



















EasyOne——突破AI多模态极限
最近才有时间写这篇博客,持续更新中~
EasyOne是一款强大的多模态智能插件,集文字、文件、图片、音频和视频等处理于一体,支持跨平台使用,并提供高度可定制的体验,旨在提升用户的办公效率。EasyOne基于Langgraph框架下的multiple-agent系统作为基础,进行二次开发,并作为核心处理中枢,拓展AI多模态功能。弥补ChatGPT在聊天中,无法生成并处理音频、无法生成并处理视频、无法访问特定链接、知识库老旧等缺点,并集成了实时数字人对话、自定义Agent工作流等高级功能。
谷歌插件:https://chrome.google.com/webstore/detail/lpdijhbnidbpgieomplbepgiffnjicjd
Edge插件:https://microsoftedge.microsoft.com/addons/detail/acobjpjnjiaddpfbhoojllpmlgloikih
一、产品背景与构思
1.1 为什么是 EasyOne?
EasyOne 的构思源自于我们对当前人工智能技术和产品发展趋势的深入思考。在过去的几年中,人工智能领域取得了飞速发展,各类技术逐渐成熟,尤其是在图像生成、语音识别、自然语言处理等单一模态的应用上。这些技术无疑在各自领域内发挥了巨大作用,然而,随着应用场景的多样化,单一模态的技术已经无法满足许多复杂任务的需求,特别是需要跨多个模态(文本、图像、音频、视频等)进行综合分析和处理的场景。
尽管单一模态的 AI 技术已非常先进,但在许多实际应用中,用户需求往往超出了某一模态的能力。例如,在教育、娱乐和设计等领域,用户可能同时需要通过文本描述生成图像、视频,并进行实时语音交互;而在多场景的虚拟助手或智能客服中,用户不仅依赖语音和文本,还需要图像或视频作为反馈。传统的 AI 产品在这些跨模态交互上存在很大的局限性,无法实现不同模态之间的无缝衔接和互动。
随着计算能力的飞跃提升和深度学习模型的突破,跨模态技术逐渐成为可能。为了解决现有产品的局限,我们决定开发一个全新的平台——EasyOne,目标是打破传统 AI 技术的模态壁垒,将图像生成、视频生成、文本处理、语音交互等技术完美融合,构建一个集成多模态交互的智能平台。EasyOne 的使命是:让人工智能技术不再是高高在上的科研成果,而是变得易于理解、简单易用,让用户能够通过自然的方式在多个模态之间自由切换,享受流畅的跨模态体验。
通过 EasyOne,我们希望让每个用户,无论是个人用户还是企业用户,都能轻松地获得高效、智能的 AI 服务,打破技术的复杂性与限制,提升应用的灵活性和广泛性。
1.2 功能与目标
为了确保 EasyOne 能够满足用户日益增长的需求,我们为该平台设定了几个核心目标,涵盖了技术的整合、用户体验以及可用性等方面:
无缝集成多模态技术
我们致力于打破文本、图像、视频、音频等多种模态之间的技术壁垒,实现跨模态的数据交互。这意味着,无论用户输入的是文字、图像、语音,EasyOne 都能智能地理解并返回对应的多模态反馈。通过将各种 AI 技术集成在同一个平台中,用户可以更加灵活地选择适合他们需求的方式进行交互,享受流畅、自然的跨模态体验。
跨平台与设备兼容性:全面覆盖用户需求
随着智能手机、智能电视、电脑、AR/VR 设备等硬件的普及,用户期望能够在各种平台上享受一致且无缝的 AI 服务。为了最大程度地满足用户的需求,EasyOne 的架构设计特别考虑了多平台的兼容性。无论用户使用的是移动端、桌面端,还是跨设备的联网环境,EasyOne 都能保证平台功能的稳定性和一致性。我们采用了 响应式设计 和 自适应架构,确保无论在哪种设备上,用户都能获得最佳的操作体验。同时,平台支持多种输入输出方式,包括触摸、键盘、语音和图像上传等,为用户提供最大灵活性。
实时响应与高效处理
无论是生成图像、视频还是音频,用户都希望能够快速获得反馈。为了确保满足这一需求,我们优化了后端处理能力,并结合先进的实时 API 技术,实现了低延迟、高效的处理速度。这不仅保证了生成过程中的流畅性,也为用户带来了更高的互动感受。在多并发的情况下,平台依然能够保持稳定的响应速度,提升了用户体验。极简操作与高效输出
我们的目标是让用户能够以最简单的方式实现复杂的任务。因此,在产品设计上,EasyOne 突出“极简操作”。用户无需具备深厚的技术背景或复杂的配置,只需简单输入文本、上传图片,或通过语音指令,系统便能自动理解需求并生成所需的图像、视频或音频。通过自动化处理和智能推荐功能,EasyOne 进一步简化了用户操作步骤,让每个用户都能轻松上手,快速得到满意的结果。
成本效益
AI 技术的高成本和复杂性是许多用户面临的主要障碍。对于许多中小型企业和个人开发者而言,部署和维护 AI 模型所需的硬件资源和运营费用往往高不可攀。EasyOne 通过将最新的 AI 技术和强大的计算资源进行云端集成,让用户无需进行模型部署和硬件投资,即可享受最先进的 AI 服务。这不仅为用户节省了大量的成本,还避免了技术部署中的繁琐步骤,使得人工智能技术能够广泛普及,触手可及。
可扩展性与未来发展
EasyOne 的架构设计非常注重系统的 可扩展性。我们不仅能够根据当前技术需求进行拓展,还能随时根据市场的变化和用户需求的多样化,快速集成新的 AI 技术和功能。例如,未来我们计划引入更加先进的 数字人 技术,将跨模态生成能力扩展到更加沉浸的场景中,进一步丰富用户体验。此外,随着大数据和边缘计算技术的发展,EasyOne 将继续强化其 智能学习与优化功能,根据用户的行为和反馈持续优化生成模型,提供更加精准、个性化的服务。
二、技术架构设计
2.1 架构概述
EasyOne 是一款多模态智能插件,旨在为用户提供集文本、图像、音频、视频等多种 AI 服务于一体的跨平台体验。为实现这一目标,EasyOne 采用了模块化、可扩展的技术架构,确保系统在处理不同模态的交互时,能够高效、灵活且稳定地工作。该架构以 LangGraph 为核心的 multiple-agent 系统为处理引擎,依托强大的后端服务和前端交互层,形成了完备的 AI 生态系统。
系统的主要架构由三个主要部分组成:前端层、后端层和 AI 处理层。前端层负责用户交互和展示,后端层负责业务逻辑和数据存储,而 AI 处理层则负责核心的人工智能任务,包括文本生成、图像生成、语音识别、实时语音交互等多种功能的实现。
2.2 系统架构图
(前端、后端、AI 层的互动及数据流)
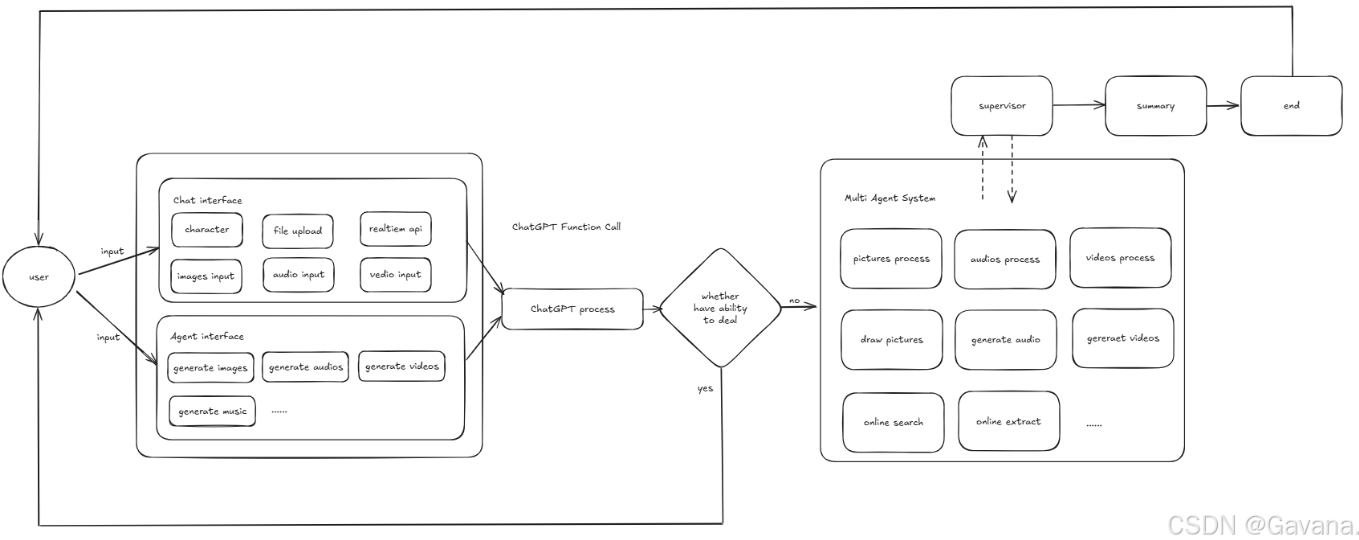
2.3 技术栈
前端技术栈:
Chrome Extension API:支持通过浏览器插件无缝访问 easy.ai 的功能,简化了用户的使用流程。
HTML/CSS/JavaScript:前端展示和交互的基本技术,用于设计清晰、响应式的用户界面。
Vue.js:用于构建现代化、动态交互的用户界面,支持组件化开发,使得界面易于扩展和维护。
OAuth 2.0:用于实现安全的用户身份认证,确保用户信息的安全性和隐私保护。
后端技术栈:
Spring Boot:作为后端服务的核心框架,Spring Boot 提供了高效的 RESTful API 和微服务支持,确保了系统的高性能和可维护性。
Mybatis Plus:通过简化数据库操作,提升了数据库访问的效率与便捷性,支持自动化 SQL 构建。
Python:用于 AI 模型的训练、推理和交互,尤其擅长处理自然语言处理(NLP)和计算机视觉(CV)任务。
LangGraph:多代理系统引擎,负责调度和协同各个 AI 代理执行复杂的跨模态任务,确保系统高效地处理用户请求。
MySQL:用于存储用户数据、历史记录等核心信息,确保系统数据的持久化和高效查询。
Redis:为热数据和频繁访问的操作提供缓存支持,极大提高系统响应速度和并发能力。
中间件:
Nginx:用作反向代理和负载均衡器,确保流量分发的均衡性,并提高系统的稳定性。
Kafka/RabbitMQ:消息队列系统,用于异步处理大规模数据和任务调度,避免阻塞主线程。
其他服务:
ChatGPT:提供文本生成和理解功能,作为自然语言处理(NLP)的核心。
Realtime API:实现实时语音交互,提升用户的交互体验。
MuseTalk:音嘴同步开源项目。
KLING AI、Runaway:用于图像、视频的生成,增强平台的多模态处理能力。
Elevenlabs:为生成特定音色的音频提供支持,增强语音内容的个性化。
OpenAI TTS/STT:为语音交互提供文本转语音(TTS)和语音转文本(STT)能力,提升用户体验。
Remove.bg:提供图像去背景等处理功能,增强图像生成的灵活性。
Stripe:处理用户的支付和订阅服务,支持按需收费模式。
Azure:作为云计算平台,提供服务器和文件存储支持,同时提供 OCR(光学字符识别)功能用于图像解析。
GoDaddy:提供域名注册服务,确保 EasyOne 的稳定访问。
Mailchimp:用于发送通知邮件和营销邮件,帮助维护用户关系。
Hugging Face:提供开源AI服务,拓展 EasyOne 的免费功能。
2.4 系统组件与层次结构
前端:
前端层采用 JS,搭配 HTML 和 CSS,以实现流畅的用户体验。前端通过 Chrome Extension API 提供快速的扩展插件,方便用户随时使用 EasyOne 服务,且能够与浏览器无缝集成。
后端:
后端层使用 Spring Boot 开发,作为 RESTful API 提供业务逻辑服务。Spring Boot 的自动配置和快速开发特性帮助我们高效构建并部署后端服务。通过 MyBatis Plus 与 MySQL 数据库的结合,我们能够高效地管理用户数据、请求记录和模型日志等信息。此外,Python 在后端中的作用至关重要,所有的 AI 模型的推理与处理工作都由 Python 代码完成。
AI 处理:
AI 处理层是系统的核心,基于 LangGraph 的多代理系统,能够根据任务的不同分配给合适的代理进行处理。LangGraph 架构支持多个代理协同工作,不同的代理擅长处理不同类型的任务,例如某个代理专门负责生成图像,另一个代理则处理实时语音交互。AI 模块包括:
自然语言处理(NLP):通过 ChatGPT 提供对话式生成与理解。
计算机视觉(CV):图像生成与处理通过 KLING AI 和 Remove.bg 完成,视频生成与处理通过Runaway和yt_dlp完成。
语音交互:实时语音对话和音频生成通过 Realtime API 和 Elevenlabs 实现。
多模态协作:跨文本、图像、视频、音频等模态的任务通过 LangGraph 内部的代理协作完成。
2.5 数据流与工作流程
EasyOne 的工作流程包括以下几个主要步骤:
用户请求提交:用户通过前端输入文本、语音或图像等内容。
任务分配与调度:后端通过 API 接口接收请求,并根据请求内容将任务分配给对应的 AI 代理。每个代理根据任务类型(文本生成、图像处理、语音识别等)进行专门处理。
任务处理:AI 代理通过调用相应的 AI 模型进行处理,生成相应的结果(如生成文本、生成图像或视频、语音转写等)。
结果返回与展示:处理完的结果通过 API 返回前端,前端更新界面展示给用户。
2.6 安全与隐私保护
为了确保系统安全,所有用户数据在传输过程中都使用 HTTPS 加密,保护敏感信息不被泄露。对于用户认证,我们采用 OAuth 2.0 进行授权和认证,确保每个请求都是合法的。此外,平台严格遵守 GDPR 等隐私保护规范,确保用户数据的隐私性和安全性。
三、核心功能与技术实现
3.1 多模态数据交互
EasyOne 的多模态数据交互功能使用户能够通过不同的输入方式(如文本、图像、视频、音频等)与平台进行交互。平台能够在这些不同模态之间进行高效的数据转换和处理,从而为用户提供流畅的跨模态体验。这里EasyOne 基于 LangGraph 开发的多代理架构multi-agent system作为核心,进行拓展开发。不同模态的数据处理任务通过专门的代理进行处理。例如,图像生成由 Runaway 代理处理,音频处理则由 OpenAI STT 和 TTS 技术提供。所有的代理通过统一的接口进行通信,确保各类模态的数据能够有效互通。
3.1.1 关键概念:代理、管理节点与 Supervisor
代理(Agent)
代理 是 Multi-Agent 系统中的核心组件,通常是一个具有独立行为的实体。在 EasyOne 中,每个代理负责不同的模态处理任务。例如:文本生成代理:调用 OpenAI GPT 模型生成文本。图像生成代理:使用 Runway 等模型根据文本生成图像。每个代理都具备 自治性,可以在接收到输入后,按照既定规则独立进行处理,并生成相应的输出。它通常具备以下特性:
自主性(Autonomy): 能够独立完成任务,作出决策。
感知能力(Perception): 能够感知环境并获取信息。
行动能力(Action): 基于感知到的信息,能够执行某些动作或任务。
通信能力(Communication): 能与其他代理或系统组件进行信息交换。
Supervisor(监督者)
Supervisor 是系统中的 高层协调者,它主要负责 全局任务调度 和 任务执行的健康监控,侧重于 全局状态的管理 和 任务的容错处理。
全局任务协调与调度:Supervisor 不仅仅关注单个任务的执行,而是根据任务的复杂性和代理的工作状态来综合判断如何合理调度任务。它负责决定是否需要启用新的代理,或者需要将任务重新分配给其他代理以提高效率。
异常处理与容错机制:当某个代理发生故障时,Supervisor 会监控到这种异常,并负责做出补救措施。它可能会重启失败的代理、重新调度任务或者启用备用代理来继续处理任务,确保系统的高可用性。
任务追踪与状态监控:Supervisor 负责追踪全局任务的状态,包括每个代理当前处理的任务进度和任务是否完成。如果任务没有按预期完成,Supervisor 会采取适当措施进行干预。
有向无环图(DAG)
在多代理系统中,任务往往会依赖于其他任务的输出,尤其是在处理跨模态的数据时。为了有效地管理任务之间的依赖关系,我们采用 有向无环图(DAG) 来表示任务的流转过程。(有向:任务的流转是单向的,数据从一个代理流向另一个代理。无环:任务之间的依赖关系不会形成闭环,避免死锁和循环依赖。)
在 EasyOne 中,DAG 用于表示和调度跨模态的数据处理流程。例如,图像生成的任务可能依赖于前一个文本生成代理的输出,而语音合成代理则需要依赖于文本生成的结果。通过 DAG 管理这些任务依赖,能够确保任务按正确的顺序执行,同时避免资源冲突。
3.1.2 什么是multi-agent
Multi-Agent 系统(多代理系统) 是一种由多个代理组成的系统架构,每个代理都是一个独立的智能实体,负责执行特定的任务。代理之间可以相互协作、共享信息,并根据任务的需要进行相互沟通。在 AI 系统中,代理可以根据任务的类型分工处理不同的任务。例如,语音识别、图像生成、文本处理等任务可以由不同的代理来处理,最终通过统一的系统协调完成复杂的工作。
特点:
自治性:每个代理都有独立的决策能力,能够独立执行任务。
协作性:代理之间能够共享信息、协调工作,解决更复杂的任务。
分布性:代理分布在不同的计算节点上,允许系统根据需要动态分配资源,处理高并发和大规模请求。
灵活性:系统可以根据需求动态地增加或移除代理,支持不同的应用场景。
在 EasyOne 中,multi-agent system 是解决不同模态任务的关键架构。每种任务(如文本生成、图像生成、语音识别)都由独立的代理进行处理,最终通过协调工作,提供一个无缝的跨模态体验。
3.1.3 Multi-Agent 系统的运作方式
任务调度与执行
当用户请求一个跨模态的任务(如生成一段视频,结合文本和图像),请求首先被 代理管理节点 捕获。代理管理节点会解析任务类型并通过 任务调度 来决定哪个代理来处理。任务根据 DAG 中定义的依赖顺序被分发到相应的代理。例如,首先由 文本生成代理 处理用户输入的描述,再将生成的文本传递给 图像生成代理 来创建图像,最后将文本和图像数据交给 视频生成代理 进行处理。
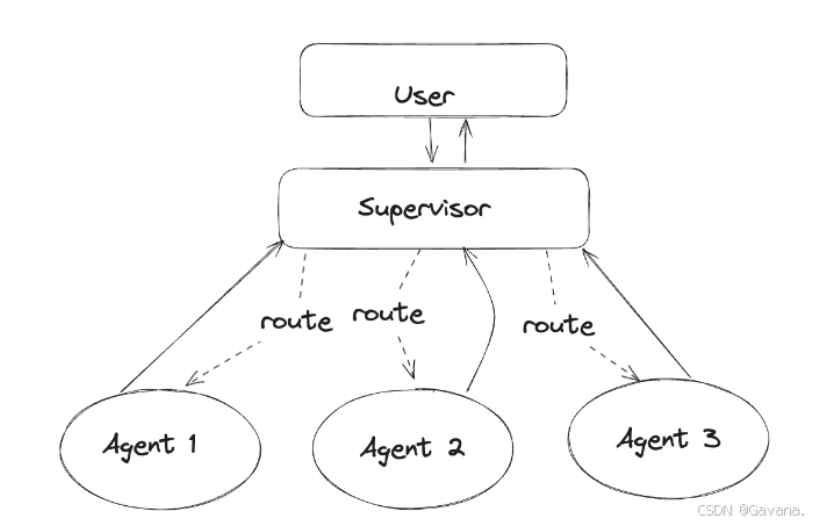
代理间的通信
代理之间通过 消息传递机制 进行协作。例如,代理可以通过 消息队列(如 RabbitMQ 或 Kafka)进行异步通信,确保不同代理在高并发的情况下不会阻塞其他任务的执行。代理管理节点和 Supervisor 也通过消息队列共享任务状态和执行进度,确保系统能够实时监控和调度任务。
信息共享与数据流转
在处理复杂任务时,不同代理之间需要共享数据。例如, 语音识别代理 的输出(转写后的文本)可能成为 语音合成代理 的输入。为了确保数据的一致性和完整性,所有代理都通过统一的接口传递数据,数据格式可以是 JSON 或 Protocol Buffers,并通过 API Gateway 统一管理。通过这种方式,EasyOne 保证了每个代理处理任务时的数据流转清晰,避免了重复计算或数据丢失的情况。
动态代理添加与移除
在负载高峰期,系统可以动态地增加新的代理实例,以分担更多的请求负载。这种 弹性扩展 机制使得 EasyOne 在应对高并发时依然能够保持高效运行。代理的增删与调度由 Supervisor 管理,确保系统整体的平衡和稳定性。
3.1.4 Multi-Agent 系统的优势与应用场景
灵活性与扩展性
由于每个代理负责不同的任务,系统可以灵活扩展。例如,EasyOne 可以根据需要,增加新的任务类型或引入新的模态代理(如语音翻译、情感分析等)。随着新的技术的出现,现有代理也可以逐步替换或升级,而无需对整个系统架构进行大规模修改。
高效的任务分配与协作
通过代理之间的协作,Multi-Agent 系统能够分担并行计算,提升系统的处理能力。在处理大型请求时,系统能够智能调度代理,减少响应时间。
任务依赖与智能调度
基于 DAG 管理任务依赖和调度,系统能够确保各类任务按照正确的顺序执行,避免因任务冲突或错误的顺序导致的失败。
容错性
由于代理是自治的,系统具有较高的容错能力。如果某个代理发生故障,其他代理仍然可以继续工作,Supervisor 会负责重试或切换到备用代理。
3.1.5 Multi-Agent 系统的构建
按照步骤即可搭建一个基础的Multi-Agent 系统。在该系统中,虽然我们能够看到其按照一定的逻辑调用Agent,但是也存在一个明显的问题,即只有执行流程,但在执行结束后没有讲整个结果进行总结,形成一个友好的输出。
为此我们需要进一步拓展,加入一个这样的结点,SuperVisor在完成此次调用后,在结束前进行一次总结,根据所有之前的执行步骤得到的结果以及用户的输入,形成友好的输出。即图中的Summary结点。
该结点可以定义如下:
def summary_node(state):
"""
总结节点:根据用户输入和任务执行结果生成详细总结。
"""
# 提取用户输入
user_input = state['messages'][0].content
print("user_input:" + user_input)
# 收集所有功能节点的执行结果(无需手动分类,交给 AI 处理)
executed_results = [
f"Step {i + 1}: {message.content}"
for i, message in enumerate(state['messages'][1:]) # 包括所有消息,不跳过
]
# 打印所有执行过程的结果,方便调试
print("executed_results:")
for result in executed_results:
print("result:" + result)
# 将所有步骤的执行结果传递给 GPT 进行总结
summary_prompt = (
f"User Input:\n{user_input}\n\n"
f"Execution Results:\n{'\n'.join(executed_results)}\n\n"
f"Based on the above input and results, please generate a detailed and user-friendly summary.\n"
f"Make sure to address the following:\n"
f"- Use second-person language (you).\n"
f"- Include the type of content generated (e.g., subtitles, images, videos, audio).\n"
f"- Provide links to generated content (e.g., image links, video links).\n"
f"- Ensure the summary feels personalized and natural, like you're talking directly to the user.\n"
f"- Focus on answering the user's request and make the response as conversational as possible.\n"
f"- Adapt the response based on the current language environment. If the language is Chinese, provide the summary in Chinese. If it's English, provide the summary in English.\n"
f"\n"
)
# OpenAI API 请求设置
openai_url = "https://api.openai.com/v1/chat/completions"
request_body = {
"model": "gpt-4o", # 使用适当的模型
"messages": [
{"role": "system",
"content": "You are an assistant that generates user-friendly and personalized summaries for users based on workflows."},
{"role": "user", "content": summary_prompt}
]
}
headers = {
"Authorization": f"Bearer {os.getenv('OPENAI_API_KEY')}",
"Content-Type": "application/json"
}
try:
# 调用 OpenAI 接口
response = requests.post(openai_url, headers=headers, json=request_body)
response.raise_for_status()
# 获取生成的详细总结
detailed_summary = response.json().get('choices', [{}])[0].get('message', {}).get('content',
'Summary not generated.')
except Exception as e:
detailed_summary = f"Error generating summary: {str(e)}"
# 打印总结(可选)
print("summary_node:" + detailed_summary)
# 返回包含总结的消息,并结束流程
return {
"messages": [detailed_summary], # 返回包含总结的消息
"next": "__end__"
}
于此同时需要注意的是,在Langgraph的示例代码中,并没有讲述SuperVisor如何知道不同的Agent结点的具体功能,这样将导致SuperVisor无法准确调用对应功能,这里可以在向图中添加结点时,增加描述的元数据,如下:
workflow.add_node("summary_node", agent.summary_node,metadata={"description": agent_descriptions["summary_node"]}) #代理节点3.2 实现ChatGPT多模态拓展
3.2.1 需求分析与目标定义
在开发过程中,首先需要明确多模态拓展的具体需求和目标:
多模态输入的支持:定义哪些模态需要被支持(文本、图像、语音、视频等)。
交互方式:确定用户通过何种形式与系统交互。例如,用户输入文本,系统生成图像;用户发送音频,系统返回语音文本等。
扩展性要求:确定系统的扩展性,如何添加新的模态和代理,满足未来不断变化的需求。
性能与实时性要求:确保系统能在不影响用户体验的前提下处理复杂的多模态任务,实时反馈结果。
3.2.2 功能调用与 ChatGPT 集成
与 ChatGPT 集成是多模态拓展的核心,如何通过 OpenAI 的 API 或功能调用将多模态处理逻辑嵌入到 ChatGPT 的对话系统中。通过定义一个 Function,我们可以在 ChatGPT 无法直接回应用户请求时,调用我们开发的 Multi-Agent 系统。具体实现如下:
tools: [
{
type: "function",
name: "function_call_judge",
description: "Determines if the user's request requires a task beyond the current capabilities of yours. If you can't deal with,call the function to expand your capabilities to statify the user's needs.",
parameters: {
type: "object",
properties: {
userInput: {
type: "string",
description: "The user's input query or request."
}
},
required: ["userInput"]
}
}
]在这个过程中,function_call_judge 会判断用户的输入是否超出了 ChatGPT 的处理能力。如果超出范围,ChatGPT 将通过该函数调用 Multi-Agent 系统来扩展其能力,从而满足用户的需求。通过这种方式,我们能够有效地将 ChatGPT 的基础能力与 Multi-Agent 系统相结合,实现在多个模态(如图像、视频、音频等)之间的无缝切换与交互。
3.2.3 异常处理与容错机制
在多模态系统中,任务的失败、代理故障等问题是常见的挑战。需要设计异常处理和容错机制:
代理容错机制:当某个代理出现问题时,系统应该能够自动重新调度任务或切换到备用代理,确保任务顺利完成。
错误回退机制:如果某个任务无法通过多模态系统完成,可以回退到 ChatGPT 本身进行处理,确保系统能够尽可能地响应用户请求。
3.3 跨平台使用
在多模态 AI 系统的设计中,跨平台使用是一个关键要素。EasyOne 作为一款多模态智能插件,旨在为用户提供灵活、高效、无缝的体验,而跨平台使用确保用户能够在各种设备和操作系统上自由使用,不受设备和环境的限制。为了实现这一目标,系统的架构、功能和接口设计需要考虑不同平台的兼容性和适配性。以下是实现跨平台使用的几个关键方面:
3.3.1 支持主流操作系统与设备
为了让用户能够在不同设备和操作系统上使用 EasyOne,首先需要确保系统的兼容性。我们通过以下方式实现跨平台支持:
Web端:通过 HTML、CSS 和 JavaScript 构建响应式网页,使其能够在任何现代浏览器中运行。通过 Vue.js 提供高效的前端框架,确保用户体验的流畅性。无论用户使用 Windows、macOS 或 Linux 操作系统,只要有浏览器即可访问和使用 EasyOne。
桌面端:对于需要更高性能或更稳定的用户体验,EasyOne 也提供了桌面应用版本,适用于 Windows 和 macOS 系统。通过 Electron 等跨平台开发框架,用户可以在桌面环境中使用 EasyOne,无论是在工作站、个人电脑还是笔记本电脑上。
3.3.2 跨平台数据同步
在跨平台使用场景下,数据同步和一致性至关重要。用户可能在不同设备间切换,因此需要确保数据能够实时同步并且无缝衔接。为此,EasyOne 采取了以下措施:
云端数据存储:所有用户的数据(如用户设置、生成的图像、音频、历史记录等)都存储在云端,确保用户在不同设备上登录后可以访问相同的数据,进行无缝切换。
持久化与缓存机制:为了优化用户体验,EasyOne 还使用本地缓存来存储一些频繁访问的数据。无论是在网络连接较差的环境下,还是在用户切换设备时,缓存机制确保用户的数据能够被快速访问,而不需要每次都从云端重新加载。
3.4 实时数字人对话
区别于传统的数字人对话(即通过STT,NLP,TTS,嘴型同步技术),EasyOne采取的是最新的OpenAI Realtime API + MuseTalk实现真正意义上的低延迟实时数字人对话。
实现的大致框架:
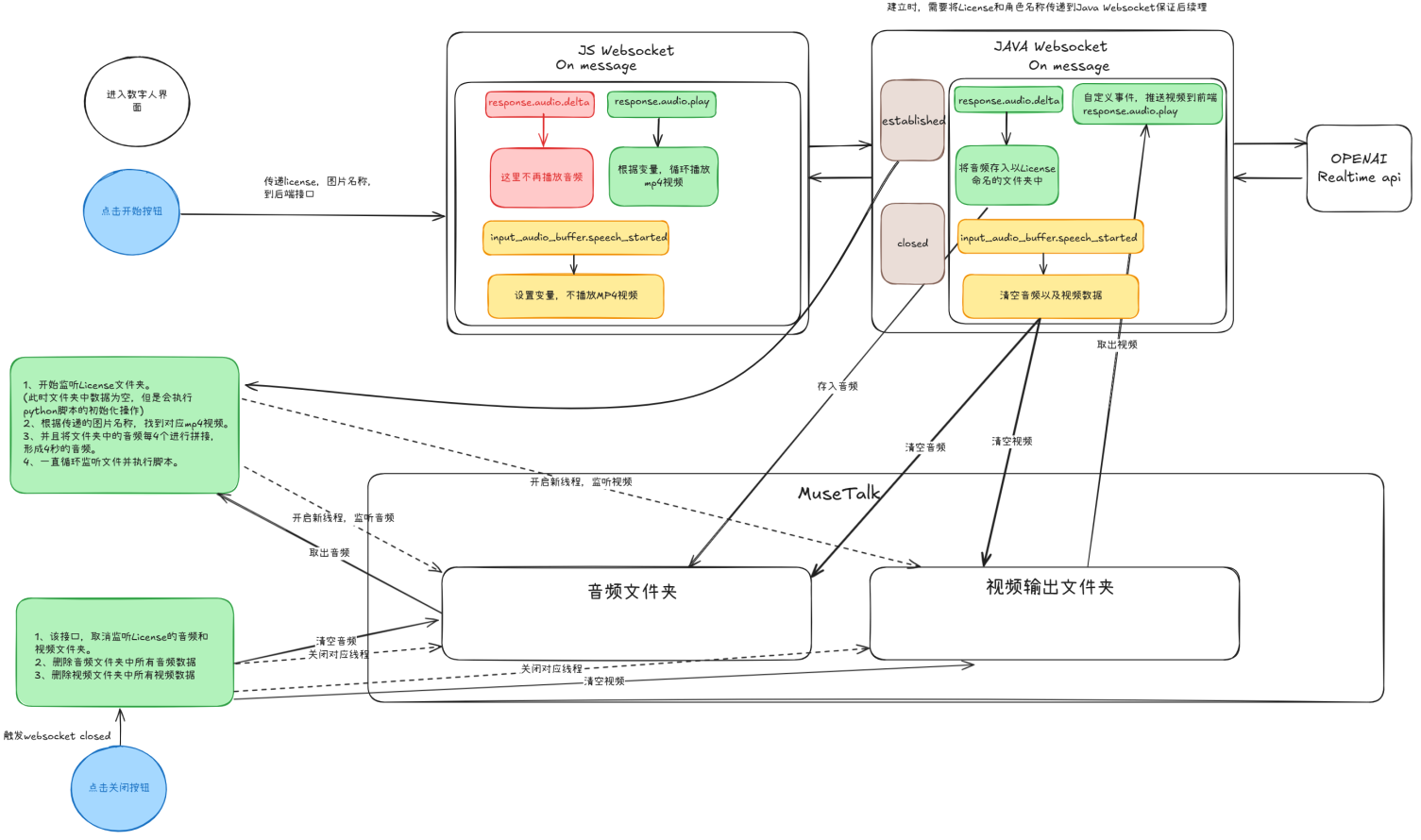
该框架可进一步优化,详细内容参考我撰写的数字人系列:
数字人系列(1):基于 MuseTalk + Realtime API 的实时数字人系统,可行性研究 | Gavana
数字人系列(2):基于 MuseTalk + Realtime API 的实时数字人系统,核心思路与项目架构 | Gavana
数字人系列(3):基于 MuseTalk + Realtime API 的实时数字人系统,技术挑战与解决方案 | Gavana
数字人系列(4):基于 MuseTalk + Realtime API 的实时数字人系统,参数调节与 GPU 选型 | Gavana
数字人系列(5):基于 MuseTalk + Realtime API 的实时数字人系统,Websocket+Mainsource到WebRTC视频推流转变 | Gavana
四、面临的挑战与解决方案
在开发和实现 EasyOne 这一多模态智能插件的过程中,虽然我们取得了许多突破性进展,但仍然面临着一系列的技术挑战。这些挑战不仅涉及到多模态数据的处理和系统架构的优化,还包括用户体验、跨平台适配、性能提升等方面。为了确保系统的稳定性、可扩展性以及最终用户的使用体验,我们在多个方面进行了深入的探索和创新,提出了相应的解决方案。
4.1 多模态数据处理的复杂性
挑战:
多模态系统的核心在于对不同类型数据(文本、图像、音频、视频等)进行有效的处理与融合。每种模态的数据处理方式、模型和算法都各不相同,如何实现不同模态之间的无缝衔接成为一项重大挑战。例如,如何处理不同模态间的输入输出差异,如何在图像生成和文本生成之间进行协调,以及如何保持高质量的多模态交互体验。
解决方案:
为了有效应对这一挑战,我们设计了基于 Multi-Agent 系统 的架构,通过独立的代理来处理不同模态的数据。每个代理专注于特定任务,例如图像生成、语音识别、文本生成等。通过这些代理的协作,系统能够高效地处理和融合不同模态的数据。
任务调度:通过 代理管理节点 来动态调度和分配任务,确保每个任务都能够被正确地指派给合适的代理进行处理。
数据转换与传输:采用标准化的 API 进行数据传输,确保不同模态间的数据能够顺畅转换。
系统扩展性:随着需求的增加,我们能够方便地添加新的代理来支持更多的模态,进一步提升系统的扩展性。
4.2 实时响应与低延迟要求
挑战:
在多模态交互中,尤其是涉及语音和视频生成时,系统需要实现实时反馈,以保证用户获得良好的交互体验。然而,实时数据处理往往要求较低的延迟和高效的处理能力,这对于多模态系统来说是一项重大挑战。
解决方案:
为了解决实时性问题,我们采取了以下措施:
负载均衡:使用 Nginx 等负载均衡技术,分散任务负载,避免单个节点的过载,确保系统的高可用性。
缓存机制:对于重复请求的数据,如常用的图像、音频文件等,我们采用缓存策略,减少重复计算,提升响应速度。
异步处理:将用户请求分为同步和异步两类,非关键任务(如数据分析、生成任务)异步执行,避免影响实时响应。
4.3 跨平台兼容性与适配
挑战:
EasyOne 作为一个跨平台的多模态智能插件,必须保证在不同操作系统(Windows、macOS)上都能够良好运行。然而,不同平台在硬件性能、操作系统特性、浏览器兼容性等方面存在差异,如何在多个平台上提供一致的体验和高性能表现是一项重要挑战。
解决方案:
为了确保跨平台兼容性,EasyOne 采取了以下措施:
响应式设计:通过使用 Vue.js 等现代前端框架,我们确保 Web 端界面能够适应各种设备的屏幕尺寸和分辨率,实现自适应布局。
统一的 API 接口:通过定义一致的 API 接口,确保无论是在 Web 端、移动端还是桌面端,前端都可以通过统一的方式与后端进行交互。
性能优化:对不同平台进行了针对性的性能优化。例如,在移动设备上优化图像和视频的加载与渲染,减少带宽消耗;在桌面端则增加更多的功能和支持更高质量的生成。
跨平台开发框架:采用 React Native 和 Electron 等跨平台开发工具,使得在不同平台上能够复用代码,减少开发与维护成本。
4.4 高并发与系统扩展性
挑战:
随着用户量的增加和功能的扩展,系统需要处理大量的并发请求和数据流。在高并发场景下,如何保证系统的稳定性和高效性,避免因资源竞争或瓶颈问题导致性能下降,是一项不可忽视的挑战。
解决方案:
为了解决高并发问题,我们采取了以下策略:
负载均衡:通过 Nginx 进行负载均衡,确保请求能够均匀分配到各个服务节点,防止单一节点过载。
数据库优化:在数据存储方面,采用 MySQL 和 Redis 进行数据存储与缓存,避免数据库成为性能瓶颈。对于频繁访问的数据,采用缓存技术加速查询速度。
异步任务处理:对于一些不需要即时反馈的任务(如数据分析、图像生成),采用异步处理模型,通过任务队列将任务分配给空闲的代理进行处理,避免影响实时响应。
容错与灾备机制:设计了完整的容错机制和灾备方案,确保在发生系统故障时能够及时恢复并保证服务不中断。
4.5 用户隐私与数据安全
挑战:
在处理多模态数据时,尤其是语音、图像和视频等敏感信息时,如何确保用户数据的隐私性和安全性是一个严峻的挑战。为了合规性和用户信任,我们必须保证系统在收集、存储和传输用户数据时的安全性。
解决方案:
为了确保数据的隐私性和安全性,EasyOne 采取了以下措施:
加密技术:所有传输的数据都采用 SSL/TLS 加密协议,防止数据在传输过程中被窃取。
数据隔离:用户数据与系统数据进行隔离存储,确保用户数据仅在必要的情况下被访问。
隐私政策:明确告知用户数据的使用方式,并遵守相关的隐私保护法规(如 GDPR),确保用户的个人信息不被滥用。
身份验证与权限控制:通过 OAuth2.0 等认证机制,确保用户的身份和权限得到验证,防止未经授权的访问。
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝
