


















NavTalk: Building the next-generation real-time Virtual Digital Human Platform
NavTalk 是一款革新性的实时虚拟数字人创建平台,通过整合前沿的 AI 技术,提供给开发者一个全栈式解决方案。平台无缝结合了三个核心技术模块——计算机视觉、语音交互和智能决策——以构建具备人类互动能力的拟真数字生命体。
Playground:https://console.navtalk.ai/#/playground/realtime_digital_human
1. 引言:虚拟数字人的时代已经到来
AI 交互方式的演变
在过去的十几年里,人机交互方式发生了显著演进。从图形界面(GUI)的点击操作,到触屏的直观滑动,再到语音助手让我们能“用说话”与设备沟通,每一次交互方式的跃迁,都在缩短人与技术之间的距离。然而,无论输入多么便捷,交互体验始终显得有限——声音模糊,回复僵硬,情感缺位。
直到最近,大语言模型(LLM)与实时多模态技术快速成熟,我们看到了“拟人交互”的可能性——不再只是让机器“听懂人”,更期待它理解“情绪、语境、意图”,甚至像一个有温度的“存在”来回应。由此可见,数字人的时代正在被重新定义。
数字人的应用需求全面爆发
从在线教育的虚拟讲师,到电商直播的数字导购,再到客服场景中24/7提供支持的虚拟助理,数字人的应用正急速扩展开来。企业们期待借助它们:
替代简单脚本,用更自然的方式持续互动;
弥合语言与文化差异,让虚拟形象具备多语言沟通能力;
结合知识库,提升信息响应的准确度;
在品牌营销中保持统一的风格与亲和力。
然而,多数市面数字人仍停留在“长得像人”的表面阶段。它们可以动,看起来灵动却无法回答复杂问题;无法理解你的上下文,更谈不上表达情绪和记忆对话内容。现在,行业迫切需要的是“既能响应用户,也懂用户”的数字人。
NavTalk 的目标与定位
NavTalk 正是在这一背景下应运而生。它不是简单的虚拟形象工具,而是一套真正具备“理解力、记忆力、表达力”的数字人解决方案。它结合了 GPT-4o 的智能大脑、低延迟音画驱动、多语言语音技术、知识库接入,以及高度定制化的交互风格,真正实现“会思考、更懂你”的数字人体验。NavTalk 的目标非常明确:
让每个人,都能拥有一个听得见情感、记得你谈话、能回答你具体问题、且能随时在线的“数字人”。
2. NavTalk 能做什么:能力概览
NavTalk 提供两种关键能力形态 —— 非实时数字人生成 和 实时互动数字人,面向不同使用场景分别优化,实现数字人能力的全面覆盖。
2.1 非实时数字人:文本/音频 → 视频,一键生成内容
NavTalk 提供强大的一键式批量合成功能,让你仅凭 文本或音频 + 头像模板,即可快速生成高质量的数字人视频,适合短视频、课程录制、广告制作等场景:
灵活输入与快速渲染
用户只需上传文本或音频,并搭配已有头像或模板,即可调用接口生成带有同步唇动和自然表情的完整数字人视频,输出为高清MP4文件或视频链接。
专业级视觉效果
合成视频具备 >30 FPS 帧率、精细口型同步、高还原表情,无需动画师即可获得媲美真人的视觉输出,保障观看质量。高效生产内容
平均渲染时间为数秒至几十秒,极适合批量制作使用,例如教学课件、品牌短片、产品说明视频等。统一风格与个性化定制
可使用上传的头像生成统一风格的数字人形象,也可结合品牌风格挑选模板,保持批量内容的一致性—而个性化仍然得以保留。
2.2 实时数字人:语音驱动,互动体验如同面对面
在实时交互方面,NavTalk 搭建了一个低延迟、可持续对话的数字人系统,让“对话像人与人之间那样自然流畅”成为可能:
实时语音驱动交互
基于 WebSocket 和 WebRTC 构建的实时音视频通道,实现低于 2000 毫秒的音画同步响应,适合对话式应用,如虚拟助理、客服、互动终端等。
角色形象高度定制
用户可上传照片生成个性化数字人形象,或选择预设模型,以及联系我们进行定制,实现与品牌或个性风格高度契合的视觉表达。
灵活角色设定机制
可通过配置定义数字人的角色身份、欢迎语与响应风格,实现语气及性格上的精准控制,满足不同场景需求。
情感感知和语气自适应
系统能感知用户语气和情绪,并相应调整回应语调与表达方式,提升互动的自然度和共情体验。
集成知识库,实现精准问答
支持接入企业或个人知识库,使数字人不只是“说话”,还能“有内容、有回答逻辑”。
智能对话核心:GPT-4o
核心对话能力由 GPT-4o 支撑,实现语言理解、多轮推理与上下文管理,远超传统脚本型数字人。
上下文记忆与持续理解
系统在多轮交互中持续积累对话内容,增强理解,从而让每次交流更有针对性。
多语言支持与全球化交互
支持 50+ 语言的语音识别与转写,准确率超过 95%;适配多语言切换,覆盖全球用户。
Tool 扩展与任务执行闭环
支持挂载自定义工具(如 API 查询、脚本调用等),让对话可以触发实际任务执行,构建对话+工具的一体化流程。
未来拓展:多模态能力升级
后续计划支持联网查询、多模态生成(图像与视频生成),让数字人具备更丰富的视觉交互与创作能力。
3. 技术架构
从开发至今,我设计了多个场景下的架构,也专研并攻克了许多的技术难题,包括Websocket实时基础系统,基于MuseTalk的二次开发以满足实时推理,WebRTC推流算法,GPU选型和算力分离,负载均衡,GPU集群架构,计费系统,定价策略,API文档编写,官网设计等等,数字人系列的博客也更新了10余篇。
Websocket实时基础架构:从0开始搭建前端到后端音频交互,再到AI处理输出视频的完整链路。从基于文件的基础搭建,再到全部使用i/o内存处理以提升响应速度。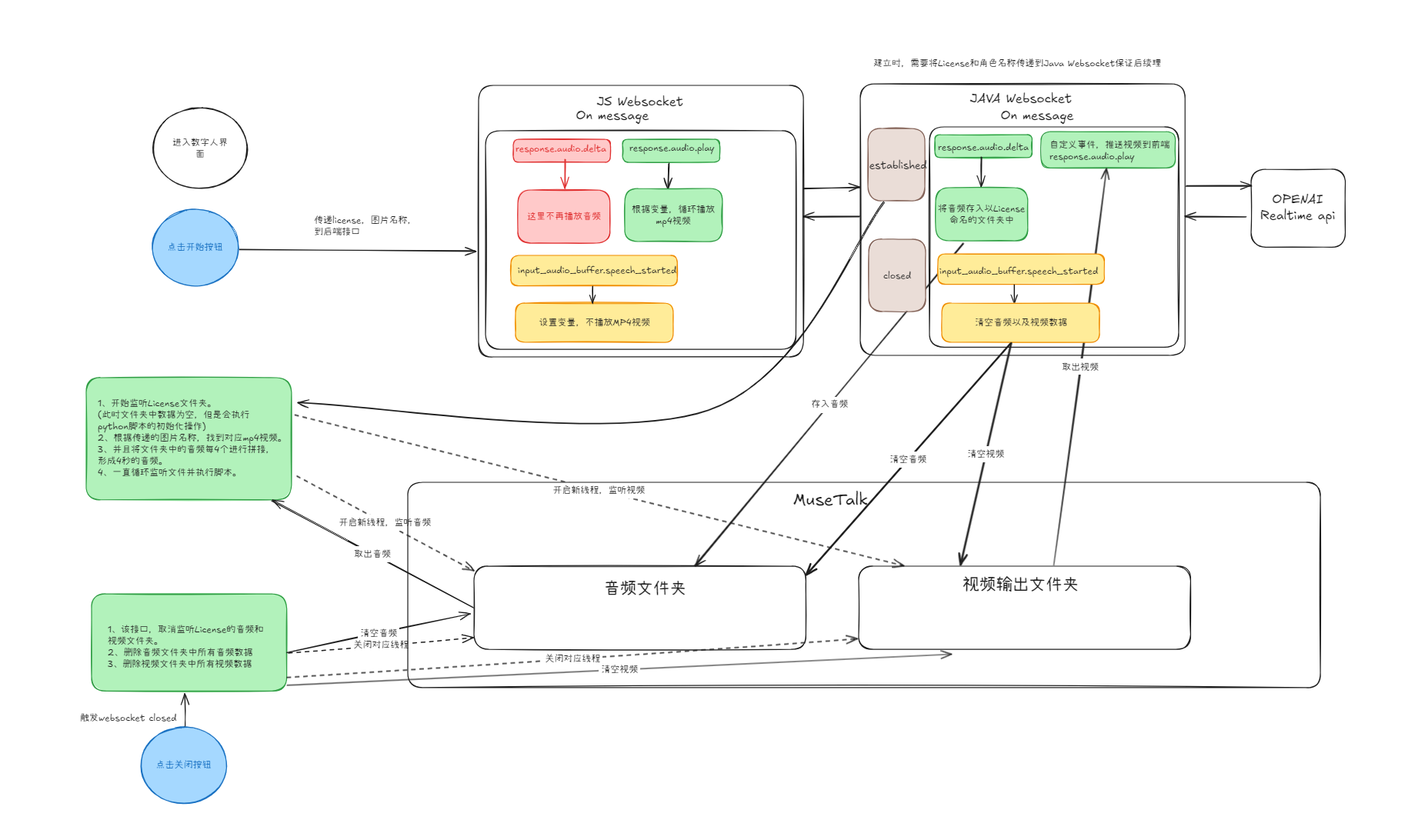
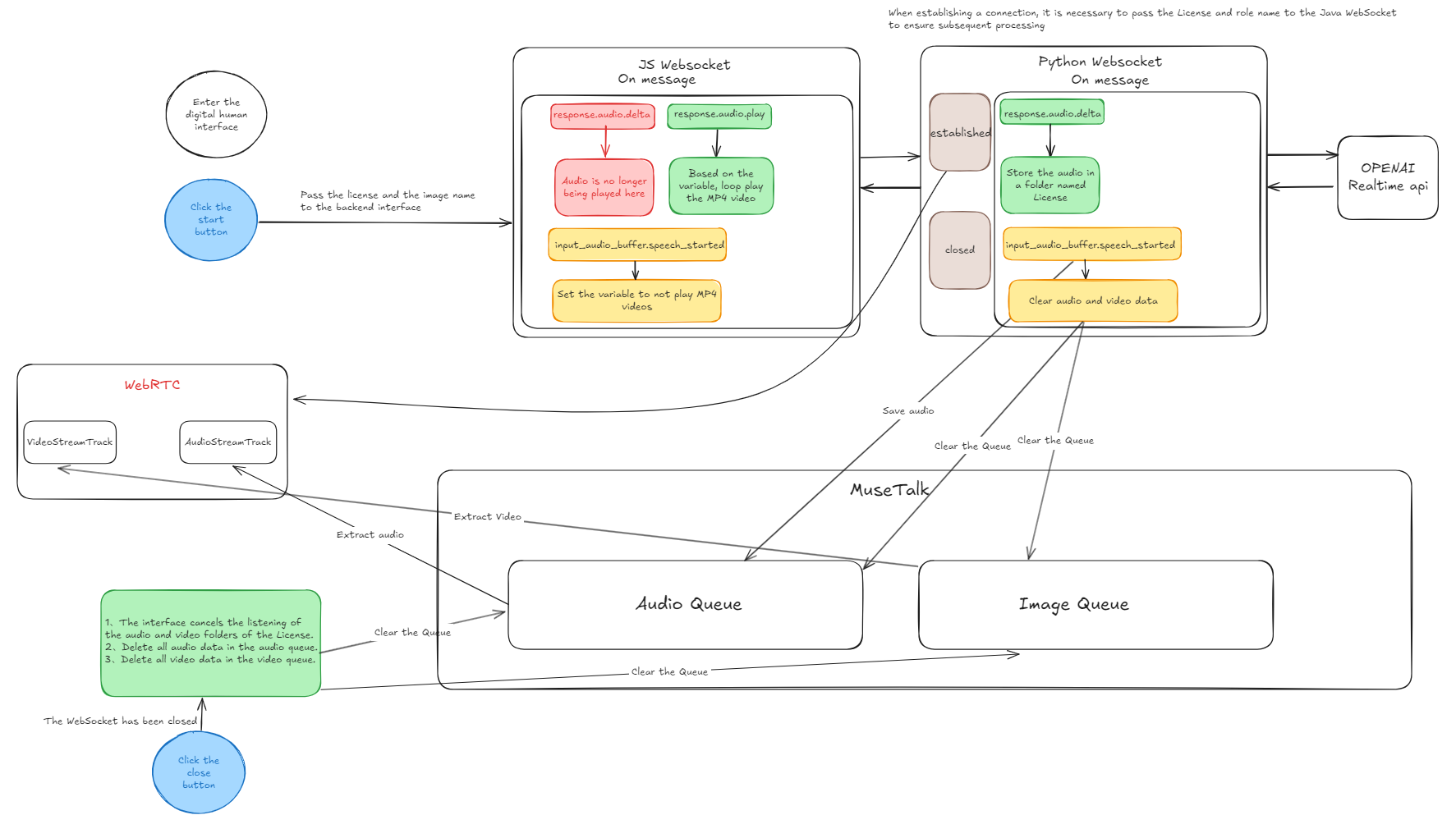
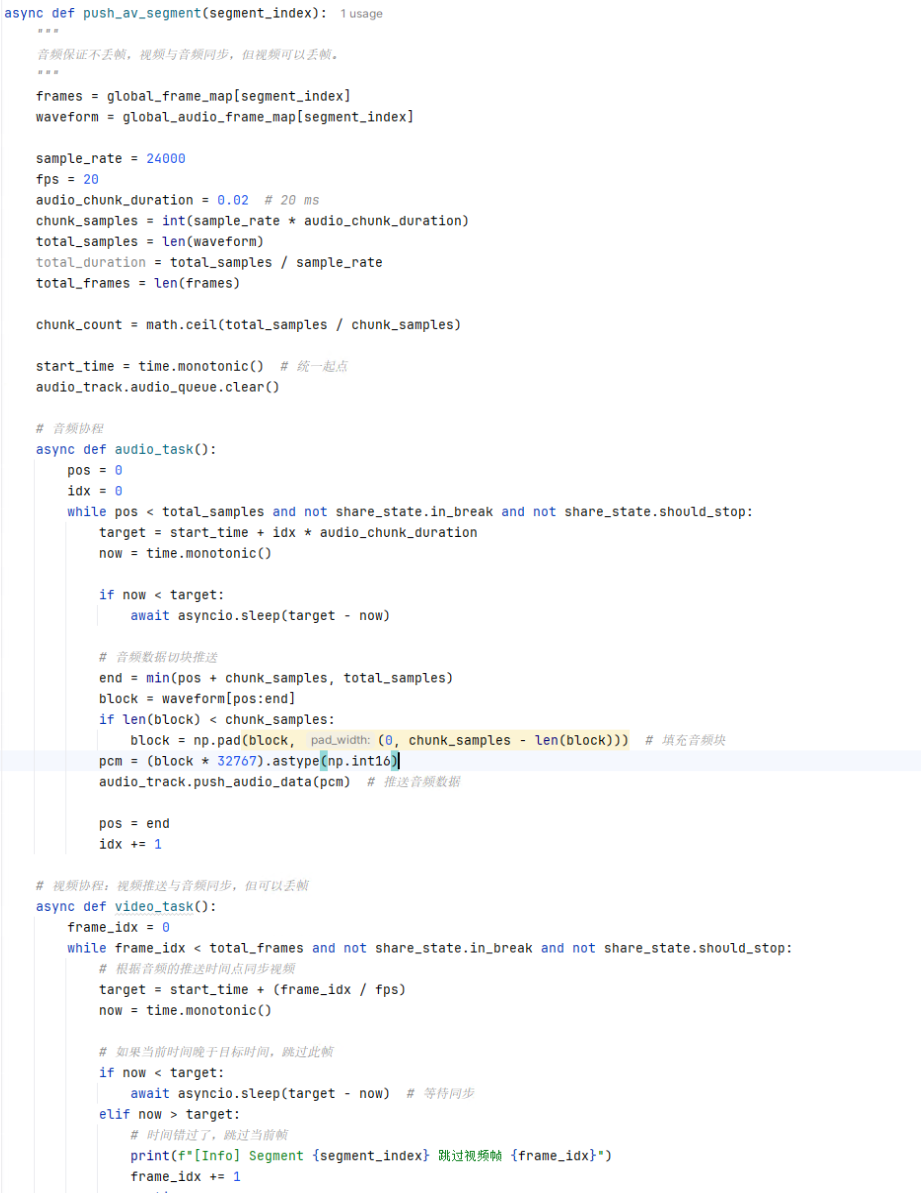
基于MuseTalk的二次开发以满足实时推理:适配Websocket实时基础架构,以满足实时推理要求。学了两天的python,就上手修改了。最难的还是对于音频的处理,包括修改核心源码的转码部分、说话打断时的音频队列处理逻辑、音频的分段处理算法策略等等。
WebRTC推流算法:从最开始的Websocket+Mainsource到WebRTC视频推流转变。从构建WebRTC应用,再到处理音频帧和图片帧同步问题,了解PTS,timebase等音视频相关知识,设计的推流算法。
