | 单次传输脚本,支持SHA缓存复用 | 多次往返(命令逐条入队+EXEC提交) |
| 错误处理 |
- 语法错误:脚本拒绝执行 - 运行时错误:中断并回滚 |
- 入队错误(如语法):全事务拒绝 - 执行错误(如类型):仅失败命令 |
| 适用场景 | 需强原子性的复合操作 (如:库存扣减+日志记录) |
简单批量操作 (如:批量设置键值) |
| 性能影响 | 脚本执行期间阻塞其他命令(默认5秒超时) | 命令入队无阻塞,EXEC执行期间短时阻塞 |
5.1.3 使用案例:分布式锁与限流
1️⃣分布式锁实现
核心逻辑:
加锁:使用
SET key value NX PX 30000(唯一值防误删)。解锁:Lua 脚本校验锁持有者后删除 Key。
Lua 脚本(解锁):
if redis.call("GET", KEYS[1]) == ARGV[1] then return redis.call("DEL", KEYS[1]) else return 0 end执行命令:
EVAL "脚本内容" 1 my_lock:resource1 "client1-uuid"2️⃣限流算法优化
令牌桶算法:
-- KEYS[1]: 令牌桶Key
-- ARGV[1]: 桶容量
-- ARGV[2]: 填充速率(令牌/秒)
-- ARGV[3]: 当前时间戳
local capacity = tonumber(ARGV[1])
local rate = tonumber(ARGV[2])
local now = tonumber(ARGV[3])
local tokens = redis.call("HGET", KEYS[1], "tokens") or capacity
local last_refill = redis.call("HGET", KEYS[1], "last_refill") or now
local delta = math.max(0, now - last_refill)
local new_tokens = math.min(capacity, tokens + delta * rate)
if new_tokens >= 1 then
redis.call("HSET", KEYS[1], "tokens", new_tokens - 1)
redis.call("HSET", KEYS[1], "last_refill", now)
return 1 -- 允许请求
else
return 0 -- 限流
end✒️生产实践:
Lua 脚本管理:
使用
SCRIPT LOAD预加载脚本,通过EVALSHA执行(减少网络流量)。错误处理:捕获
NOSCRIPT错误并回退到EVAL。性能优化:
避免在 Lua 脚本中执行耗时操作(如
KEYS *),防止阻塞 Redis 主线程。控制脚本复杂度:单脚本执行时间建议 ≤1ms。
安全防护:
禁止使用全局变量,防止内存泄漏。
限制脚本权限:配置
rename-command EVAL ""禁用危险命令。
5.2 发布订阅(Pub/Sub)
Redis Pub/Sub 是一种轻量级的 消息广播模型,允许客户端通过频道(Channel)实现一对多的实时消息传递。其核心特点是 低延迟 和 简单易用,适合实时通知、事件驱动等场景。
5.2.1 基础操作与消息传递流程
发布消息:客户端向指定频道发送消息,所有订阅该频道的客户端将立即接收。
PUBLISH news:tech "Redis 7.0 released!"订阅频道:客户端可订阅一个或多个频道,接收实时消息。
SUBSCRIBE news:tech news:sports取消订阅:
UNSUBSCRIBE news:tech
消息传递流程:
[发布者] → PUBLISH → [Redis Server] → 实时推送 → [订阅者1, 订阅者2, ...]5.2.2 消息模式匹配(PSUBSCRIBE)
Redis 支持 通配符订阅,通过 PSUBSCRIBE 实现频道名的模式匹配。
通配符规则:
*:匹配任意字符(如news:*匹配news:tech和news:sports)。?:匹配单个字符(如logs:2023??匹配logs:202301)。
示例:
PSUBSCRIBE news:* # 订阅所有以 "news:" 开头的频道 PUNSUBSCRIBE news:* # 取消订阅
应用场景:
多维度消息分类(如按事件类型、用户ID分组)。
动态频道管理(无需提前创建固定频道)。
5.2.3 Redis Pub/Sub 的局限性
尽管 Pub/Sub 简单高效,但其设计目标并非替代专业消息队列,需注意以下限制:
消息可靠性问题:无持久化,消息仅在内存中暂存,若订阅者离线或 Redis 重启,消息将丢失。无确认机制,发布者无法感知消息是否被订阅者成功接收。
扩展性限制:无消息堆积能力,订阅者处理速度慢时,消息可能被丢弃(Redis 无消息缓冲区)。集群模式限制,Pub/Sub 在 Redis Cluster 中仅广播到节点本地订阅者,无法跨节点分发。
5.2.4 与消息队列(如 Kafka)的对比
| 特性 | Redis Pub/Sub | Kafka |
|---|---|---|
| 消息持久化 | 不支持(消息实时分发后丢失) | 支持 磁盘持久化,可配置保留时间/大小策略 |
| 消息确认机制 | 无ACK机制(可能丢消息) | 支持多级ACK 至少一次/精确一次语义,支持消费者组位移管理 |
| 吞吐量 | 高(单节点10万+/秒) | 极高(百万级/秒,分区水平扩展) |
| 延迟 | 亚毫秒级(内存直接操作) | 毫秒级 受持久化配置影响,SSD优化后可达1-5ms |
| 消息回溯 | 不支持 | 支持 按时间戳/偏移量重放历史数据 |
| 适用场景 | 实时通知、短任务广播 (如聊天室、游戏状态同步) |
日志收集、流处理 (如点击流分析、IoT设备遥测) |
结合两者优势构建健壮系统:
实时性要求高:使用 Redis Pub/Sub 做实时通知。
数据持久化需求:通过 Kafka 消费 Redis 消息并持久化。
# Python 示例:将 Redis 消息转发至 Kafka
import redis
from kafka import KafkaProducer
r = redis.Redis()
producer = KafkaProducer(bootstrap_servers='kafka:9092')
def forward_messages():
pubsub = r.pubsub()
pubsub.subscribe('news:*')
for message in pubsub.listen():
if message['type'] == 'message':
producer.send('news_topic', message['data'])
forward_messages() ✒️总结
Redis Pub/Sub:轻量级、低延迟,适合实时消息广播,但缺乏持久化与可靠性保障。
Kafka:高吞吐、高可靠,适合大规模数据管道与流处理,但需权衡延迟与复杂度。
混合架构:结合两者优势,实时性与持久化兼顾,是构建现代分布式系统的常见模式。
5.3 Stream与消息队列
Redis Stream 是 Redis 5.0 引入的数据类型,专为 消息队列场景 设计,支持 消息持久化、消费者组 和 ACK 确认机制,弥补了 Pub/Sub 在可靠性上的不足,成为轻量级分布式消息队列的首选方案。
5.3.1 基础结构与操作
消息结构:
每条消息由唯一递增的 消息ID(格式:<时间戳>-<序列号>,如1630454400000-0)和多个键值对组成。核心命令:
生产消息:
XADD mystream * key1 value1 key2 value2(*表示自动生成ID)。消费消息:
XREAD COUNT 10 STREAMS mystream 0(从ID0开始读取10条消息)。范围查询:
XRANGE mystream - +(查询所有消息)。
示例:
# 生产者:发送订单事件
XADD orders:* * order_id 1001 status "created"
# 消费者:实时监听新消息
XREAD BLOCK 5000 STREAMS orders:* $ 5.3.2 消费者组(Consumer Groups)
消费者组是 Redis Stream 实现 负载均衡 和 竞争消费 的核心机制,允许多个消费者协同处理同一消息流。
消费者组操作:
创建消费者组:
XGROUP CREATE orders:stream order_group $ MKSTREAM # MKSTREAM:若流不存在则自动创建消费者加入组:
XREADGROUP GROUP order_group consumer1 COUNT 1 STREAMS orders:stream > # `>` 表示仅消费未ACK的消息查看组状态:
XINFO GROUPS orders:stream # 查看所有消费者组 XINFO CONSUMERS orders:stream order_group # 查看组内消费者
消费者组特性:
负载均衡:组内消费者自动分配消息,提升处理能力。
消息独占性:每条消息仅被组内一个消费者获取,避免重复消费。
Pending 列表:已分配但未ACK的消息进入Pending列表,超时后重新投递。
5.3.3 消息持久化与ACK机制
Redis Stream 通过 消息持久化存储 和 ACK 确认 实现高可靠性,保障消息不丢失。
1️⃣消息持久化
存储机制:
Stream 数据以 紧凑的基数树(Radix Tree) 结构存储在内存中,同时支持 AOF/RDB 持久化。数据保留策略:
固定数量:
XTRIM orders:stream MAXLEN 1000(保留最新1000条消息)。时间窗口:
XTRIM orders:stream MINID ~ 1630454400000-0(删除早于指定ID的消息)。
2️⃣ACK机制
手动ACK:消费者处理消息后需显式确认,否则消息将滞留于Pending列表。
XACK orders:stream order_group 1630454400000-0自动ACK:通过
XREADGROUP的NOACK参数禁用ACK(不推荐,可能丢失消息)。
Pending 消息处理:
重新投递:通过
XCLAIM命令将超时未ACK的消息转移给其他消费者。XCLAIM orders:stream order_group consumer2 3600000 1630454400000-0 # 3600000:最小空闲时间(毫秒)死信处理:监控Pending列表,超过重试次数后移入死信流。
3️⃣与专业消息队列(如 Kafka)的对比
| 特性 | Redis Stream | Kafka |
|---|---|---|
| 吞吐量 | 万级/秒 (单节点性能,受内存限制) |
百万级/秒 (分区横向扩展,支持集群) |
| 持久化 | 内存存储 依赖AOF/RDB持久化策略 |
磁盘持久化 支持TB级数据存储,保留策略可配置 |
| 消息回溯 | 基于消息ID范围查询 (如 0-0或时间戳) |
基于分区偏移量 (支持精确位移定位+时间戳检索) |
| 消费者组 | 内置基础功能 支持ACK确认、故障转移、消息重投递 |
企业级功能 支持多分区并行消费、再平衡、精确位移控制 |
| 适用场景 |
✔️ 轻量级实时队列
✔️ 事件溯源存储
✔️ IoT设备状态同步
|
✔️ 金融交易日志
✔️ 实时流处理
✔️ 大数据ETL管道
|
✒️生产实践:
消费者组设计:消费者数量,与分区(Stream)数量匹配,避免资源闲置;心跳监控,定期检查消费者存活状态(
XINFO CONSUMERS)。消息可靠性保障:ACK 超时设置,根据业务处理时间调整Pending超时阈值
XGROUP SETID orders:stream order_group 1630454400000-0 ENTRIESREAD 1000;死信队列,将多次重试失败的消息转移至独立Stream,人工介入处理。性能优化:批量消费,通过
COUNT参数一次读取多条消息,减少网络开销XREADGROUP GROUP order_group consumer1 COUNT 100 BLOCK 5000 STREAMS orders:stream >;内存控制,定期清理历史消息(XTRIM),避免内存溢出。
5.4 模块化扩展
Redis 自 4.0 版本引入 模块化架构,允许开发者通过动态加载模块(Redis Modules)扩展核心功能,突破原生数据类型的限制。模块化设计使得 Redis 能够灵活支持全文搜索、图计算、时间序列等复杂场景,同时保持高性能与低延迟。
5.4.1 Redis 官方与社区模块
1️⃣RediSearch:全文搜索引擎
功能特性:
倒排索引:支持文本分词、模糊匹配、多字段联合查询。
高性能:毫秒级响应,适合千万级文档的实时搜索。
扩展语法:支持聚合、排序、分页、高亮等高级功能。
安装与使用:
编译加载模块:
# 下载并编译 RediSearch git clone https://github.com/RediSearch/RediSearch.git cd RediSearch && make # 启动 Redis 时加载模块 redis-server --loadmodule ./redisearch.so创建索引与插入数据:
FT.CREATE product_idx ON HASH PREFIX 1 "product:" SCHEMA name TEXT WEIGHT 5.0 description TEXT price NUMERIC SORTABLE HSET product:1001 name "Laptop X1" description "Intel i7, 16GB RAM" price 999执行搜索:
FT.SEARCH product_idx "@name:(Laptop) @price:[800 1200]" RETURN 2 name price
适用场景:
电商商品搜索、日志分析、实时推荐系统。
2️⃣RedisJSON:原生JSON支持
功能特性:
JSON 数据类型:原生支持 JSON 存储与操作,避免序列化开销。
路径查询:支持 JSONPath 语法,灵活提取和修改嵌套字段。
原子操作:直接操作 JSON 结构,无需读取-修改-写回流程。
安装与使用:
加载模块:
redis-server --loadmodule /path/to/rejson.so存储与查询 JSON:
JSON.SET user:1001 . '{"name":"Alice","age":30,"address":{"city":"New York"}}' JSON.GET user:1001 .address.city # 输出 "New York" JSON.NUMINCRBY user:1001 .age 1 # age 变为31
适用场景:
用户配置存储、API 数据缓存、动态 Schema 文档数据库。
3️⃣其他热门模块
| 模块 | 功能 | 使用场景 |
|---|---|---|
| RedisGraph |
- 原生图数据库引擎 - 支持Cypher查询语言 - 内置图算法(最短路径/PageRank) 内存密集型操作,需控制图规模 |
✔️ 社交关系分析
✔️ 金融欺诈检测(资金链路追踪)
✔️ 推荐系统(用户行为图谱)
|
| RedisTimeSeries |
- 高精度时间序列存储 - 支持降采样/聚合计算(SUM/AVG等) - 自动过期策略 支持毫秒级时间戳,压缩率高达90%+ |
✔️ IoT传感器数据监控
✔️ 应用性能指标分析(QPS/延迟)
✔️ 金融行情实时存储(股票分时数据)
|
| RedisBloom |
- 概率型数据结构集合 - 包含:布隆过滤器/Count-Min Sketch/Cuckoo Filter - 空间效率极高(0.1%误差率仅需1KB内存) 误判率需根据业务容忍度配置 |
✔️ 爬虫URL去重(布隆过滤器)
✔️ 用户日活统计(HyperLogLog)
✔️ 高频事件检测(Top-K算法)
|
5.4.2 自定义模块开发入门
1️⃣开发环境准备
安装依赖:
# 安装 Rust(推荐语言) curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh # 安装 Redis 模块开发工具 cargo install cargo-edit redis-module创建项目:
cargo new --lib my_redis_module cd my_redis_module
2️⃣编写示例模块:字符串反转
use redis_module::{Context, RedisResult, RedisString, NotifyEvent};
#[redis_module::command]
fn reverse(ctx: &Context, args: Vec<RedisString>) -> RedisResult {
if args.len() != 2 {
return Err("ERR wrong number of arguments".into());
}
let key = args[1].to_string();
let mut value = ctx.key_get(&key)?;
value.reverse();
ctx.key_set(&key, value)?;
Ok("OK".into())
}
redis_module! {
name: "reverse",
version: 1,
data_types: [],
commands: [
["reverse", reverse, "write", 1, 1, 1],
],
} 编译与加载:
编译为动态库:
cargo build --release启动 Redis 加载模块:
redis-server --loadmodule ./target/release/libmy_redis_module.so
测试命令:
SET msg "hello" REVERSE msg # 值变为 "olleh" GET msg # 输出 "olleh"3️⃣模块开发注意事项
内存管理:避免内存泄漏,确保分配的资源(字符串、数据结构)正确释放。
并发安全:Redis 单线程模型下无需处理并发,但阻塞操作需谨慎(如网络IO)。
性能优化:减少复杂计算,避免阻塞主线程(耗时操作异步化)。
✒️Redis 模块化架构通过 RediSearch、RedisJSON 等扩展实现了从缓存到多模数据库的跃升,而自定义模块开发则赋予企业深度定制能力。其核心价值在于:
功能扩展性:突破原生数据类型的限制,支持复杂场景。
性能与灵活性:直接操作内存数据,避免外部系统交互开销。
生态整合:与 Redis 高可用、持久化机制无缝集成。
六、性能优化与监控
6.1 性能调优
6.1.1 延迟分析(SLOWLOG、redis-cli --latency)
Redis 的性能瓶颈通常集中在 网络延迟、命令执行时间 和 内存访问效率 三个维度。以下工具帮助快速定位问题:
1️⃣SLOWLOG:慢查询日志的深度解读
Redis 的慢查询日志(SLOWLOG)是定位性能问题的第一道防线,记录所有执行时间超过指定阈值的命令,帮助开发者快速识别低效操作。
工作机制:
Redis 的慢查询日志记录执行时间超过指定阈值的命令,帮助开发者识别潜在性能问题。其底层实现基于一个 FIFO 队列,当命令执行时间超过slowlog-log-slower-than配置值(单位:微秒)时,将该命令及其执行上下文(时间戳、耗时、客户端信息等)存入队列。队列长度由slowlog-max-len控制,超出时自动淘汰旧记录。配置参数详解:
# redis.conf 关键配置项 slowlog-log-slower-than 10000 # 记录超过10ms的命令,设置为0记录所有命令,-1禁用 slowlog-max-len 128 # 慢查询日志最大存储条数操作命令与日志解析:
# 查看慢查询日志(取最新5条) SLOWLOG GET 5输出示例:
1) 1) (integer) 14 # 日志ID(自增) 2) (integer) 1630455000 # Unix时间戳 3) (integer) 120000 # 执行耗时(微秒) 4) 1) "KEYS" # 命令数组 2) "user:*" 5) "127.0.0.1:52341" # 客户端地址 6) "client_name=prod_web" # 客户端名称(通过CLIENT SETNAME设置)优化建议:
避免
KEYS *、FLUSHALL等阻塞命令,用SCAN替代。复杂查询迁移至 RediSearch 模块。
2️⃣redis-cli --latency:网络延迟的精准测量
延迟测试:
redis-cli --latency -h <host> -p <port> # 持续输出网络延迟统计(单位:毫秒)输出解析:
min: 0, max: 12, avg: 0.18 (1663 samples) # 采样统计avg:平均延迟(建议 ≤1ms)。
max:最大延迟(排查网络抖动)。
99%:P99 延迟(反映长尾效应)。
延迟分类与根因分析:
| 延迟类型 | 表现特征 | 排查方向 |
|---|---|---|
| 网络传输延迟 | avg > 1ms, 波动系数<0.3 |
✔️ 网络设备状态(交换机/路由器) ✔️ 带宽使用率监控 ✔️ 云服务商QoS策略检查 |
| Redis 实例过载 | avg≤0.5ms, max≥50ms突增 |
🔍 INFO CPU(CPU使用率)🔍 slowlog get(慢查询分析)🔍 AOF重写/RDB持久化监控 |
| 客户端资源竞争 | 部分客户端P99≥100ms, 其他客户端正常 |
⚠️ 连接池max-active配置⚠️ 线程池队列堆积监控 ⚠️ JVM GC暂停日志分析 |
优化案例:
某电商平台发现 Redis 平均延迟为 2.3ms,通过redis-cli --latency检测发现跨机房访问导致网络延迟。解决方案:将 Redis 实例迁移至业务服务器同机房;客户端启用连接池,复用 TCP 连接。迁移后延迟降至 0.1ms,QPS 提升 40%。
6.1.2 网络优化(Pipeline、连接池)
1️⃣Pipeline:批量命令打包
原理:将多个命令打包发送,减少网络往返次数(RTT)。
示例(Python):
Python性能提升:
2️⃣连接池:复用TCP连接
配置示例(Java Jedis):
JedisPoolConfig config = new JedisPoolConfig(); config.setMaxTotal(100); // 最大连接数 config.setMaxIdle(20); // 最大空闲连接 config.setMinIdle(5); // 最小空闲连接 config.setTestOnBorrow(true); // 取连接时健康检查 JedisPool pool = new JedisPool(config, "redis-host", 6379);参数调优:
maxTotal:根据 QPS 和平均命令耗时计算,例如 QPS=1000,平均耗时=1ms,则需约 10 连接。
maxIdle:避免频繁创建连接,建议设置为 maxTotal 的 20%~50%。
6.1.3 大Key与热Key:定位与处理
1️⃣大Key(BigKey)
定义:String 类型:Value > 10 KB。Hash/List 等:元素数 > 5000 或总大小 > 10 MB。
危害:内存不均,引发数据迁移阻塞;阻塞主线程(如删除 1GB 的 Key 耗时 > 1s)。
定位工具:
redis-cli --bigkeys(抽样扫描):
redis-cli -h 127.0.0.1 --bigkeys # 输出各类型最大Key统计自定义扫描脚本(Python + SCAN):
import redis r = redis.Redis() cursor = 0 while True: cursor, keys = r.scan(cursor, count=100) for key in keys: type = r.type(key).decode() if type == "hash" and r.hlen(key) > 5000: print(f"BigKey: {key}, Type: {type}, Size: {r.hlen(key)}") if cursor == 0: break
处理方案:
拆分:将 Hash 拆分为多个子Key(如
user:1001:info→user:1001:base+user:1001:detail)。压缩:对 String 类型 Value 使用 Gzip 或 Snappy 压缩。
过期时间:对非核心数据设置 TTL,自动清理。
2️⃣热Key(HotKey)
定义:高频访问的Key(如 QPS > 5000)。
危害:单节点 CPU 过载,引发性能瓶颈。
定位方法:
redis-cli --hotkeys(需开启 LFU 淘汰策略):
redis-cli --hotkeys # 输出访问频率最高的Key监控工具:
Redis INFO commandstats:统计各类型命令调用次数。
APM工具:Datadog、SkyWalking 追踪Key访问链路。
处理方案:
本地缓存:客户端缓存热Key,设置短过期时间(如 Guava Cache)。
分片存储:将 Key 拆分为多个子Key(如
product:1001→product:1001:shard1、product:1001:shard2)。读写分离:通过 Redis 集群从节点分担读压力。
6.2 监控工具
6.2.1 INFO 命令
Redis 的 INFO 命令提供了详尽的运行时状态信息,涵盖内存、持久化、复制等核心维度,是快速诊断问题的首选工具。
1️⃣内存监控
命令示例:
redis-cli info memory输出示例:
# Memory
used_memory: 1024000
used_memory_human: 1000.00K
mem_fragmentation_ratio: 1.23
maxmemory: 1048576
maxmemory_policy: allkeys-lru关键指标:
| 指标 | 说明 | 健康标准 |
|---|---|---|
used_memory_human |
当前内存使用量(人类可读格式) |
<
maxmemory的
70%
|
mem_fragmentation_ratio |
内存碎片率(used_memory_rss / used_memory) | < 1.5 |
maxmemory_policy |
内存淘汰策略(如 allkeys-lru) |
✔️ 缓存场景:
allkeys-lru✔️ 持久化场景:
noeviction |
2️⃣持久化监控
命令示例:
redis-cli info persistence输出示例:
# Persistence
rdb_last_save_time: 1698765432
rdb_last_bgsave_status: ok
aof_current_size: 2048000
aof_rewrite_in_progress: 0关键指标:
| 指标 | 说明 | 健康标准 |
|---|---|---|
rdb_last_save_time |
最后一次RDB持久化的UNIX时间戳 |
定期保存 (如每5分钟通过 save配置)
|
rdb_last_bgsave_status |
最后一次后台RDB保存状态 | ok |
aof_current_size |
AOF文件当前体积(单位:字节) |
✔️ 根据业务容忍度配置
建议监控增长率(如>1GB/小时需告警)
|
aof_rewrite_in_progress |
AOF重写进程状态标识 | 0(正常状态) |
3️⃣复制监控
命令示例:
redis-cli info replication输出示例:
# Replication
role:master
connected_slaves:2
master_repl_offset:123456789
replica_repl_offset:123456000
repl_backlog_active:1关键指标:
| 指标 | 说明 | 健康标准 |
|---|---|---|
connected_slaves |
当前活跃从节点连接数 |
与
replica
配置一致(数量不符需检查网络/认证配置) |
master_repl_offset |
主节点写入操作累计偏移量 |
持续增长 停滞可能表示 主节点写入异常
|
replica_repl_offset |
从节点已复制数据偏移量 |
差值 < 1MB 计算公式: master_offset - replica_offset
|
repl_backlog_active |
复制积压缓冲区启用状态 |
1
(启用状态) 0 表示断线后无法增量同步 |
6.2.2 Prometheus + Grafana:构建企业级监控大盘
Prometheus 是一款开源的监控与告警工具,结合 Grafana 的可视化能力,可构建 Redis 的全链路监控体系。
数据采集架构:[Redis Exporter] → [Prometheus] → [Grafana]
部署步骤:
启动 Redis Exporter:
docker run -d --name redis-exporter -p 9121:9121 oliver006/redis-exporter \ --redis.addr=redis://192.168.1.100:6379Prometheus 配置(prometheus.yml):
scrape_configs: - job_name: 'redis' static_configs: - targets: ['192.168.1.100:9121']Grafana 仪表盘导入:使用官方 Dashboard ID 763(Redis 概览)和 11835(Redis 深度监控)。
核心监控面板:
资源使用:内存占用、连接数、CPU 使用率。
持久化状态:RDB/AOF 最后一次执行状态、耗时。
复制健康度:主从延迟、同步错误次数。
6.2.3 Redis 自带工具链
Redis 提供了一系列内置工具,帮助开发者快速定位问题。
1️⃣redis-stat:实时命令行监控
安装与运行:
gem install redis-stat redis-stat --server=192.168.1.100 --port=6379 --interval=5 --verbose输出示例:
[2023-09-01 12:00:00] connected_clients: 45, used_memory: 3.2G, ops/sec: 12002️⃣redis-cli --bigkeys:快速识别大Key
命令示例:
redis-cli -h 192.168.1.100 --bigkeys -i 0.1 # 每100ms扫描100个Key输出示例:
Biggest string found 'user:1001:data' has 1536000 bytes
Biggest hash found 'product:2001:props' has 3245 fields6.3 压力测试
6.3.1 redis-benchmark:官方压测利器
redis-benchmark 是 Redis 官方提供的性能测试工具,可模拟高并发场景,验证系统极限。
1️⃣基础压测
命令:
redis-benchmark -h 192.168.1.100 -p 6379 -n 100000 -c 50 -P 10参数解析:
-n 100000:总请求数-c 50:并发连接数-P 10:Pipeline 打包10个命令
输出解读:
====== SET ======
100000 requests completed in 2.00 seconds
50 parallel clients
3 bytes payload
keep alive: 1
host configuration "save": 3600 1 300 100 60 10000
Latency by percentile:
50% <= 0.8 ms
95% <= 1.2 ms
99% <= 2.1 ms2️⃣定制化压测
混合读写测试:
redis-benchmark -h 192.168.1.100 -t set,get -n 100000 -c 100大Value测试:
edis-benchmark -h 192.168.1.100 -n 10000 -d 102400 # 100KB Value6.3.2 模拟高并发场景的进阶方法
分布式压测架构:
[Locust 集群] → [Redis 实例]Locust 脚本示例(模拟秒杀场景):
from locust import HttpUser, task, between
import redis
class RedisUser(HttpUser):
wait_time = between(1, 5)
def on_start(self):
self.client = redis.Redis(host='192.168.1.100', port=6379)
@task
def spike(self):
product_id = "1001"
self.client.decr(f"stock:{product_id}")监控与瓶颈分析:
Redis 服务端:关注
used_cpu_sys、used_cpu_user判断是否 CPU 瓶颈。客户端:通过
dstat或nmon监控网络带宽与线程状态。
✒️优化策略矩阵:
优化维度 工具/技术 适用场景 延迟降低 Pipeline
连接池
大Key拆分高并发读写
跨机房访问
(RTT>10ms时效果显著)吞吐量提升 集群分片
读写分离
客户端缓存电商秒杀
社交Feed流
(QPS>5万/秒)内存优化 数据分片
压缩算法
过期策略大数据量存储(>100GB)
成本敏感型业务
(内存成本降低30%+)稳定性保障 慢查询监控
热Key检测
持久化配置金融交易
实时推荐系统
(SLA>99.99%)
七、安全与运维管理
7.1 安全配置
7.1.1 认证机制:构建访问控制第一道防线
1️⃣密码认证(requirepass)
基础配置:在
redis.conf中启用密码认证,防止未授权访问:
requirepass 7yN$5xL!eP@ssw0rd_ # 16位以上密码,包含大小写、符号、数字客户端连接验证:
redis-cli -a 7yN$5xL!eP@ssw0rd_ # 命令行明文输入(不推荐)
# 更安全的方式:交互式输入
AUTH 7yN$5xL!eP@ssw0rd_ ACL 细粒度控制(Redis 6.0+):
# 创建仅允许读取用户数据的账户 ACL SETUSER data-reader on >R3@d0nlyP@ss ~user:* +@hash ~* -@all~user:*:允许访问以user:开头的 Key。+@hash:仅允许哈希类型操作(HGET、HSCAN 等)。-@all:禁止所有非哈希操作。
2️⃣禁用高危命令
配置方法:
# redis.conf
rename-command CONFIG "" # 彻底禁用 CONFIG
rename-command FLUSHDB "ADMIN_FLUSHDB" # 重命名命令高危命令清单:FLUSHALL(清空所有数据)、SHUTDOWN(关闭服务)、DEBUG(调试命令)。
验证效果:
redis-cli CONFIG GET requirepass # 返回错误:未知命令7.1.2 网络隔离:缩小攻击面
1️⃣绑定 IP 与端口
配置示例:
bind 192.168.1.100 10.0.0.2 # 仅允许指定 IP 访问
protected-mode yes # 禁止公网无密码访问(默认开启)
port 6380 # 修改默认端口(避免自动化扫描)2️⃣防火墙与安全组
iptables 规则:
# 仅允许内网网段访问 Redis 端口
iptables -A INPUT -p tcp --dport 6380 -s 192.168.1.0/24 -j ACCEPT
iptables -A INPUT -p tcp --dport 6380 -j DROP云环境安全组(阿里云/AWS):
入站规则:仅允许应用服务器私有 IP 访问。
出站规则:禁止 Redis 实例主动外连。
7.1.3 SSL/TLS 加密通信:数据防窃听核心方案
1️⃣证书生成与配置
自签名证书生成:
# 生成 CA 证书
openssl req -new -x509 -days 365 -keyout ca.key -out ca.crt -subj "/CN=Redis CA"
# 生成服务端证书
openssl genrsa -out redis.key 2048
openssl req -new -key redis.key -out redis.csr -subj "/CN=redis.example.com"
openssl x509 -req -in redis.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out redis.crt -days 365服务端配置:
# redis.conf
port 0 # 禁用非加密端口
tls-port 6379
tls-cert-file /etc/redis/redis.crt
tls-key-file /etc/redis/redis.key
tls-auth-clients yes # 强制客户端证书验证2️⃣客户端加密连接
Python 客户端示例:
import redis
r = redis.Redis(
host='redis.example.com',
port=6379,
ssl=True,
ssl_ca_certs='/path/to/ca.crt',
ssl_certfile='/path/to/client.crt',
ssl_keyfile='/path/to/client.key'
)
print(r.ping()) # 返回 True 表示加密通信成功✒️生产实践:
定期更新证书(建议有效期 ≤1 年)。
启用 TLS 1.3 和强密码套件(如
TLS_AES_256_GCM_SHA384)。
7.2 备份与恢复
7.2.1 RDB/AOF 手动备份
1️⃣RDB 手动备份
RDB(Redis DataBase)通过生成内存快照(dump.rdb)实现全量备份,适合灾难恢复与大规模迁移。
命令触发:
# 阻塞式备份(生产环境慎用)
redis-cli SAVE
# 后台异步备份(推荐)
redis-cli BGSAVE
定时脚本备份(示例):通过定时任务(如每天0点)执行脚本,自动备份并清理旧文件
#!/bin/bash
BACKUPDIR="/backup/redis"
RDBFILE="/data/dump.rdb"
current_date=$(date +%Y%m%d-%H%M%S)
cp -a ${RDBFILE} ${BACKUPDIR}/${current_date}-dump.rdb
# 删除7天前的备份
find ${BACKUPDIR} -type f -mtime +7 -exec rm -rf {} \;恢复流程:
停止 Redis 服务。
替换
dump.rdb文件至 Redis 数据目录(通过CONFIG GET dir查询路径)。重启 Redis,自动加载备份数据。
注意:恢复前需关闭目标实例的 AOF 功能(
CONFIG SET appendonly no),避免冲突。
优缺点:
优点:文件紧凑(二进制压缩),恢复速度快。
缺点:可能丢失最后一次快照后的数据(如宕机前未备份的写入)
2️⃣AOF 手动备份
AOF(Append Only File)记录所有写操作命令,通过重放实现细粒度恢复。
备份操作:
启用配置:
appendonly yes # 开启AOF appendfsync everysec # 每秒同步(平衡性能与安全)appendonly yes # 开启AOF appendfsync everysec # 每秒同步(平衡性能与安全)手动优化与备份:
redis-cli BGREWRITEAOF # 后台重写AOF,压缩冗余命令 cp /data/appendonly.aof /backup/redis/appendonly-$(date +%F).aof
恢复流程:
确保
appendonly.aof文件完整。启动 Redis 时自动加载 AOF 文件。
注意:若 AOF 文件损坏,可使用
redis-check-aof --fix修复。
优缺点:
优点:数据丢失风险低(秒级恢复);可读性强(文本格式)。
缺点:文件体积大;恢复速度慢于 RDB。
7.2.2 混合持久化策略(推荐)
结合 RDB 和 AOF 优势,实现高效全量备份与实时增量保护:
save 3600 1 # 每小时全量备份
appendonly yes # 开启AOF
aof-use-rdb-preamble yes # 混合持久化(Redis 4.0+)恢复优先级:Redis 重启时优先加载 AOF,若损坏则回退至 RDB 。
7.2.3 云服务商自动备份策略:解放运维人力
| 云厂商 | 备份机制 | 恢复能力 | 存储与加密 |
|---|---|---|---|
| 阿里云 | ✔️ 每日全量 + 🕒 每小时增量 |
时间点恢复(秒级精度) |
OSS 存储AES-256 加密 |
| AWS |
🔄 自动每日备份 保留期 1-35 天可调 |
跨AZ实例重建(5分钟内完成) |
S3 存储跨区域复制 |
| 腾讯云 | ✔️ 每日全量 + ⚡ 实时AOF同步 |
一键回档(任意备份点) |
COS 存储SSL/TLS 传输加密 |
操作示例(阿里云):
开启自动备份:控制台 → 备份恢复 → 设置备份时间窗口(如凌晨1点)。
跨区域容灾:将备份文件复制至其他地域的 OSS 存储桶。
7.3 日常运维
7.3.1 版本升级与兼容性
版本升级流程与注意事项:
兼容性评估:
协议变更:Redis 不同大版本(如 5.x → 6.x → 7.x)可能存在协议不兼容问题,例如 6.0 引入 RESP3 协议,需检查客户端 SDK 是否支持。
命令废弃:如 Redis 7.0 弃用
SLAVEOF,改为REPLICAOF,需提前修改脚本。编译环境验证:低版本 GCC(如 4.8.5)可能导致编译失败(如 Redis 6.0.16 在 CentOS 7.9 编译报错),建议升级至 GCC 9+。
滚动升级步骤:
从节点优先升级:逐个升级从节点,避免全量同步阻塞主节点。
主节点切换:使用
CLUSTER FAILOVER迁移主节点职责后升级。客户端兼容性测试:验证新版本对事务(MULTI/EXEC)、Lua 脚本的支持。
回滚方案:
保留旧版本二进制文件,出现严重问题时快速切换。
使用
CONFIG REWRITE动态回退配置参数。
✒️生产实践:
版本锁定策略:生产环境建议选择长期支持版本(如 Redis 7.0.x),避免频繁升级。
容器化隔离:通过 Docker 或 Kubernetes 部署,隔离不同业务对 Redis 版本的依赖。
渐进式测试:
测试阶段 验证内容 工具推荐 单元测试 ✔️ 关键命令兼容性
(如CLUSTER INFO、MOVED重定向)redis-cli+
自定义脚本
(Python/Shell测试用例)性能测试 redis-benchmark
参数示例:-n 100000 -c 50容灾演练 ⚠️ 主节点故障模拟
FAILOVER自愈时效 <30sredis-sentinel
redis-cluster-tool
监控指标:connected_slaves
7.3.2 内存碎片整理(MEMORY PURGE)
成因分析:
内因:内存分配器(如 jemalloc)按固定大小分配内存块,剩余空间无法被利用。
外因:频繁写入/删除不同大小的键值对,导致空间碎片化。
监控指标:
mem_fragmentation_ratio = used_memory_rss / used_memory健康阈值:1 ≤ 比值 ≤ 1.5;若 >1.5 需立即处理。
碎片清理策略:
手动清理(低峰期执行):
redis-cli MEMORY PURGE # 阻塞主线程,适用于碎片率突增场景自动清理配置(Redis 4.0+):
activedefrag yes # 开启自动碎片整理 active-defrag-ignore-bytes 100mb # 碎片量达100MB时触发 active-defrag-threshold-lower 10 # 碎片率≥10%时触发 active-defrag-cycle-min 5 # CPU占用下限(5%) active-defrag-cycle-max 75 # CPU占用上限(75%)运维建议:
避免大Key频繁修改:如 Hash 类型字段数超过 5000 时,拆分为多个子 Key。
混合持久化:启用
aof-use-rdb-preamble,减少 AOF 重写时的碎片产生。
7.3.3 集群运维常见问题(节点故障处理)
节点故障处理流程:
故障检测:
集群状态:通过
CLUSTER NODES查看节点角色(master/slave)及状态(fail/pfail)。哨兵机制:Sentinel 自动触发主节点切换,并更新客户端路由表。
恢复步骤:
从节点晋升:若主节点宕机,优先选择复制偏移量(
master_repl_offset)最大的从节点接管。数据同步:故障节点恢复后,执行
CLUSTER FAILOVER强制全量同步。客户端重定向:使用
MOVED或ASK错误码引导请求至新节点。
网络分区应对策略:
预防措施:
参数配置:设置
min-slaves-to-write 1,确保至少一个从节点完成同步才允许写入。多机房部署:跨 AZ 部署哨兵节点,避免单区域网络隔离导致误判。
分区恢复:
自动愈合:网络恢复后,集群通过 Gossip 协议交换状态,重新选举主节点并同步数据。
数据一致性校验:使用
redis-check-rdb或redis-check-aof验证备份文件完整性。
7.3.4 运维工具链推荐
| 工具/平台 | 功能场景 | 适用阶段 |
|---|---|---|
RedisInsight |
✔️ 可视化监控面板 🔍 慢查询分析追踪 🌐 集群拓扑管理 |
日常巡检
故障诊断(内存泄漏/性能抖动)
|
Prometheus |
📊 指标采集(QPS/内存/连接数) ⚠️ 动态阈值告警 rate(redis_commands_total[5m])
|
性能调优 容量规划(预测资源缺口) |
Ansible |
🚀 批量部署Redis节点 🛠️ 配置模板统一管理 示例: ansible-playbook redis-cluster.yml
|
版本升级(滚动更新)
集群扩容(自动添加分片)
|
Vault |
🔑 动态密码轮换 📜 TLS证书自动化管理 集成: redis + Vault Agent
|
零信任架构实施
合规审计(密钥访问日志)
|
✒️总结:
Redis 日常运维需围绕 版本管理、内存优化、集群稳定性 三大核心展开:
版本升级:通过滚动升级、容器化隔离、多维度测试规避兼容性问题。
内存碎片:结合手动清理与自动阈值配置,平衡资源利用率与性能影响。
集群容灾:依托哨兵机制、数据同步策略及网络分区预案,保障高可用性。
运维黄金准则:
监控先行:建立覆盖 CPU、内存、网络的实时监控体系。
渐进优化:每次变更仅调整一个变量,避免连锁故障。
文档沉淀:记录故障处理过程,形成可复用的运维知识库
八、典型应用场景
8.1 缓存穿透、雪崩、击穿:问题本质与多维解决方案
8.1.1 缓存穿透
问题本质:大量请求查询 不存在的数据(如非法ID、攻击请求),绕过缓存直击数据库,导致服务雪崩。
典型案例:
用户ID为自增数字,攻击者随机生成负数或超大数值发起请求。
未校验的查询参数(如不存在的商品SKU)。
核心解决方案:
1️⃣Redis实现布隆过滤器(RedisBloom模块)
安装与配置:
# 下载RedisBloom插件
git clone --recursive https://github.com/RedisBloom/RedisBloom.git
cd RedisBloom && make
# 启动Redis时加载模块
redis-server --loadmodule ./redisbloom.so命令详解:
创建过滤器:
BF.RESERVE user_ids 0.001 1000000 # 误判率0.1%,容量100万添加元素:
BF.ADD user_ids 1001 BF.MADD user_ids 1002 1003 1004 # 批量添加查询元素:
BF.EXISTS user_ids 1001 # 返回1(存在)或0(不存在)
动态更新策略:
冷启动问题:初始化时扫描数据库全量数据,批量写入布隆过滤器。
import redis from db import get_all_valid_ids rb = redis.Redis() rb.delete('user_ids') # 清空旧数据 ids = get_all_valid_ids() rb.bf_madd('user_ids', *ids) # 批量导入增量同步:通过数据库Binlog监听新增/删除操作,实时更新过滤器。
# 监听MySQL Binlog示例(使用python-mysql-replication) from pymysqlreplication import BinLogStreamReader stream = BinLogStreamReader( connection_settings=mysql_config, server_id=100, blocking=True, resume_stream=True ) for binlogevent in stream: if isinstance(binlogevent, WriteRowsEvent) and binlogevent.table == 'users': for row in binlogevent.rows: user_id = row['values']['id'] rb.bf_add('user_ids', user_id)
优化与注意事项:
分层过滤:
本地缓存:使用Guava Cache缓存最近查询的合法ID,减少Redis查询压力。
LoadingCache<Long, Boolean> localFilter = CacheBuilder.newBuilder() .maximumSize(100000) .expireAfterWrite(10, TimeUnit.MINUTES) .build(new CacheLoader<>() { @Override public Boolean load(Long key) { return rb.bfExists("user_ids", key); } });布隆过滤器:拦截非法ID,误判请求放行至缓存和数据库。
误判处理:
业务容忍:对误判请求返回默认值(如空列表),而非透传至数据库。
动态调整:根据业务增长定期扩容过滤器(使用
BF.RESERVE调整容量)。
缓存空对象(Cache Null):
策略:对查询结果为空的Key,缓存短时间占位符(如
"NULL",TTL=5分钟)。风险:需定期清理无效空值,避免内存浪费。
2️⃣缓存空对象(Cache Null)
实现细节:
缓存占位符:
对数据库查询为空的Key,缓存特殊值(如
NULL),并设置较短TTL(如5分钟)。代码示例(Java + Spring Cache):
@Cacheable(value = "userCache", key = "#userId", unless = "#result == null") public User getUser(Long userId) { User user = userRepository.findById(userId).orElse(null); if (user == null) { // 触发缓存空值(需自定义CacheManager支持) return new NullUser(); } return user; }
内存治理:
定期清理:通过定时任务扫描并删除长期未访问的空值Key。
# Redis Lua脚本示例:删除7天内未被访问的NULL值 EVAL "local keys = redis.call('SCAN', 0, 'MATCH', 'user:*') for _, key in ipairs(keys) do if redis.call('GET', key) == 'NULL' and redis.call('OBJECT', 'IDLETIME', key) > 604800 then redis.call('DEL', key) end end" 0内存淘汰策略:配置
maxmemory-policy=volatile-ttl,优先淘汰短TTL的Key。
适用场景:
数据可能动态变为有效(如新用户注册后,原非法ID变为合法)。
查询结果为空的比例较低(避免内存浪费)。
3️⃣组合方案增强
防御架构:
客户端 → API网关(参数校验) → 本地缓存 → 布隆过滤器 → Redis缓存 → 数据库流量监控:
对频繁触发布隆过滤器的IP进行限流(如Nginx限速模块)。
使用Prometheus监控缓存穿透率(公式:
穿透请求量 / 总请求量)。
8.1.2 缓存击穿
问题本质:高并发访问的热点Key突然失效(如到期或手动清除),导致所有请求穿透至数据库。
典型案例:秒杀商品库存缓存失效、微博热搜榜单更新。
核心解决方案:
1️⃣互斥锁(Mutex Lock)
分布式锁实现方案对比:
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
SETNX + Lua |
✔️ 实现简单 🚫 无外部依赖 |
⚠️ 手动锁续期 🚫 不可重入 (需自行实现续期逻辑) |
简单业务逻辑
并发量 < 500/s
|
Redisson |
⏳ 自动续期(看门狗) 🔄 可重入锁支持 |
🔧 依赖Redis≥3.0 📉 时钟漂移风险 |
生产环境
高并发(≥5k/s)
|
ZooKeeper |
🔒 强一致性(CP模型) ⏱️ 无时钟问题 |
📊 性能低(≈1k/s) ⚙️ 部署复杂度高 |
金融交易
强一致性场景
|
Redisson实现详解:
加锁逻辑:
Watchdog机制:后台线程每10秒检查锁状态,若未释放则自动续期(默认30秒)。
可重入锁:同一线程可多次获取锁,计数器+1,释放时计数器-1,归零后删除锁。
代码示例:
RLock lock = redissonClient.getLock("product_lock:" + productId); try { // 尝试加锁,最多等待10秒,锁自动释放时间30秒 boolean locked = lock.tryLock(10, 30, TimeUnit.SECONDS); if (locked) { // 查询数据库并重建缓存 Product product = db.getProduct(productId); redis.setex("product:" + productId, 3600, product); } else { // 降级策略:返回默认库存或排队页面 return new ProductSoldOut(); } } finally { lock.unlock(); }锁续期源码分析:
Redisson通过
Lua脚本原子性续期:if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then redis.call('pexpire', KEYS[1], ARGV[1]); return 1; end; return 0;参数说明:
KEYS[1]为锁Key,ARGV[1]为过期时间,ARGV[2]为客户端ID。
优化策略:
锁分段:将热点Key拆分为多个子锁(如
product_lock:1001_segment1),减少竞争。锁降级:在锁竞争激烈时,返回默认值(如“库存计算中”),异步通知用户。
2️⃣逻辑过期(Logical Expiration)
实现步骤:
缓存数据结构:
{ "value": "真实数据", "expire": 1727830400 // 逻辑过期时间戳 }数据加载逻辑:
public Data getData(String key) { String json = redis.get(key); if (json == null) { return loadFromDb(key); // 缓存未命中,走击穿逻辑 } CacheWrapper wrapper = deserialize(json); if (wrapper.expire < System.currentTimeMillis() / 1000) { // 触发异步更新 executor.submit(() -> reloadData(key)); // 返回旧数据(业务可容忍短暂不一致) } return wrapper.value; }异步更新线程:
private void reloadData(String key) { RLock lock = redisson.getLock(key + ":reload_lock"); try { if (lock.tryLock()) { Data newData = db.load(key); redis.set(key, serialize(newData, newExpireTime())); } } finally { lock.unlock(); } }
适用场景:
读多写少的数据(如商品描述、配置信息)。
容忍秒级数据不一致(如资讯类应用)。
3️⃣混合方案:互斥锁 + 逻辑过期
架构设计:
请求 → 判断逻辑过期 → 过期则获取互斥锁 → 锁获取成功则重建缓存 → 返回新数据
↓
锁获取失败 → 返回旧数据优势:
减少锁竞争:多数请求直接返回旧数据,仅一个线程重建。
保证最终一致性:异步更新数据,避免长时间不一致。
8.1.3 缓存雪崩
问题本质:大量缓存集中失效 或 Redis集群宕机,导致请求洪峰压垮数据库。
典型案例:批量Key设置相同TTL(如每日0点过期);Redis主从切换失败,集群不可用。
核心解决方案:
1️⃣TTL随机化
实现策略:
基础TTL + 随机偏移:如基础过期时间3600秒,随机增加0~600秒。
代码示例:
public void setWithJitter(String key, Object value, int baseTtl, int jitter) { int ttl = baseTtl + new Random().nextInt(jitter); redisTemplate.opsForValue().set(key, value, ttl, TimeUnit.SECONDS); }
数学原理:
指数退避:对批量Key设置不同的基础TTL,如按
2^n间隔(1h, 2h, 4h)。随机分布:通过均匀分布或正态分布分散Key过期时间。
2️⃣多级缓存架构
分层设计:
客户端缓存(Cookie/LocalStorage) → CDN → 本地缓存(Caffeine) → Redis集群 → 数据库各级缓存策略:
客户端缓存:
设置
Cache-Control: max-age=60,减少重复请求。使用ETag实现304 Not Modified响应。
本地缓存:
Caffeine.newBuilder() .maximumSize(10_000) .expireAfterWrite(10, TimeUnit.MINUTES) .build(key -> loadFromRedis(key));Redis集群:
分片策略:Codis或Redis Cluster实现水平扩展。
持久化配置:
appendfsync everysec平衡性能与数据安全。
容灾演练:
模拟Redis宕机,验证本地缓存和数据库限流是否生效。
使用Chaos Engineering工具(如ChaosBlade)注入网络延迟、节点故障。
3️⃣熔断降级
工具集成(Sentinel + Hystrix)微服务中的组件:
Sentinel规则配置:
alibaba: cloud: sentinel: datasource: ds1: nacos: server-addr: localhost:8848 dataId: sentinel-rules rule-type: flow降级策略:
慢调用比例:若数据库慢查询比例超过50%,触发熔断。
异常比例:若数据库异常率超过60%,触发熔断。
兜底数据:
返回默认值(如“服务繁忙,请稍后重试”)。
使用历史缓存数据(如昨日热销榜单)。
8.1.4 方案对比与选型
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 高频无效请求 | RedisBloom + API网关校验 |
✔️ 99.9%无效请求拦截
减少 cache_miss 穿透(降幅>80%)
|
| 热点Key高并发 |
Redisson Lock +
逻辑过期
|
⏳ 锁自动续期(watchdog)
DB QPS 从10万→<5000
|
| 大规模集群 |
TTL抖动 +
多级缓存 +
Sentinel
|
🚨 雪崩风险降低92%
TTL随机范围:±10% base值
|
8.2 分布式锁(Redlock算法、Redisson实现)
8.2.1 分布式锁的核心挑战与需求
分布式锁需满足四大特性:
互斥性:同一时刻仅一个客户端持有锁。
防死锁:锁需设置超时时间,避免客户端故障导致锁永久不可用。
可重入性:同一线程可多次获取同一锁。
持锁人解锁:仅锁持有者能释放锁,防止误删他人锁。
核心挑战:
主从异步复制:主节点宕机后未同步锁数据,导致锁失效。
时钟漂移与网络延迟:影响锁的原子性。
8.2.2 Redlock算法:高可靠集群锁方案
设计目标:解决Redis主从架构下异步复制导致的锁失效问题,通过多节点多数派机制实现强一致性分布式锁。
1️⃣核心原理与流程
算法流程:
时间戳获取:客户端记录初始时间
T1(毫秒精度)。多节点顺序加锁:向N个独立节点(建议N=5)发送加锁命令:
SET lock_key $uuid NX PX $ttl超时控制:每个节点设置短超时(5-50ms),避免单节点阻塞。
多数派验证:若成功加锁节点数 ≥ N/2 + 1(如5节点需≥3),且总耗时 < TTL,则视为获锁成功。
有效时间计算:
实际有效期=TTL−(T2−T1)−时钟漂移实际有效期=TTL−(T2−T1)−时钟漂移时钟漂移:默认忽略,若要求严格需通过NTP同步。
失败处理:向所有节点发送解锁命令,包括未成功加锁的节点。
数学原理:
多数派原则:基于Quorum机制,确保半数以上节点存活即可提供服务。
超时退避:重试间隔采用指数退避算法(初始100ms,最大5s),避免集群拥塞。
2️⃣生产级实现示例(Python)
import redis
import time
import uuid
nodes = [redis.StrictRedis(host=f'node{i}', port=6379) for i in range(5)]
def acquire_lock(lock_key, ttl=10000):
identifier = str(uuid.uuid4())
start_time = time.time() * 1000
success_count = 0
for node in nodes:
try:
if node.set(lock_key, identifier, nx=True, px=ttl):
success_count += 1
except redis.exceptions.RedisError:
continue
elapsed = (time.time() * 1000) - start_time
if success_count >= 3 and elapsed < ttl:
return {'validity': ttl - elapsed, 'identifier': identifier}
else:
for node in nodes:
node.delete(lock_key)
return None
def release_lock(lock_key, identifier):
for node in nodes:
script = """
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end
"""
node.eval(script, 1, lock_key, identifier)关键参数:
N=5:容错能力为 (N-1)/2。
TTL=10s:需大于业务最大处理时间。
3️⃣容错与优化策略
节点崩溃处理:
延迟重启:节点崩溃后需等待TTL时间再重启,防止锁状态冲突。
AOF持久化:配置
appendfsync everysec平衡性能与数据安全。
时钟同步:
使用NTP服务同步节点时间,误差控制在10ms内。
若时钟漂移超过TTL的10%,触发告警并人工介入。
网络分区处理:
熔断机制:检测到分区时拒绝新锁请求,返回降级响应(如“系统繁忙”)。
分区恢复:通过Gossip协议自动合并状态,验证锁持有者有效性。
8.2.3 Redisson:企业级分布式锁实现
Redisson通过Lua脚本和Netty通信,提供自动续期、可重入锁等高级功能。
1️⃣核心功能解析
架构特性:
可重入锁:基于ThreadLocal记录持有计数,支持同一线程多次加锁。
Watchdog机制:后台线程每10秒续期锁有效期(默认30秒),防止业务未完成锁释放。
联锁(MultiLock):原子控制多个独立资源,如订单+库存的跨服务事务。
底层原理:
Lua脚本原子操作:加锁、解锁、续期均通过Lua脚本保证原子性。
-- 加锁脚本(检查锁重入计数)
if redis.call('exists', KEYS[1]) == 0 then
redis.call('hset', KEYS[1], ARGV[2], 1)
redis.call('pexpire', KEYS[1], ARGV[1])
return nil
end-- 解锁脚本(检查线程标识)
if redis.call('hexists', KEYS[1], ARGV[3]) == 1 then
local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1)
if counter == 0 then
redis.call('del', KEYS[1])
end
endPub/Sub监听:锁释放时通过频道通知等待线程竞争。
2️⃣生产配置与代码示例(Spring Boot集成示例)
# application.yml
redisson:
config: |
singleServerConfig:
address: "redis://127.0.0.1:6379"
password: "your_password"
database: 0
lockWatchdogTimeout: 30000 # 看门狗超时时间(ms)public class OrderService {
@Autowired
private RedissonClient redisson;
public void createOrder(String orderId) {
RLock lock = redisson.getLock("order_lock:" + orderId);
try {
boolean acquired = lock.tryLock(5, 30, TimeUnit.SECONDS);
if (acquired) {
processOrder(orderId);
}
} finally {
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
}参数调优:
锁等待时间:电商秒杀设为100ms,后台任务可放宽至5s。
锁有效期:建议为平均业务处理时间的2倍。
8.2.4 方案对比与选型指南
| 维度 | Redlock算法 | Redisson单节点锁 | ZooKeeper锁 |
|---|---|---|---|
| 一致性 |
✔️ 强一致性 (多数派协议) |
最终一致性 (异步复制延迟) |
✔️ 强一致性 (ZAB协议) |
| 性能 |
≈5k QPS (多节点通信开销) |
≈50k QPS (内存操作) |
≈1k QPS (磁盘同步瓶颈) |
| 容错性 |
允许N/2节点故障 (半數存活即可) |
单点故障风险 (依赖单节点可靠性) |
允许N-1节点故障 (半数存活原则) |
| 适用场景 |
✔️ 金融交易
库存扣减
|
✔️ 电商秒杀
配置热更新
|
✔️ 配置管理
分布式选主
|
| 运维成本 |
高 (需3+节点部署) |
低 (单节点维护) |
中 (需ZK集群) |
✒️生产实践:
Redlock:适合强一致性场景(如金融交易),需注意节点部署与时钟同步。
Redisson:适合高并发场景(如秒杀),简化开发且功能完备。
8.3 延迟队列(Sorted Set + Lua)
延迟队列是一种允许任务在指定时间执行的数据结构,广泛应用于以下场景:
订单超时处理:如30分钟内未支付的订单自动取消。
定时消息通知:如用户注册后延迟发送验证邮件。
异步任务调度:如批量数据处理任务在低峰期执行。
核心挑战:
原子性操作:获取任务与删除操作需原子化,避免并发场景下的任务重复执行。
高效轮询:减少无效的Redis查询,降低服务端压力。
持久化与容错:防止Redis宕机导致任务丢失。
8.3.1 基于 Sorted Set 的延迟队列实现
Redis的有序集合(Sorted Set)以时间戳为score,天然支持按时间排序的任务管理。
1️⃣核心流程与命令
添加任务:使用
ZADD将任务执行时间戳作为score,任务ID或JSON数据作为value。ZADD delay_queue <current_timestamp + delay> "task_data" # 示例:延迟5分钟的任务关键参数:
score为当前时间 + 延迟秒数,value需包含任务唯一标识与业务数据。
轮询任务:通过
ZRANGEBYSCORE查询到期任务(score <= 当前时间戳)。ZRANGEBYSCORE delay_queue -inf <current_timestamp> WITHSCORES优化点:结合
LIMIT分页查询,避免单次拉取过多数据。
原子化提取与删除:使用Lua脚本确保查询、删除操作的原子性。
-- KEYS[1]: 队列名称;ARGV[1]: 当前时间戳 local tasks = redis.call('ZRANGEBYSCORE', KEYS[1], '-inf', ARGV[1]) if #tasks > 0 then redis.call('ZREM', KEYS[1], unpack(tasks)) end return tasks优势:Lua脚本在Redis中单线程执行,避免任务被多个消费者重复获取。
2️⃣生产级代码示例(Java + Jedis)
public class RedisDelayedQueue {
private static final String DELAY_QUEUE = "delay_queue";
private Jedis jedis;
// 添加任务
public void addTask(String taskId, long delaySeconds) {
long timestamp = System.currentTimeMillis() / 1000 + delaySeconds;
jedis.zadd(DELAY_QUEUE, timestamp, taskId);
}
// 原子化获取并删除任务(Lua脚本)
public List<String> pollTasks() {
String script =
"local tasks = redis.call('ZRANGEBYSCORE', KEYS[1], '-inf', ARGV[1]); " +
"if #tasks > 0 then redis.call('ZREM', KEYS[1], unpack(tasks)) end; " +
"return tasks";
Object result = jedis.eval(script, 1, DELAY_QUEUE, String.valueOf(System.currentTimeMillis() / 1000));
return (List<String>) result;
}
// 启动轮询线程
public void startPolling() {
ScheduledExecutorService executor = Executors.newSingleThreadScheduledExecutor();
executor.scheduleAtFixedRate(() -> {
List<String> tasks = pollTasks();
tasks.forEach(this::processTask); // 执行任务逻辑
}, 0, 1, TimeUnit.SECONDS); // 每秒轮询一次
}
}关键设计:
Lua脚本预加载:通过
SCRIPT LOAD缓存脚本,减少网络传输开销。任务唯一性:使用UUID作为任务ID,避免重复处理。
3️⃣性能优化与容错机制
高效轮询策略
动态轮询间隔:
根据任务密度调整轮询频率(如任务密集时缩短间隔)。
使用Redis的
BRPOP阻塞读优化,减少空轮询(需结合List结构)。
批量处理:
-- 一次提取最多100条任务 local tasks = redis.call('ZRANGEBYSCORE', KEYS[1], '-inf', ARGV[1], 'LIMIT', 0, 100)
持久化与容错
AOF持久化:配置
appendfsync everysec,平衡性能与数据安全。任务重试机制:
若任务处理失败,重新设置
score为当前时间 + 重试间隔。记录重试次数,超过阈值则标记为死信任务。
8.4 社交应用(关注列表、Feed流)
8.4.1 社交应用的核心需求与挑战
社交应用的核心功能包括 关注列表 和 Feed流,需满足以下需求:
关注列表:
高效存储和查询用户的关注关系(如关注、取关、互相关注)。
支持大规模用户关系链的快速扩展。
Feed流:
实时推送用户关注对象的动态(如发帖、点赞、评论)。
支持个性化排序与分页查询。
核心挑战:
数据量庞大:用户关系与动态数据量可能达到亿级别。
实时性要求高:用户期望动态在发布后秒级可见。
性能与一致性平衡:在保证实时性的同时,避免数据不一致。
8.4.2 关注列表的设计与实现
1️⃣数据结构选择
Set结构:
关注列表:使用
following:{userId}存储用户关注的对象。SADD following:1001 2001 2002 2003 # 用户1001关注用户2001、2002、2003粉丝列表:使用
followers:{userId}存储用户的粉丝。SADD followers:2001 1001 # 用户2001的粉丝包括用户1001查询互相关注:
SINTER following:1001 followers:1001 # 用户1001的好友列表
ZSet结构:
按时间戳排序,支持分页查询最近关注的用户。
ZADD following:1001 <timestamp> 2001
2️⃣性能优化
分片存储:
将大Key拆分为多个子Key(如
following:1001_part1),避免单个Set过大。分片策略:
part = hash(userId) % 10 # 将用户ID哈希分片 SADD following:1001_part{part} 2001
异步更新:
将关注/取关操作写入消息队列(如Kafka),异步更新Redis与数据库。
8.4.3 Feed流的设计与实现
1️⃣推模式(Write Fanout)
核心思想:用户发布动态时,将动态推送到所有粉丝的收件箱。
实现步骤:
发布动态:
LPUSH feed:2001 "post:789" # 用户2001发布动态推送至粉丝收件箱:
for follower in followers:2001: LPUSH feed_inbox:{follower} "post:789"读取Feed流:
LRANGE feed_inbox:1001 0 10 # 用户1001查看最新动态
优点:
读性能高,适合粉丝量小的场景(如普通用户)。
缺点:
粉丝量大的用户(如明星)发布动态时,推送操作耗时较长。
2️⃣拉模式(Read Fetch)
核心思想:用户查看Feed流时,实时拉取关注对象的动态并合并。
实现步骤:
发布动态:
LPUSH feed:2001 "post:789" # 用户2001发布动态读取Feed流:
获取用户关注列表:
SMEMBERS following:1001 # 用户1001关注的KOL列表合并动态并排序:
ZUNIONSTORE tmp_feed 3 feed:2001 feed:2002 feed:2003 ZREVRANGE tmp_feed 0 10 # 按时间倒序取前10条
优点:
写性能高,适合粉丝量大的场景(如明星博主)。
缺点:
读性能较低,需实时合并多个动态列表。
3️⃣混合模式(最佳实践)
核心思想:结合推拉模式优势,根据用户活跃度动态调整策略。
实现步骤:
活跃用户:推模式,实时推送动态至收件箱。
长尾用户:拉模式,按需拉取动态。
个性化排序:
使用ZSet存储动态,
score为动态权重(如时间戳 + 热度值)。ZADD feed:2001 <timestamp + weight> "post:789"
优化点:
动态预取:根据用户行为预测动态热度,提前加载至收件箱。
缓存分页:将Feed流分页结果缓存至Redis,减少重复计算。
✒️方案对比与选型建议:
方案 优点 缺点 适用场景 推模式✔️ 读性能高(≈50k QPS)
⚡ 毫秒级实时推送📉 写性能低(粉丝量×10倍开销)
粉丝量>1万时成本剧增拉模式📈 写性能高(O(1)复杂度)
💾 存储成本可控⏱️ 读延迟高(合并计算耗时)
P99延迟≥200ms混合模式⚖️ 读写性能平衡
🎚️ 支持热度加权排序⚠️ 双写逻辑维护复杂
需处理数据一致性(最终一致)
九、企业级实践
9.1 多级缓存架构(Redis + 本地缓存)
多级缓存通过 本地缓存 与 分布式缓存(Redis) 的组合,提升系统性能与可用性,需满足以下需求:
高性能:减少数据库查询压力,降低响应时间。
高可用:缓存层故障时,系统仍可降级运行。
一致性:保证缓存与数据库数据的一致性。
核心挑战:
缓存穿透:大量请求查询不存在的数据,绕过缓存直击数据库。
缓存雪崩:大量缓存集中失效,导致数据库压力激增。
数据一致性:缓存与数据库之间的数据同步问题。
9.1.1 多级缓存架构设计
架构分层:
客户端缓存:
使用
Cookie或LocalStorage缓存静态资源(如CSS、JS)。设置
Cache-Control头部,减少重复请求。
本地缓存:
使用
Caffeine或Ehcache缓存热点数据,减少Redis查询压力。缓存策略:
Cache<String, Object> localCache = Caffeine.newBuilder() .maximumSize(10_000) // 最大缓存条目数 .expireAfterWrite(10, TimeUnit.MINUTES) // 写入后10分钟过期 .build();
分布式缓存(Redis):
使用Redis缓存全量数据,支持高并发查询。
数据结构选择:
String:缓存简单键值对。
Hash:缓存对象属性。
ZSet:缓存排序数据(如排行榜)。
数据库:
作为最终数据源,保证数据的持久性与一致性。
数据流向:
客户端 → 客户端缓存 → 本地缓存 → Redis → 数据库优势:
减少网络开销:本地缓存拦截80%以上请求,降低Redis压力。
提升响应速度:本地缓存命中时,响应时间降至微秒级。
9.1.2 缓存策略与实现
这部分详细内容参考 8.1
缓存穿透防护:
布隆过滤器:使用RedisBloom模块拦截非法请求。
BF.RESERVE user_ids 0.001 1000000 # 创建布隆过滤器 BF.ADD user_ids 1001 # 添加合法用户ID空对象缓存:对查询结果为空的Key,缓存短时间占位符。
if (data == null) { redis.setex(key, 300, "NULL"); // 缓存空值,TTL=5分钟 }
缓存雪崩防护:
TTL随机化:对批量Key设置基础TTL + 随机偏移。
int ttl = baseTtl + new Random().nextInt(randomRange); redis.setex(key, ttl, value);多级缓存降级:Redis故障时,降级至本地缓存与数据库。
9.1.3 数据一致性
双写策略:更新数据库后,同步更新缓存。
db.update(data);
redis.set(key, data);失效策略:更新数据库后,删除缓存。
db.update(data);
redis.del(key);延迟双删:更新数据库后,先删除缓存,延迟一段时间再删除一次。
db.update(data);
redis.del(key);
executor.schedule(() -> redis.del(key), 1, TimeUnit.SECONDS);9.2 冷热数据分离策略
Redis作为高性能内存数据库,存储容量有限,需通过 冷热数据分离 优化资源利用率,满足以下需求:
高性能:热点数据常驻内存,保证低延迟访问。
低成本:冷数据存储至低成本介质(如磁盘或低性能实例),减少内存占用。
自动化:根据数据访问频率动态迁移冷热数据,降低运维成本。
核心挑战:
数据识别:如何准确区分冷热数据。
迁移效率:冷热数据迁移对性能的影响。
一致性:迁移过程中保证数据一致性。
9.2.1 冷热数据识别策略
基于访问频率:
统计访问次数:使用Redis的
OBJECT命令获取Key的访问频率。OBJECT FREQ <key> # 返回Key的访问频率滑动窗口计数:使用ZSet记录Key的访问时间戳,统计最近N次访问频率。
ZADD access_log <timestamp> <key> # 记录访问时间 ZREMRANGEBYSCORE access_log -inf <timestamp - window> # 清理过期记录 ZCARD access_log # 获取访问次数
基于访问时间:
最近访问时间(LRU):使用Redis的
OBJECT命令获取Key的最后访问时间。OBJECT IDLETIME <key> # 返回Key的空闲时间时间窗口筛选:将长时间未访问的Key标记为冷数据。
if OBJECT IDLETIME <key> > threshold: mark_as_cold(<key>)
基于业务规则:
固定规则:根据业务特性定义冷热数据(如超过30天未访问的订单为冷数据)。
动态规则:根据数据访问模式动态调整冷热数据阈值。
9.2.2 冷热数据迁移策略
数据存储架构:
热数据存储:使用高性能Redis实例(如Redis Cluster)存储热点数据。
冷数据存储:使用低成本介质(如SSD、HDD)或低性能实例(如Redis on Disk)存储冷数据。
迁移实现方式:
手动迁移:通过脚本定期扫描冷数据并迁移至冷存储。
for key in redis.keys(): if is_cold(key): redis.migrate(cold_storage, key)自动迁移:使用Redis模块(如RedisGears)实现自动化迁移。
def migrate_cold_data(): for key in execute('SCAN', 'MATCH', '*'): if execute('OBJECT', 'IDLETIME', key) > threshold: execute('MIGRATE', cold_storage, key)
迁移性能优化:
批量迁移:使用
SCAN命令分批次迁移数据,减少对性能的影响。异步迁移:将迁移任务写入消息队列(如Kafka),异步执行。
压缩存储:对冷数据使用压缩算法(如Snappy、LZ4),减少存储空间。
9.2.3 冷热数据访问策略
热数据访问:
本地缓存:使用
Caffeine或Ehcache缓存热点数据,减少Redis查询压力。缓存预热:根据历史访问记录,提前加载热点数据至Redis。
冷数据访问:
懒加载:访问冷数据时,从冷存储加载至Redis。
Object data = redis.get(key); if (data == null) { data = coldStorage.get(key); redis.set(key, data); }异步加载:访问冷数据时,异步加载至Redis,避免阻塞主线程。
一致性保障:
双写策略:更新数据时,同步写入热存储与冷存储。
失效策略:更新数据时,删除热存储与冷存储的旧数据。
9.3 与数据库的一致性保障(双写、订阅binlog)
在Redis与数据库的混合存储架构中,需确保数据的一致性,满足以下需求:
实时同步:数据库更新后,Redis缓存需及时更新或失效。
数据一致性:避免缓存与数据库之间的数据不一致。
高性能:同步操作对系统性能的影响需最小化。
核心挑战:
双写问题:Redis与数据库的写操作可能失败,导致数据不一致。
同步延迟:Binlog订阅与解析的延迟可能导致缓存与数据库不一致。
并发冲突:高并发场景下,更新操作可能导致数据覆盖或丢失。
9.3.1 双写策略
双写流程:
写数据库:先更新数据库,确保数据持久化。
写Redis:数据库更新成功后,更新Redis缓存。
db.update(data); // 更新数据库 redis.set(key, data); // 更新Redis
双写问题与解决方案:
写数据库成功,写Redis失败——解决方案:重试机制,确保Redis最终更新成功。
int retry = 0; while (retry < MAX_RETRY) { try { redis.set(key, data); break; } catch (Exception e) { retry++; } }写Redis成功,写数据库失败——解决方案:删除Redis缓存,避免脏数据。
try { db.update(data); } catch (Exception e) { redis.del(key); // 删除Redis缓存 throw e; }
双写优化:
异步双写:将Redis写操作异步化,减少对主流程的性能影响。
db.update(data); // 更新数据库 executor.submit(() -> redis.set(key, data)); // 异步更新Redis批量双写:将多个写操作合并为批量操作,提升性能。
db.batchUpdate(dataList); // 批量更新数据库 redis.mset(keyValueMap); // 批量更新Redis
9.3.2 订阅Binlog策略
Binlog订阅流程:
Binlog解析:使用工具(如Canal、Maxwell)订阅数据库Binlog,解析变更事件。
Redis更新:根据Binlog事件更新或失效Redis缓存。
BinlogEvent event = subscribeBinlog(); // 订阅Binlog if (event.getType() == UPDATE) { redis.set(event.getKey(), event.getData()); // 更新Redis } else if (event.getType() == DELETE) { redis.del(event.getKey()); // 失效Redis }
Binlog订阅的优势:
实时性强:Binlog捕获数据库的所有变更,确保Redis与数据库实时同步。
解耦:Redis更新与业务逻辑解耦,降低系统复杂度。
Binlog订阅的优化:
批量处理:将多个Binlog事件合并为批量操作,提升处理效率。
List<BinlogEvent> events = batchSubscribeBinlog(); // 批量订阅Binlog redis.mset(events.stream().collect(toMap(BinlogEvent::getKey, BinlogEvent::getData))); // 批量更新Redis过滤无关事件:只订阅与Redis缓存相关的表或字段,减少无效事件处理。
canal: filter: tables: user, order # 只订阅user和order表
十、Redis常见问题与解决方案
10.1 生产环境问题
10.1.1 内存溢出导致服务崩溃
问题本质:
Redis作为内存数据库,当存储数据量超过可用内存时,会触发OOM(Out Of Memory),导致服务崩溃或拒绝写入请求。常见原因包括:
数据量激增未及时清理
内存碎片率过高(
mem_fragmentation_ratio > 1.5)未配置合理的内存淘汰策略
典型案例:
缓存雪崩:大量Key同时过期,瞬间大量请求穿透到数据库,同时触发缓存重建导致内存激增。
大Key问题:单个Key存储超过10MB的数据(如未分页的用户列表)。
核心解决方案:
内存优化配置:
# 设置最大内存限制(如4GB) config set maxmemory 4gb # 选择LRU淘汰策略 config set maxmemory-policy allkeys-lru内存碎片整理:
# 手动触发内存整理(Redis 4.0+) memory purge # 开启自动碎片整理 config set activedefrag yes大Key拆分:
# 将大Key拆分为多个子Key(如user:1001:friends_part1) hsplit user:1001:friends 1000 # 每部分存储1000条数据
优化策略
监控告警:
# 监控内存使用率 info memory | grep used_memory_human # 监控大Key分布 redis-cli --bigkeys分片集群:使用Redis Cluster分散数据存储压力。
10.1.2 主从同步延迟过高
问题本质:
主从节点因网络延迟、主节点写入压力大或从节点处理能力不足,导致从库复制进度滞后,影响数据一致性。
典型案例:
主节点写入峰值:突发流量导致主节点写入压力激增(如秒杀场景)。
跨地域同步:主从节点部署在不同地域,网络延迟超过100ms。
核心解决方案:
主节点优化:
# 关闭主节点持久化(牺牲可靠性提升性能) config set save "" # 使用无盘复制(Redis 6.0+) config set repl-diskless-sync yes从节点扩容:
# 增加从节点分担读压力 redis-cli --cluster add-node new_slave_ip:port master_ip:port --cluster-slave增量同步优化:
# 使用PSYNC2协议(Redis 4.0+) config set repl-backlog-size 1gb # 增大复制缓冲区
优化策略:
读写分离:将读请求分发到从节点。
// Spring Boot配置读写分离 @Bean public LettuceConnectionFactory redisConnectionFactory() { RedisStaticMasterReplicaConfiguration config = new RedisStaticMasterReplicaConfiguration(masterHost, masterPort); config.addNode(slaveHost, slavePort); return new LettuceConnectionFactory(config); }延迟监控:
# 查看主从延迟(单位:秒) redis-cli -h slave_ip info replication | grep lag # 实时网络延迟检测 redis-cli --latency -h slave_ip
10.1.3 集群节点宕机处理
问题本质:
Redis集群因硬件故障、网络分区或运维误操作导致节点不可用,需快速恢复服务并保证数据完整性。
典型案例:
硬件故障:服务器磁盘损坏或内存故障。
网络分区:集群部分节点因网络中断形成脑裂。
核心解决方案:
自动故障转移:
# Redis Cluster自动切换从节点为主节点(需配置cluster-replica-validity-factor) redis-cli --cluster check cluster_ip:port手动故障处理:
# 移除宕机节点 redis-cli --cluster del-node cluster_ip:port failed_node_id # 添加新节点替换 redis-cli --cluster add-node new_node_ip:port cluster_ip:port数据恢复:
# 从RDB/AOF恢复数据 redis-server --appendonly yes --dbfilename dump.rdb
优化策略:
集群健康检查:
# 定期检查集群状态 redis-cli --cluster check cluster_ip:port # 监控节点存活状态 redis-cli -h node_ip ping备份策略:
# 每日RDB备份 + 每小时AOF增量备份 cron 0 2 * * * redis-cli bgsave cron 0 * * * * redis-cli bgrewriteaof
✒️总结:
问题 推荐方案 适用场景 内存溢出 ✔️ 分片集群 + maxmemory-policy
(推荐allkeys-lru策略)主从同步延迟 读写分离 + PSYNC2协议优化
(同步效率提升40%+)集群节点宕机 Sentinel自动切换 + RDB/AOF备份
故障恢复时间<30s
10.2 开发陷阱
10.2.1 Pipeline与事务的误用
问题本质:
Pipeline和事务是Redis批量操作的两种机制,但误用会导致性能下降或数据不一致:
Pipeline:将多个命令打包发送以提升吞吐量,但不保证原子性,单个命令失败不影响其他命令执行。
事务(MULTI/EXEC):保证原子性,但事务期间其他客户端操作会被阻塞,且不支持回滚(即使某个命令失败,已执行的命令仍会提交)。
典型案例:
Pipeline误用为事务:
Pipeline pipeline = jedis.pipelined(); pipeline.set("key1", "v1"); pipeline.incr("counter"); // 若此命令失败,其他命令仍会执行 pipeline.sync();若
incr命令因类型错误失败,set命令仍会生效,导致数据不一致。事务内执行耗时操作:
MULTI GET large_key # 若large_key为1GB的String,主线程阻塞 EXEC事务内操作会阻塞其他客户端请求,引发高延迟。
解决方案:
明确场景选择:
Pipeline:用于无依赖的批量读写(如缓存预热),需容忍部分失败。
事务:需原子性时使用,但避免事务内包含慢操作。
事务优化:
结合
WATCH实现CAS(Compare and Swap)乐观锁,避免并发冲突:WATCH balance balance = GET balance MULTI SET balance balance - 100 EXECWATCH balance balance = GET balance MULTI SET balance balance - 100 EXEC使用Lua脚本替代事务,保证原子性且无阻塞(Redis单线程执行Lua)。
10.2.2 大量Key过期导致卡顿
问题本质:
Redis通过惰性删除(访问时检查过期)和定期删除(后台任务扫描)清理过期Key。若大量Key集中过期:
定期删除任务:主线程执行,删除耗时过长会阻塞请求处理。
内存碎片激增:频繁删除导致内存不连续,影响新数据写入性能。
典型案例:
缓存雪崩:某促销活动Key设置为1小时后过期,活动结束后大量请求触发被动删除,导致主线程卡顿。
解决方案:
过期时间随机化:
// 原设置:所有Key固定1小时过期 jedis.setex(key, 3600, value); // 优化:添加随机偏移(如±10分钟) int ttl = 3600 + new Random().nextInt(1200) - 600; jedis.setex(key, ttl, value);分批次过期:
按业务维度拆分Key,例如用户会话Key按UID哈希分片,设置不同过期时间。
内存优化:
开启自动内存碎片整理:
config set activedefrag yes config set active-defrag-ignore-bytes 100mb # 碎片超过100MB时触发使用分片集群分散Key分布,降低单节点压力。
10.2.3 频繁连接创建的性能损耗
问题本质:
Redis连接创建涉及TCP握手、认证、协议解析,频繁操作会导致:
CPU资源浪费:每次连接需解析协议(如AUTH、SELECT命令)。
端口耗尽:客户端频繁创建连接可能导致本地端口耗尽(Linux默认端口范围32768-60999)。
典型案例:
循环中创建连接:
for i in range(10000): conn = redis.Redis() # 每次循环新建连接 conn.get(f"key_{i}")该代码产生1万次TCP连接,耗时约2秒(实测QPS从5万降至500)。
解决方案:
连接池化:
Jedis配置示例(Java):
JedisPoolConfig config = new JedisPoolConfig(); config.setMaxTotal(100); // 最大连接数 config.setMaxIdle(20); // 最大空闲连接 JedisPool pool = new JedisPool(config, "redis-host", 6379); try (Jedis jedis = pool.getResource()) { jedis.get("key"); }参数调优:
testOnBorrow=true:借出连接时校验可用性。maxWaitMillis=200:获取连接超时时间(ms)。
长连接复用:
使用HTTP/2或gRPC等支持多路复用的协议,单连接处理多请求。
避免在事务或Pipeline中混用连接(不同线程操作同一连接会导致协议混乱)。
✒️总结:
陷阱 推荐方案 适用场景 Pipeline与事务误用 ✔️ Lua脚本+ ⚡ 无状态Pipeline
(原子操作替代事务,批量命令≤100条)大量Key过期卡顿 ⏲️ TTL随机化 + MEMORY PURGE
(±10%基础值,碎片率>1.8触发)频繁连接性能损耗 🏊 连接池 + maxActive/maxIdle调优
(建议配置:maxActive=500, maxIdle=50)
十一、Redis面试题解析
11.1 高频面试题
11.1.1 Redis为什么快?
Redis的高性能源于其多维度架构设计,核心原因如下:
内存操作:数据完全存储在内存中,避免磁盘I/O瓶颈,读写速度可达10万次/秒以上。
单线程模型:
避免多线程上下文切换和锁竞争开销,简化代码逻辑。
单线程处理网络I/O和命令执行,保证原子性操作(如Lua脚本)。
注意:Redis 6.0引入多线程处理网络I/O,但命令执行仍为单线程。
高效数据结构:
动态字符串(SDS)、压缩列表(ziplist)、跳跃表(skiplist)等,优化内存使用和查询效率。
Hash和ZSet等结构支持快速范围查询和排序。
I/O多路复用:
基于Reactor模式,通过epoll/kqueue监听多个Socket事件,单线程高效处理高并发连接。
11.1.2 持久化机制如何选择?
Redis提供RDB和AOF两种持久化方式,需结合业务场景选择:
| 机制 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| RDB |
✔️ 快照文件紧凑
恢复速度极快(≈GB/秒)
⚡ 后台fork子进程
(性能波动<5%)
|
⚠️ 数据丢失风险
(最多丢失5分钟数据)
📉 大数据fork耗时
(50GB数据 fork≈2s)
|
✔️ 数据备份 ✔️ 容灾恢复 (每日全量备份场景) |
| AOF |
✔️ 数据强安全
秒级持久化(appendfsync everysec)
🔧 误操作修复
(支持FLUSHALL回滚)
|
⚠️ 文件体积大
(比RDB大2-5倍)
⏳ 恢复速度慢
(10GB数据≈5分钟)
|
✔️ 金融交易 ✔️ 实时日志 (要求零数据丢失) |
最佳实践:
混合持久化(Redis 4.0+):结合RDB快照和AOF增量日志,重启时先加载RDB再重放AOF。
配置建议:
# RDB配置(每小时保存一次) save 3600 1 # AOF配置(每秒同步) appendfsync everysec
11.1.3 如何实现分布式锁?
分布式锁需满足互斥性、防死锁、可重入性等特性,常见实现方案:
基于Redis的单机锁:
核心命令:
SET key $uuid NX PX 30000(NX表示互斥,PX设置超时)。缺陷:主从切换可能导致锁失效。
RedLock算法:
向N个独立节点(建议5节点)发起加锁请求,半数以上成功且总耗时小于锁有效期时视为成功。
代码示例:
# 获取锁(需校验时间漂移) success_nodes = [node.set(key, uuid, nx=True, px=ttl) for node in nodes] if len(success_nodes) >= 3 and elapsed_time < ttl: return lock
Redisson实现:
自动续期(Watchdog机制),默认每10秒延长锁有效期。
可重入锁:通过ThreadLocal记录锁持有计数。
对比选型:
单机锁适合低并发场景,RedLock适合强一致性场景,Redisson适合企业级复杂需求。
11.1.4 缓存与数据库双写一致性方案
高并发场景下,缓存与数据库同步需权衡性能与一致性:
先更新数据库,再删除缓存(推荐):
流程:更新数据库 → 2. 删除缓存 → 3. 延迟双删(防止旧数据回写)。
代码示例:
db.update(data); redis.del(key); // 延迟1秒再次删除(异步线程执行) executor.schedule(() -> redis.del(key), 1, TimeUnit.SECONDS);
订阅数据库Binlog:使用Canal监听数据库变更,异步更新缓存,实现最终一致性。
本地缓存降级:更新数据库后,本地标记缓存失效,后续请求穿透到数据库并重建缓存。
对比:
| 方案 | 一致性强度 | 性能影响 | 复杂度 |
|---|---|---|---|
| 延迟双删 |
最终一致性 (窗口期≤1s,依赖二次删除) |
↓ 低延迟(≈2ms) 写操作增加30%吞吐 |
中等 需维护延迟队列+重试机制 |
| Binlog订阅 |
强一致性 (基于数据库事务日志) |
↔ 中(同步延迟<100ms) 解析binlog消耗15% CPU |
高 需部署Canal/Maxwell中间件 |
| 本地缓存降级 |
弱一致性 (TTL过期后更新) |
↑ 读性能提升5倍 但可能返回陈旧数据 |
低 客户端集成即可实现 |
11.1.5 集群数据分片原理
Redis Cluster通过虚拟哈希槽实现数据分片,核心机制:
哈希槽分配:
预分配16384个槽位,键通过CRC16哈希后取模(
slot = CRC16(key) % 16384)分配到槽。每个节点负责部分槽范围(如节点A:0-5500,节点B:5501-11000)。
动态扩缩容:
添加节点时,从现有节点迁移部分槽到新节点。
删除节点时,将槽迁移至其他节点后下线。
请求路由:
客户端直连任意节点,若Key不在当前节点,返回MOVED错误并重定向。
Smart Client(如JedisCluster)缓存槽与节点映射关系,减少重定向次数。
优势:
无中心化架构,支持水平扩展。
数据分片均匀,避免热点问题。
11.2 进阶问题
11.2.1 Redis多线程演进(6.0的I/O多线程)
Redis 6.0引入多线程的核心目标是解决网络I/O瓶颈,而非命令执行的并行化。在高并发场景下,单线程处理网络读写可能成为性能瓶颈,尤其是在小包高频请求中。其改进包括:
I/O多线程化:
主线程负责接收连接、分发任务,多个I/O线程处理网络数据的读取与写入,但命令执行仍由主线程单线程处理,避免并发安全问题。
线程模型:主线程将连接通过轮询(Round Robin)分配给I/O线程,并阻塞等待I/O线程完成读写操作。
性能提升:
实测显示,启用多线程后,GET/SET操作的QPS可提升至单线程的2倍以上。
官方建议线程数不超过CPU核心数(如8核机器设置6线程),避免线程切换开销。
核心机制与注意事项:
配置参数:
Bashio-threads-do-reads yes # 开启I/O多线程 io-threads 6 # 设置线程数(建议为CPU核数的75%)适用场景:
适合高并发、网络I/O密集场景(如电商秒杀)。
数据操作简单(如GET/SET),避免复杂事务或Lua脚本阻塞主线程。
11.2.2 Redis与Memcached的详细对比
| 维度 | Redis | Memcached |
|---|---|---|
| 数据类型 |
支持String、List、Hash、Set、ZSet等复杂结构 |
仅支持简单的Key-Value存储 |
| 持久化 | 支持RDB快照和AOF日志,可恢复数据 |
内存驻留,重启后数据丢失 |
| 内存管理 |
动态内存分配,支持LRU/LFU淘汰策略 |
Slab预分配固定块,减少碎片但可能浪费空间 |
| 线程模型 |
🧵 单线程执行 |
🔀 多线程模型 |
| 适用场景 |
✔️ 分布式锁
✔️ 实时排行榜
✔️ 消息队列
|
✔️ 简单缓存 |
| 性能 |
⚡ 10万/秒 OPS 复杂操作耗时↑30% |
⚡ 50万/秒 OPS 纯KV读取快3-5倍 |
选型建议:
选择Redis:
需要持久化、复杂数据结构、分布式锁或消息队列的场景(如电商订单系统)。
选择Memcached:
仅需高性能缓存且数据量小(如静态页面缓存),或对多线程扩展要求极高。
11.2.3 Redis在微服务架构中的角色
缓存加速:
热点数据缓存:将数据库查询结果缓存至Redis,减少数据库压力(如用户信息缓存)。
示例代码:
user_data = redis.get(f"user:{user_id}") if not user_data: user_data = db.query_user(user_id) redis.setex(f"user:{user_id}", 3600, user_data) # 缓存1小时
分布式锁:
使用
SET key $uuid NX PX实现跨服务资源互斥访问(如库存扣减)。示例代码:
if redis.set("lock:order", uuid, nx=True, ex=30): try: update_stock() finally: redis.delete("lock:order")
消息队列:
利用List或Stream结构实现异步任务处理(如订单状态更新通知)。
数据共享与一致性:
通过Pub/Sub机制实现服务间实时数据同步(如配置中心更新)。
十二、生态与未来发展
12.1 周边工具
Redis Desktop Manager:
功能:跨平台可视化工具,支持键值管理、Stream数据类型、命令自动提示及SSL加密。
优势:界面简洁,支持按命名空间展示Key,但需付费(约200元/年)。
替代方案:
Medis:免费工具,支持模糊搜索和渐进式SCAN,但缺少Stream类型支持。
Another Redis Desktop Manager:开源免费,支持集群管理和暗黑主题,适合基础场景。
RedisInsight:官方工具,支持集群监控、内存分析及SSL连接,适合企业级需求。
开发与运维工具:
redis-rdb-tools:Python实现的RDB分析工具,快速定位BigKey和内存倾斜问题。
CacheCloud:开源Redis云管理平台,支持自动部署Standalone、Sentinel和Cluster架构。
Redis Exporter:Prometheus监控插件,实时采集QPS、内存使用等指标。
12.2 社区与学习资源
官方资源:
Redis官方文档:涵盖数据结构、集群配置、持久化等核心内容,建议作为入门首选。
RedisConf会议:年度技术峰会,分享最新特性与最佳实践(如2023年重点讨论AI集成)。
推荐书籍:
《Redis设计与实现》(黄健宏):深入源码解析数据结构、持久化与集群原理,适合进阶学习。
《Redis实战》(Josiah Carlson):从缓存设计到分布式锁实战,案例丰富。
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝
