


















用 OpenAI Realtime API 打造语音控制机器人:从 RDK X5 到 ES02 的全链路实现
一、引言:让机器人听懂人类语言
在今天,消费级机器人已经不再是高门槛的研究设备,而是越来越多进入教育、娱乐、交互甚至陪护等实际场景。各类开发套件如轮式底盘、四足机器人、机械臂等不断涌现,让硬件层的门槛大幅降低。
但问题也随之而来:我们该如何更自然地与机器人沟通?
1.1 传统控制方式的限制
目前绝大多数机器人仍依赖以下几种方式进行控制:
| 控制方式 | 优点 | 局限性 |
|---|---|---|
| 📡 遥控器 | 简单直接,硬件成本低 | 功能受限、操作复杂、动作表达能力弱 |
| 📱 蓝牙 / APP | 体验现代,UI 更友好 | 依赖手机、网络延迟、不适合实时反馈 |
| 🧾 动作脚本 | 灵活可编程,便于批量自动化控制 | 对普通用户不友好,部署与调试复杂 |
| ⌨️ 语音离线模块 | 语音控制初步尝试 | 精度低、识别范围小、词库固定、无法理解语义 |
| Control Method | Advantages | Limitations |
|---|---|---|
| 📡 Remote Control | Simple and low hardware cost | Limited functions, complex to operate, poor expressiveness |
| 📱 Bluetooth / Mobile App | Modern experience with user-friendly UI | Depends on phone, network delay, not ideal for real-time feedback |
| 🧾 Motion Scripts | Programmable and suitable for batch automation | Unfriendly for general users, complex deployment/debugging |
| ⌨️ Offline Voice Module | Initial attempt at voice control | Low accuracy, small vocabulary, limited understanding of intent |
这些方案各有优劣,但都面临一个共同问题:
人与机器人之间仍然“语言不通”——它们无法真正听懂人类自然语言的含义。
我们希望的,不是“按按钮让机器人前进”,而是“说一句话,机器人就知道要怎么做”。
1.2 为什么是语音 + AI + 实时
“让机器人听懂你说话”,意味着需要三个关键能力:
准确识别人类说了什么(语音识别)
理解这句话的语义或动作意图(自然语言理解)
将意图翻译为可执行的动作控制(硬件驱动)
而以往我们面临的挑战:
要么是语音识别质量低(尤其是支持多语言)
要么无法直接把语义转为可执行函数(缺乏结构化输出)
要么延迟过高、部署复杂,不适合嵌入式设备
1.3 本项目如何突破瓶颈?
在本项目中,我们提出了一个完整的闭环解决方案,将“语音识别 → 动作理解 → 实际执行”打通为一个自动化流程:
利用 OpenAI 最新发布的 Realtime API:实现实时语音收发 + 动作函数调用
基于 RDK X5 开发板:一个既支持音频采集、又可联网、还能运行 Python 的小型 Linux 计算平台
结合 ES02 步态机器人:通过串口控制,执行各种动作,如前进、转向、起立、蹲下等
整个系统实现了:
🎤 你说一句话 → 🧠 云端识别理解 → 🔧 串口命令发出 → 🤖 机器人动作执行
无需训练、无需提前设定语音命令词表,支持中英文混合、多语言自动识别、低延迟交互,而硬件成本保持在 100 美元以内,具备极高性价比。
1.4 本文将带你了解……
本项目是一个完全可复现的语音机器人方案,本文将详细讲解:
项目实际效果演示(中英文双语实时控制)
整体系统架构与软硬件模块介绍
开发板选型理由与成本分析
从部署到运行的每一步(无需复杂配置)
最后为开发者准备了完整模块的代码解构讲解
不管你是:
想低成本打造自己的语音机器人
想了解 OpenAI Realtime API 实际落地方式
还是想学习嵌入式 AI 应用的整合思路
都可以从本项目中找到适合自己的内容。
快速开始提示:如果你只想直接上手体验,跳过原理讲解和系统分析,请直接跳转至 第 4 章「部署运行:从 GitHub 到上电控制」,你将在那里找到完整的安装步骤、依赖配置和运行方法。
二、项目演示效果与基本原理
在技术方案展开前,先来看本项目达成了什么样的效果。通过结合语音识别、函数调用与实时控制,我们成功实现了一个支持自然语言交互、中英文识别、实时反应的机器人语音控制系统。无论是“Turn left” 还是 “站起来”,机器人都能准确理解并做出相应动作,达成类人交互体验。整个系统无需屏幕、无需遥控,靠的仅仅是一句“话”。
2.1 演示效果
本项目的核心演示视频如下:
在项目视频中,我们通过语音控制机器人完成以下核心动作:
| 语言 | 用户语音命令 | 实际动作效果 |
|---|---|---|
| 英文 | "Turn left" | 向左转弯(小角度旋转) |
| 英文 | "Rotate" | 原地连续旋转 |
| 英文 | "Stand up" | 机器人站立,提升高度 |
| 中文 | “向右转” | 向右转弯 |
| 中文 | “转圈” | 原地连续旋转 |
| 中文 | “站起来” / “蹲下去” | 对应上下移动动作 |
| Language | User Voice Command | Actual Robot Behavior |
|---|---|---|
| English | "Turn left" | Turn left (small angle rotation) |
| English | "Rotate" | Spin in place continuously |
| English | "Stand up" | Stand up, raise the body |
| Chinese | “向右转” | Turn right |
| Chinese | “转圈” | Spin in place continuously |
| Chinese | “站起来” / “蹲下去” | Corresponding upward/downward motion |
从演示可以看出,系统不仅能实现高准确率的语音识别,还能解析语义并正确映射为机器指令。更重要的是,所有命令都通过自然语言说出,完全脱离遥控器或屏幕交互。此外,还演示了同一会话中切换语言,系统依旧能正确识别和响应的多语言处理能力。
2.2 整体系统流程图解
为实现如此自然的控制体验,我们构建了一整套软硬件协同体系。以下是项目完整的技术流程概览图:
【语音输入】 → 【RDK X5采集音频】 → 【发送至 OpenAI Realtime API】
↓
【OpenAI 实时转写 + 意图识别 + Function 调用】
↓
【生成结构化动作指令】 → 【本地 Python 模块解析】
↓
【生成串口控制通道值】 → 【通过 SBUS 协议发送到 ES02 控制板】
↓
【机器人执行物理动作】 → 【反馈完成】你说一句话之后,整个系统会在短时间内完成以下事情:
采集语音 → 上传云端
实时识别 + 意图理解
判断是否触发动作(function calling)
生成执行参数,如方向、角度、高度等
经串口发出命令 → 控制机器人动作
三、系统架构总览(软硬件协同)
实现一个真正「能听懂人说话」的机器人,不仅仅依赖强大的 AI 模型,更要求软硬件之间的高效协同。本节将从两大层面深入讲解本项目的架构:
硬件结构设计:为什么我们选择 RDK X5?机器人如何响应动作?
软件模块职责分工:每段代码的功能定位与协作流程
3.1 硬件结构:RDK X5 + ES02 打造软硬一体化闭环系统
3.1.1 项目背景需求分析
一个语音控制机器人系统,至少需要满足以下几点硬件要求:
| 功能目标 | 对硬件的要求 |
|---|---|
| 实时语音输入与识别 | 支持麦克风接入、具备网络连接 |
| 语义理解与函数调用 | 可运行 Python、OpenAI SDK 等现代软件栈 |
| 实时控制底层电机 / 关节 | 提供稳定的串口通信,支持周期性控制信号输出 |
| 性价比高,适合个人开发者或教育应用 | 成本控制在 $100 内,部署简单 |
| Functional Goal | Hardware Requirements |
|---|---|
| Real-time voice input & recognition | Supports microphone input and internet connection |
| Semantic understanding & function calling | Capable of running Python and modern frameworks like OpenAI SDK |
| Real-time control of motors/joints | Stable serial communication and periodic signal output support |
| Cost-effective for makers or educational use | Under $100 budget, easy to deploy |
3.1.2 为什么最终选择 RDK X5?
我们对市面主流的三个开发平台进行测试与对比,结果如下:
| 项目 | Product A + AI Hat | Product B | ✅ RDK X5 |
|---|---|---|---|
| AI 加速模块 | ❌ 需单独购买 | ✅ 内建 BPU | ✅ 内建轻量级 BPU |
| 成本预算 | 💰 > $200 | 💰 > $150 | 💰 < $100(含 AI) |
| 音频支持 | ❌ 需额外 USB 声卡 | ✅ 自带音频接口 | ✅ 自带 3.5mm 麦克风接口 |
| 系统支持 | ✅ Raspbian / Ubuntu | ❌ 封闭 SDK,兼容性较差 | ✅ 原生 Ubuntu + Python 环境 Notice: 如果是商业化用途要使用 license 版本的 Ubuntu |
| 外设拓展 | ✅ GPIO 资源丰富 | ❌ 受限 | ✅ USB / GPIO 齐全 |
| 推荐指数 | ⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐⭐ |
| Item | Product A + AI Hat | Product B | ✅ RDK X5 |
|---|---|---|---|
| AI Acceleration Module | ❌ Must be purchased separately | ✅ Built-in BPU | ✅ Built-in lightweight BPU |
| Cost Estimate | 💰 > $200 | 💰 > $150 | 💰 < $100 (including AI) |
| Audio Support | ❌ Requires additional USB sound card | ✅ Built-in audio interface | ✅ Built-in 3.5mm microphone interface |
| System Support | ✅ Raspbian / Ubuntu | ❌ Closed SDK, poor compatibility | ✅ Native Ubuntu + Python environment Notice: For commercial use, a licensed version of Ubuntu must be used |
| Peripheral Expansion | ✅ Rich GPIO resources | ❌ Limited | ✅ Complete USB / GPIO |
| Recommendation Rating | ⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐⭐ |
综合考虑成本、音频能力、AI API 支持度与部署易用性,RDK X5 是最优之选。
系统硬件由四个主要部分组成:RDK X5 主控板、ES02 机器人底盘、音频接口、串口
/dev/ttyS1通信
3.2 软件模块分工:三层解耦,职责明确
为了让系统具备良好的可维护性与可拓展性,项目采用三层架构,分别对应输入处理、语义转译、底层执行三步。
3.2.1 模块结构概览
| 模块名 | 关键职责 |
|---|---|
| Realtime.py | 建立与 OpenAI 的 WebSocket 实时通道,处理音频、函数调用 |
| ES02_def_function.py | 将动作意图转化为控制通道值,封装成语义→控制的中间层逻辑 |
| sbus_out.py | 负责串口通信(使用 SBUS 协议),将控制值发送到硬件控制板 |
| Module Name | Main Responsibility |
|---|---|
| Realtime.py | Establishes real-time WebSocket connection with OpenAI, handles audio and function calls |
| ES02_def_function.py | Converts high-level action intent into control channel values; serves as semantic-to-control layer |
| sbus_out.py | Handles serial communication via SBUS protocol, sending control values to the hardware board |
3.2.2 模块职责详解
📡 Realtime.py – 智能控制大脑
调用 OpenAI 实时 API,上传语音流并监听返回函数调用
解析识别结果并判断是否为
function_call如果匹配预定义动作函数,则调用
move_robot(action, value)支持多线程音频处理、WebSocket 双向通讯、实时日志输出
⚙️ ES02_def_function.py – 动作中间层转换器
封装机器人动作控制逻辑:
advance()、retreat():控制前进后退left_rotation()、right_rotation():小角度方向调整rotate():原地连续旋转leg_length():调节高度实现站立与蹲下
控制逻辑为「设定通道 → 等待 X 秒 → 自动还原为中值」
启动后台线程,定时将超时通道自动归中(动作中止)
🔌 sbus_out.py – 串口底层发送器
初始化串口
/dev/ttyS1,设为 100000bps将 16 个通道的控制值使用
encode_sbus()函数编码成字节流每秒 42 次通过串口发送该字节流,驱动 ES02 运动控制模块
3.2.3 为什么使用 OpenAI Realtime API?
相比传统的语音识别 + 控制系统,本项目引入的 OpenAI Realtime API 带来了核心结构上的简化与用户体验的质变。
🚫 传统方案的链式复杂流程
语音输入 → 语音识别(Whisper / Google) → 文本输出 → NLP 分析 → 匹配控制命令 → 调用动作函数这个过程中,语义理解与控制逻辑完全割裂,需要多个中间步骤手动粘合,导致:
| 问题点 | 描述 |
|---|---|
| ⏱️ 延迟高 | 等待语音采集完成后整体上传,响应时间通常超过 2 秒 |
| 🎛️ 拆解复杂 | 多个模块分离,需要开发者自行维护 NLP → 控制函数的中间映射逻辑 |
| 🧩 多语言切换繁琐 | 多数 API 需指定语言参数,无法在单会话中流畅切换中英文 |
| 🔌 缺乏函数触发机制 | 返回的是纯文本,无法自动关联具体函数,需手动解析意图再调用控制代码 |
| Issue | Description |
|---|---|
| ⏱️ High Latency | Speech must be fully recorded before uploading; response time often exceeds 2 seconds |
| 🎛️ Complex Pipeline | Modules are decoupled; developers must maintain their own NLP → control mapping logic |
| 🧩 Manual Language Switching | Most APIs require pre-set language, making smooth bilingual interaction difficult |
| 🔌 No Native Function Trigger | Returns plain text only; developers must manually parse intent and call control functions |
✅ OpenAI Realtime API 带来的革新
语音输入 → OpenAI Realtime API → 实时识别 + Function Calling → 自动触发动作函数借助 GPT 的 function calling 能力,整个语音控制流程被高度整合。核心优势包括:
| 优势 | 说明 |
|---|---|
| ✅ 实时性 | 支持 WebSocket 音频流,用户“边说边识别”,响应延迟低至 300ms 内 |
| ✅ 自动触发函数 | 支持 function_call 机制,无需开发者额外构建 NLP + 控制映射逻辑 |
| ✅ 多语言自动识别 | 中英文混说无压力,完全不需要切换语种参数 |
| ✅ 可拓展性强 | 支持自定义扩展更多函数,例如视觉模块、图像反馈等 |
| Advantage | Description |
|---|---|
| ✅ Real-time Performance | Supports WebSocket audio streaming, enabling “speech-as-you-go” with response latency under 300ms |
| ✅ Automatic Function Triggering | Built-in function_call support removes the need for separate NLP-to-control logic |
| ✅ Multilingual Recognition | Seamlessly handles both Chinese and English without language switching |
| ✅ High Extensibility | Allows developers to define custom tools like vision modules and image feedback |
四、部署运行:从 GitHub 到上电控制(适合通用用户)
本节将引导你从项目源码获取、环境配置,到机器人正常响应语音指令的完整部署流程。即使你并非专业开发者,只要按照以下步骤执行,也能快速让机器人“听懂你说话”。
4.1 克隆代码 / 准备运行文件
首先,将项目源代码部署至 RDK X5(或其他兼容设备)。
方式一:Git 克隆(推荐)
git clone https://github.com/fuwei007/Navbot-ES02/tree/main/src/RDK_X5方式二:手动拷贝
从 GitHub 下载源码压缩包,解压并通过
scp或 U 盘拷贝到 RDK X5 的某个目录。
4.2 安装运行环境依赖
在 RDK X5 的终端中,运行以下命令安装所需依赖:
pip install openai websocket-client pyaudio python-dotenv pyserial4.3 配置 .env 环境变量文件
OPENAI_API_KEY=sk-proj-xxx
ADVANCE_DEFAULT_VALUE=10
RETREAT_DEFAULT_VALUE=10
LEFT_ROTATION_DEFAULT_VALUE=90
RIGHT_ROTATION_DEFAULT_VALUE=90
LEG_LENGTH_DEFAULT_VALUE=54.4 启动主程序
在确认麦克风接入正常的前提下,启动主程序:
python Realtime.py启动后程序将自动完成:
初始化麦克风采集
建立 WebSocket,连接 OpenAI Realtime API
实时监听语音 → 自动识别指令 → 执行动作
🎉 到这里部署就完成了。你可以对机器人说出:“向前走”、“转个圈”、“蹲下”,它会准确响应!如果想要了解代码实现细节,可以继续阅读本文章。
五、完整代码实现结构与逻辑详解
5.1 模块一:Realtime.py(语音识别与 API 调度)
Realtime.py 是系统的大脑中枢,负责音频输入、实时识别、事件解析和函数调用。通过 WebSocket 与 OpenAI Realtime API 建立持续通信,边说边识别,边识别边控制。
主要函数与逻辑:
| 函数名 | 功能 |
|---|---|
connect_to_openai() |
建立与 OpenAI Realtime API 的 WebSocket 长连接,启动发送和接收线程。 |
send_mic_audio_to_websocket(ws) |
音频发送线程:实时从麦克风获取音频数据,Base64 编码后以 JSON 形式发送给 OpenAI。 |
receive_audio_from_websocket(ws) |
接收返回的音频数据和事件消息,如语音识别完成、函数调用请求等。 |
handle_function_call(event_json, ws) |
接收到函数调用请求后,解析 action/value 参数,并调用 move_robot() 进行动作转发。 |
send_fc_session_update(ws) |
向 OpenAI 发送 session 配置,包括使用的工具函数列表、语言设定、行为限制等。 |
move_robot(action, value) |
根据 action(如 advance、left_rotation 等)调用 ES02 控制层的具体动作函数。 |
| Function Name | Description |
|---|---|
connect_to_openai() |
Establishes a WebSocket connection to OpenAI Realtime API and starts the send/receive threads. |
send_mic_audio_to_websocket(ws) |
Audio sending thread: continuously reads audio from the microphone, base64-encodes it, and sends via JSON to OpenAI. |
receive_audio_from_websocket(ws) |
Receives response audio and event messages from OpenAI, such as final transcripts or function calls. |
handle_function_call(event_json, ws) |
Parses incoming function_call events and dispatches actions using move_robot(). |
send_fc_session_update(ws) |
Sends session-level configuration to OpenAI including function list, language hints, and behavioral settings. |
move_robot(action, value) |
Triggers corresponding low-level action (e.g., advance, left_rotation) by calling ES02 control functions. |
函数执行流程:
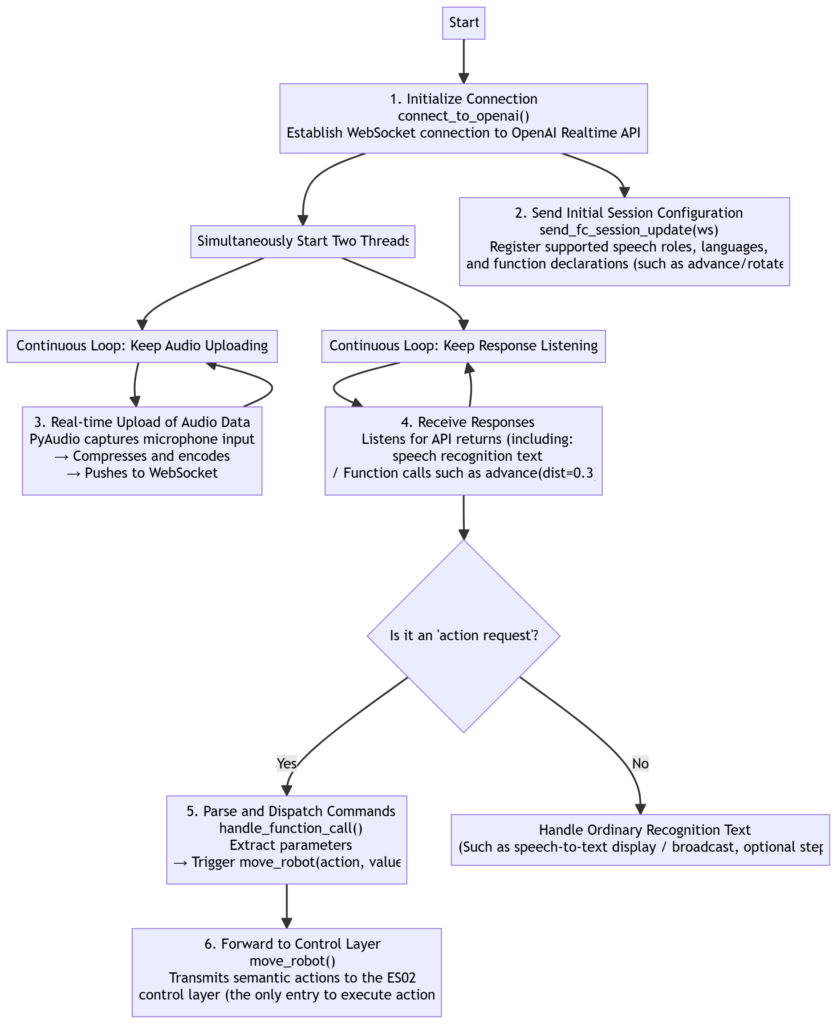
初始化连接:
connect_to_openai()创建 WebSocket 并连接 OpenAI 实时 API。同时启动两个线程:
音频上传线程
send_mic_audio_to_websocket(ws)结果接收线程
receive_audio_from_websocket(ws)
发送初始会话配置:
send_fc_session_update(ws)向 OpenAI 注册本次会话支持的语音角色、使用语言、函数声明(如 advance、rotate 等)。
实时上传音频数据:
send_mic_audio_to_websocket()通过 PyAudio 捕获麦克风输入,实时压缩编码后,通过 WebSocket 推送至 API。
接收语音识别 & 动作请求:
receive_audio_from_websocket()不断监听 API 返回:普通语音识别文本
function_call(如
advance(dist=0.3))
分发指令到动作函数:
一旦解析出动作请求,调用
handle_function_call()提取参数并触发move_robot(action, value)。
动作转发给控制层:
move_robot()是整个模块唯一直接“执行动作”的函数,负责将语义动作传递给 ES02 控制层(动作中间层)。
5.2 模块二:ES02_def_function.py(动作控制逻辑)
负责将高层语义(如“前进 1 米”)映射为底层控制通道变化,完成动作函数封装与定时恢复。是语义与物理控制之间的桥梁。
动作函数一览:
| 函数名 | 功能描述 |
|---|---|
advance(dist) |
向前移动(通道2 → 高值),持续时间随距离线性缩放。 |
retreat(dist) |
向后移动(通道2 → 低值),与前进逻辑相同。 |
left_rotation(angle) |
左转(通道3 → 低值),角度换算为持续时间。 |
right_rotation(angle) |
右转(通道3 → 高值),同上。 |
leg_length(length) |
调节高度(通道1 → 1000 ± Δ),Δ 为长度映射的偏移值。 |
| Function | Description |
|---|---|
advance(dist) |
Move forward (Channel 2 → high value), duration scales linearly with distance. |
retreat(dist) |
Move backward (Channel 2 → low value), same logic as advance. |
left_rotation(angle) |
Turn left (Channel 3 → low value), angle maps to active duration. |
right_rotation(angle) |
Turn right (Channel 3 → high value), same principle as left. |
leg_length(length) |
Adjust leg height (Channel 1 → 1000 ± Δ), where Δ is a mapped offset from length. |
辅助线程与机制:
start_ES02_ch_timing_processing_thread():启动通道自动复位线程,避免动作卡死ch_timing_thread():每 100ms 检查一次通道保持时间,自动还原为中值(1000)
5.3 模块三:sbus_out.py(底层串口发送)
负责将上层设置的通道值通过 SBUS 协议编码,并以 42Hz 频率通过串口 /dev/ttyS1 发送给机器人控制板。
核心函数:
| 函数名 | 说明 |
|---|---|
encode_sbus(channels) |
将 16 个通道的整型值编码为 SBUS 字节格式,共 25 字节。 |
sbus_output() |
持续运行循环线程,每次取最新通道值 → 编码 → 串口发送。 |
start_output_thread() |
启动一个守护线程,运行 sbus_output()。 |
| Function | Description |
|---|---|
encode_sbus(channels) |
Encodes 16 channel integer values into SBUS byte format, total 25 bytes. |
sbus_output() |
Continuously runs a loop: fetch latest channel values → encode → send via serial port. |
start_output_thread() |
Starts a daemon thread that executes sbus_output(). |
协议说明:
串口:100000 bps,EVEN 校验,2 stop bits
帧频:42 Hz(每秒更新 42 次控制指令)
通道初始化值:
[333, 333, ...],控制通道中位为 1000
六、常见问题与优化建议
在开发和运行语音控制机器人系统的过程中,可能会遇到一些技术问题或性能瓶颈。本章整理了常见故障场景及应对策略,并提出一些值得探索的进阶优化方向,帮助你提升系统的稳定性和交互质量。
6.1 连接失败或超时
问题现象:
程序卡在 WebSocket 连接阶段;
报错如
handshake failed、Temporary failure in name resolution;或者服务端没有响应,连接超时。
原因分析:
网络环境限制,无法访问 OpenAI API;
使用 IPv6 网络而服务端不支持;
API key 配置错误或缺失;
忘记设置请求头中的 Authorization 字段。
解决建议:
确认
.env文件中OPENAI_API_KEY配置正确,格式应为以sk-开头的密钥;检查是否使用了代理或 VPN,必要时设置
http_proxy/socks_proxy环境变量;使用
create_connection_with_ipv4()强制 WebSocket 使用 IPv4 连接;可添加重试机制,以应对偶发性网络故障。
6.2 音频卡顿或延迟
问题现象:
播放的语音响应断断续续;
用户说话时识别不完整或被截断;
控制动作响应慢,甚至丢失命令。
原因分析:
队列堆积,线程处理速度跟不上;
frames_per_buffer太小或太大导致音频分块异常;播放缓冲区(
audio_buffer)处理不及时。
解决建议:
设置合理的
CHUNK_SIZE,一般为320(20ms)或512;确保发送线程与播放线程为守护线程(
daemon=True),避免阻塞;使用性能监控工具观察线程运行状态,及时发现瓶颈。
6.3 动作执行不准确
问题现象:
用户说“向前走三步”,但机器人执行了错误指令;
语义识别失败或参数缺失,导致
NoneType错误;函数调用中
value为空。
原因分析:
Prompt 设计不明确,模型不理解语义意图;
缺乏上下文或明确指令格式;
未设置函数默认参数,导致参数缺失时解析失败。
解决建议:
提高
system_instruction的明确性,例如:"你是一个机器人控制专家,请根据语音指令生成动作指令,如前进、后退、左转等。"在
.env中设置默认值,如ADVANCE_DEFAULT_VALUE=2,提高容错率;增加日志打印,输出收到的参数内容,便于调试;
考虑将 Function 调用设计为结构化 schema,明确字段范围。
一个高质量的系统 prompt 通常包含以下 5 个部分:
| 部分 | 内容 | 示例 |
|---|---|---|
| 1️⃣ 角色设定 | 明确 AI 的职责与定位 | 你是一个机器人控制系统,负责从用户语音中提取控制指令 |
| 2️⃣ 指令目标 | 明确需要“做什么” | 从用户的语音指令中提取出动作类型和参数值 |
| 3️⃣ 可用动作说明 | 列出所有支持的动作及其含义/单位 | advance(前进,步数),left_rotation(左转,角度)等 |
| 4️⃣ 输出规范 | 告诉模型输出形式,如 JSON、结构字段等 | 输出字段包括 action 和 value |
| 5️⃣ 容错与缺省策略 | 没说清楚怎么办?数值缺失怎么办? | 如用户未指定 value,请使用默认值 |
七、结语
通过本项目,我们从零搭建了一个基于 OpenAI Realtime API 的实时语音控制机器人系统。系统不仅能够接收用户语音指令,实时进行语义识别,还能触发结构化函数调用,驱动本地动作控制逻辑,最终形成“说话→理解→执行→反馈”的完整闭环。实时语音交互是人机交互领域的重要方向,结合 OpenAI Realtime API 与 Function Calling 技术,你将拥有一个极具潜力的开发平台。希望本教程不仅帮助你完成了一个有趣的项目,更激发你去构建更多基于语音和 AI 的创新应用。
现在,拿起麦克风,让你的机器人“听你说,照你做”。
📁 GitHub 仓库(代码开放):https://github.com/fuwei007/Navbot-ES02/tree/main/src/RDK_X5
📽️ 视频演示:https://www.youtube.com/watch?v=YUhkF7lPQ0k&t=80s
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝