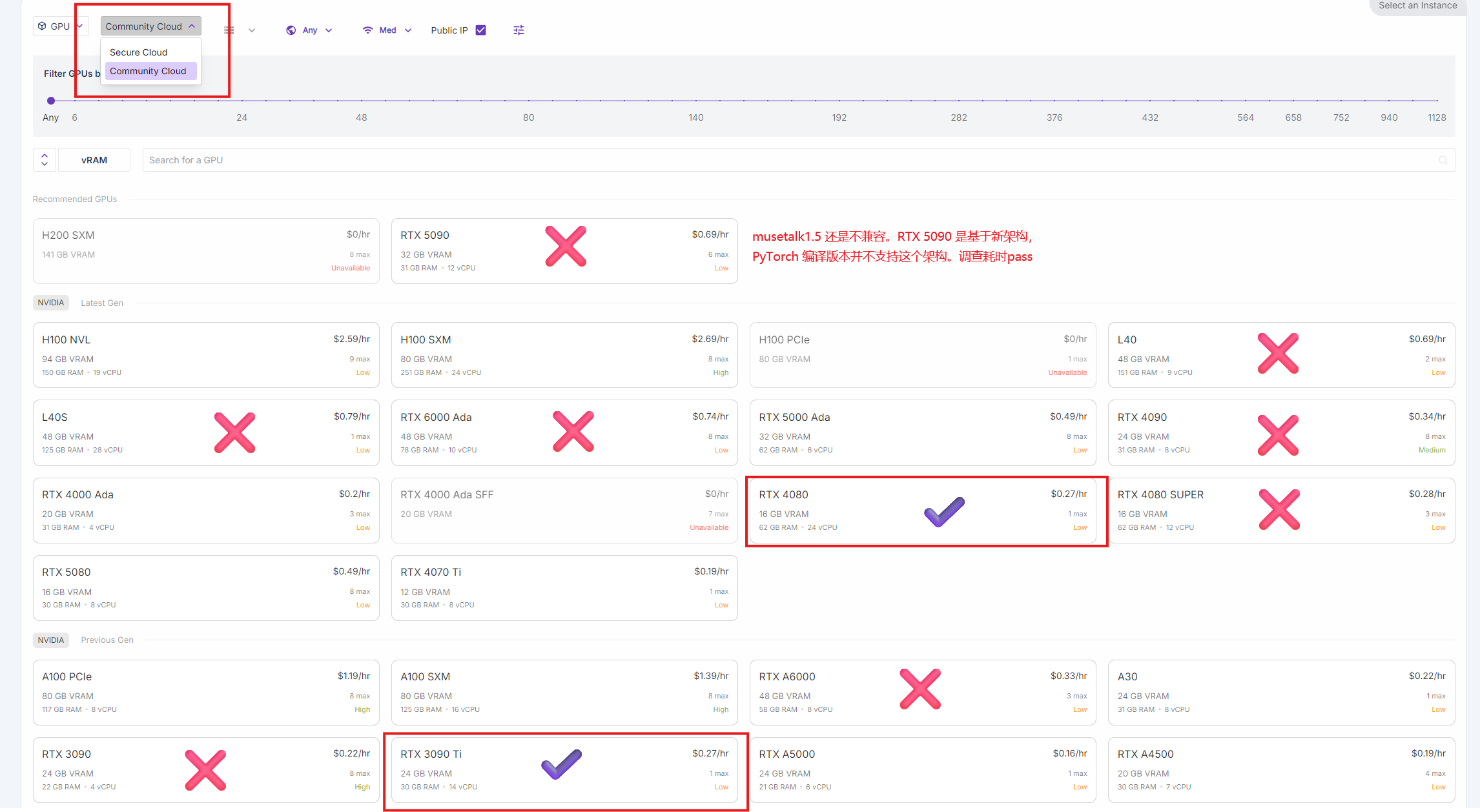
GPU选型和算力分离:将全部逻辑业务和生成视频需要使用的GPU算力服务完全分离,为租赁GPU算力适配高并发的弹性变化奠定基础。并了解GPU的各种性能,不断尝试性价比最高,且可行的GPU型号。
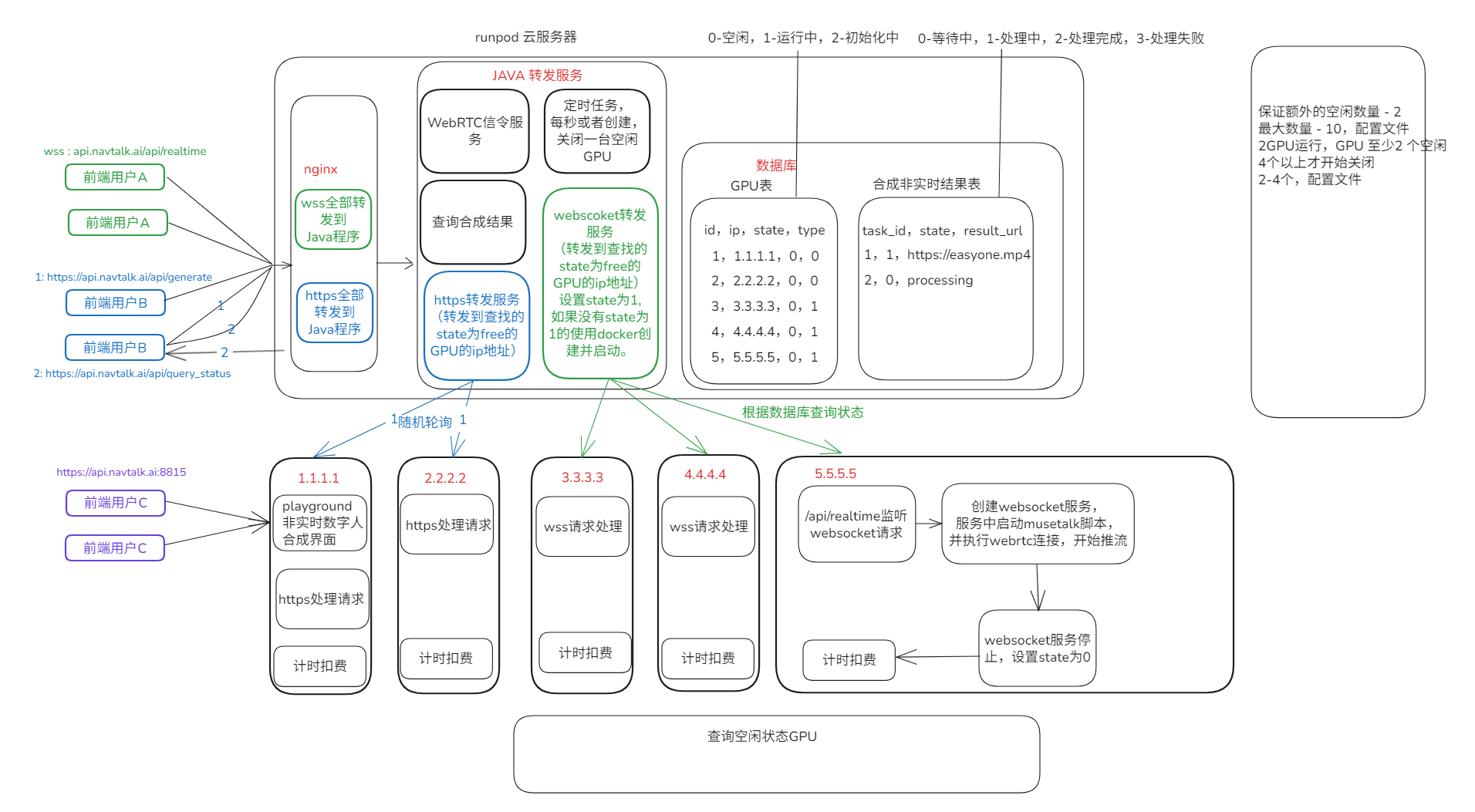
负载均衡:构建中转服务,对于实时和非实时的处理,查询空闲GPU状态。
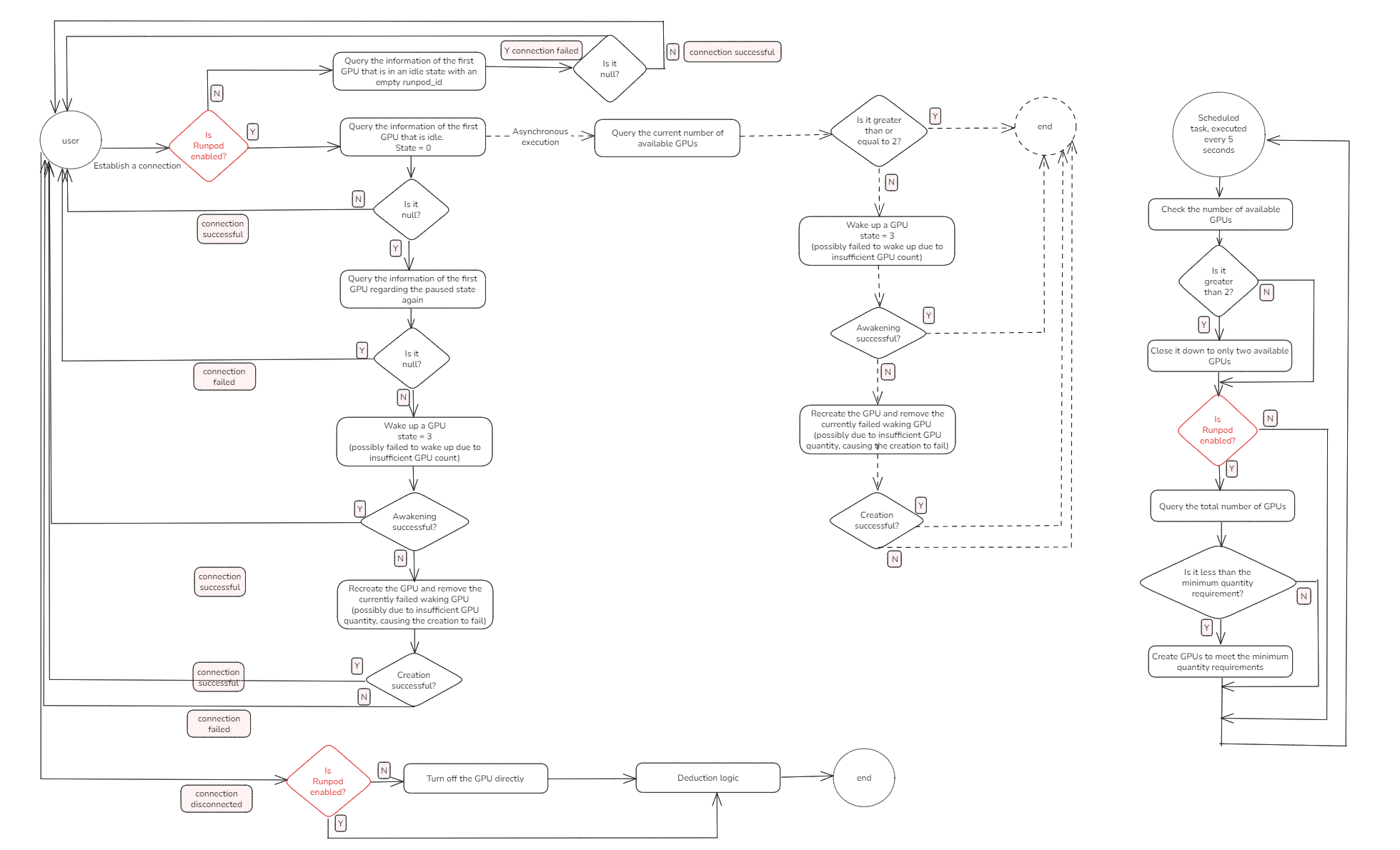
GPU集群架构:设计应对高并发时,采用合适的处理逻辑来应对GPU集群资源不足的情况。
 还有API文档编写,计费系统....东西太多了,不列举了。
还有API文档编写,计费系统....东西太多了,不列举了。
插个旗,等空了再写
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝
