


















.png)
数字人系列(10):NavTalk 高并发 GPU 架构详解
1. 引言:为什么 GPU 调度是数字人系统的核心挑战
在过去几个月里,NavTalk 一直致力于打造一个实时语音驱动的数字人系统。这个系统的核心目标很简单:让用户在任何场景下都能与数字人自然对话,并且获得与真人几乎无差别的交流体验。但要真正实现这个目标,其背后需要庞大的计算资源支撑,尤其是 GPU。
在早期的系统迭代中,我们首先解决了两个“看得见”的问题:
音画同步:通过优化音视频推流算法,实现了数字人嘴形与音频的毫秒级对齐。
响应延迟:通过模型推理加速和关键参数调整,使数字人响应较乎精神反应般快速。
然而,当这些基础体验问题逐步解决之后,一个新的、更具挑战性的矛盾浮现了:如何在高并发场景下稳定管理 GPU 资源。
考虑到 NavTalk 的用户量可能并不是线性增长,而是存在突发的高峰流量:比如某个在线直播活动、某次大规模的课堂互动,或者某个企业的批量培训场景。在这种高并发的使用场景下,如果 GPU 调度系统没有设计好,就可能出现:
GPU 被瞬间耗尽:新用户无法进入服务,直接连接失败。
GPU 分配混乱:部分用户被分配到不可用的 GPU,体验极差。
成本失控:一味扩容 GPU 虽然能缓解压力,但会带来巨大的费用开销。
换句话说,音画同步和延迟优化解决了“单个用户”的体验问题,而 GPU 调度则决定了“成千上万用户同时在线”时系统能否撑得住。这就是我们这次要重点讨论的核心挑战:如何构建一个既能动态扩展、又能稳定高效的 GPU 调度系统,让数字人服务在高并发场景下依然流畅运行。为此我们构建了一个初步的能应对高并发的架构。
2. 用户连接全链路流程
为了让大家更直观地理解 GPU 调度系统的设计,我们从最核心的用户连接流程开始讲起。这个流程对应着技术架构图的左半部分:当用户在前端页面打开数字人服务时,系统内部到底发生了什么?
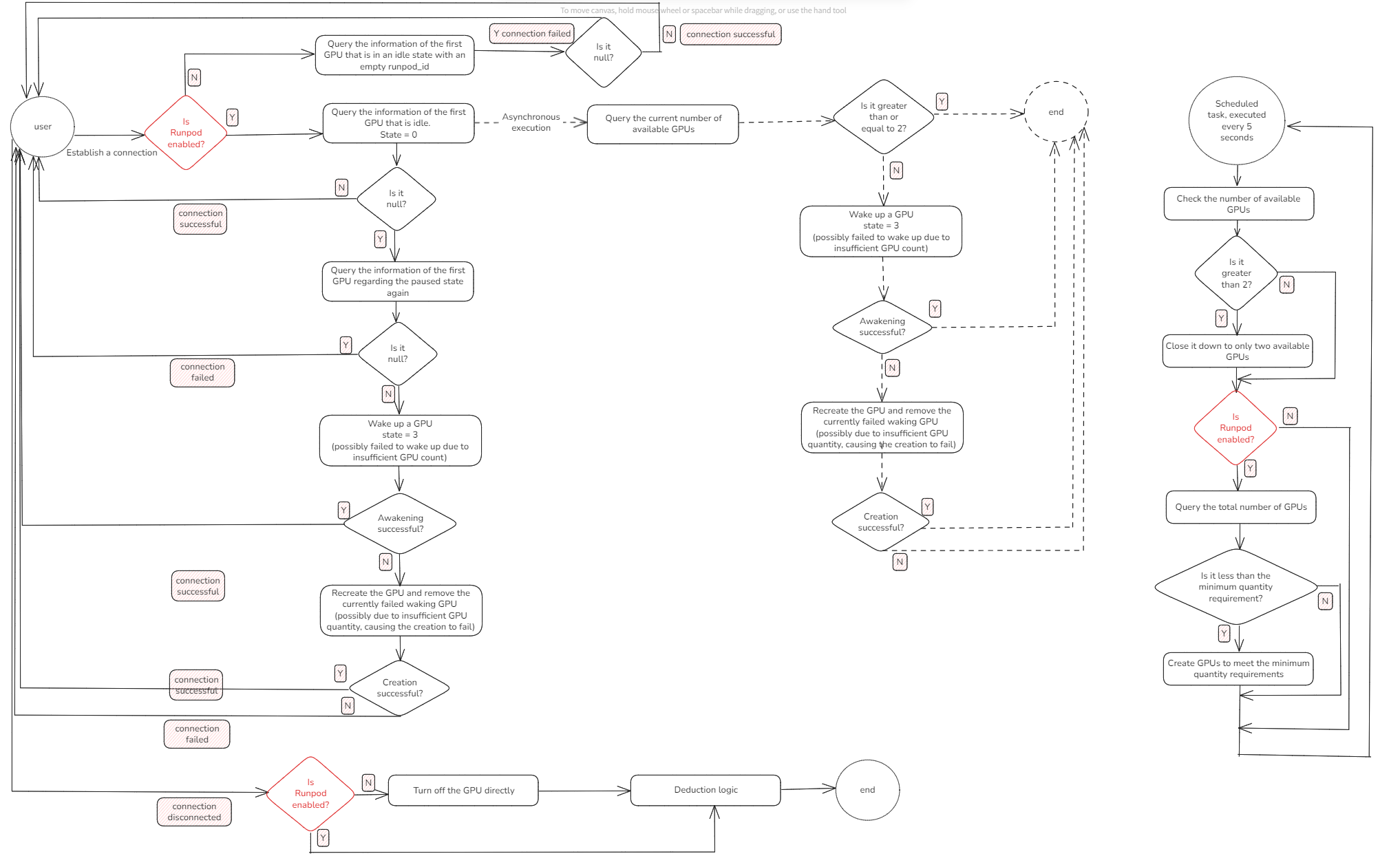
2.1 从点击页面到 GPU 分配
用户点击页面进入系统后,后端首先会尝试为这个连接分配一个 GPU。此时系统会做一个关键判断:是否启用了 Runpod 云端扩展。
💡 什么是 Runpod?
Runpod 是一个支持高性能计算(HPC)任务的云服务平台,提供基于 GPU 的弹性算力资源。与传统云平台不同,Runpod 主要面向 AI 推理、训练、视频渲染等高计算需求场景,支持通过 API 快速启动或销毁 GPU 实例。在本系统中,Runpod 被用作「云端 GPU 扩展池」,当本地资源耗尽时,系统会动态调用 Runpod 创建 GPU 实例,补充计算能力,确保高并发下服务稳定运行。
如果没有启用 Runpod
系统只会在本地数据库中查找是否存在空闲的 GPU(即state = 0的 GPU)。找到 → 分配给用户,继续建立连接。
找不到 → 连接失败,用户无法进入服务。
如果启用了 Runpod
系统会优先使用本地 GPU(runpod_id = null且空闲)。如果本地资源不足,则会尝试连接并创建 Runpod 云端的 GPU 实例。这样,系统就具备了“弹性扩展”的能力,保证高并发时也能继续接纳新用户。
2.2 GPU 的状态定义
在整个 GPU 生命周期中,我们使用 state 字段标记其当前状态:
| 状态值 | 描述 |
|---|---|
| 0 | 空闲(Idle):可被分配使用 |
| 1 | 运行中(Running):已被用户占用 |
| 2 | 失败(Failed):资源不可用,需销毁 |
| 3 | 暂停(Paused):实例存在但未运行 |
| Status Code | Description |
|---|---|
| 0 | Idle: Available for allocation |
| 1 | Running: Currently in use by a user |
| 2 | Failed: Resource unavailable and needs to be destroyed |
| 3 | Paused: Instance exists but is not running |
这个状态机是 GPU 调度的基础。每一次用户连接请求,都会围绕这些状态进行流转与判断。
2.3 建立连接与失败处理机制
当成功分配到一块 GPU 后,系统会尝试与其建立 WebSocket 等连接:
连接成功
GPU 状态更新为running,用户立即进入服务。连接失败
系统进入容错逻辑,依次执行以下步骤:查询暂停状态的 GPU(
state = 3)
如果存在,尝试唤醒它 →
唤醒成功则重新连接;唤醒失败则执行销毁。重新创建 GPU 实例
销毁不可用 GPU → 调用本地或 Runpod 创建流程 →
创建成功则再次尝试连接;若仍失败,说明系统已无可用 GPU 资源。资源枯竭处理
本地和云端资源都已耗尽,系统将返回连接失败提示,用户需等待下次资源释放。
2.4 流程总结
这一整套逻辑,保证了在 GPU 资源有限、并发请求高峰的情况下,系统不会直接让用户“白屏”或“掉线”。
优先使用空闲 GPU
资源不足时尝试唤醒暂停 GPU
唤醒失败则销毁并重建
彻底资源枯竭时,才会返回连接失败
这种容错 + 弹性设计,让系统在高并发情况下依然能维持较高的可用性。
3. 高并发下的异步线程机制:为下一个用户提前准备 GPU
在实际运行中,我们观察到这样一个现象:用户连接 GPU 时,如果系统刚好没有空闲资源,就必须等待 GPU 被唤醒或新建。而这个等待过程(无论是唤醒还是创建)通常要几秒甚至几十秒,严重影响用户体验。
为了解决这个问题,我们在每次成功连接 GPU 后,都会异步启动一个后台线程任务,尝试提前准备好下一块 GPU。这个线程的执行不影响当前用户连接速度,但可以显著提升下一个用户的“秒连”概率。这个流程对应着技术架构图的中间部分:
异步线程的作用是什么?
在当前用户拿到 GPU 后立即启动;
在后台异步唤醒一块处于暂停状态(state = 3)的 GPU;
如果没有暂停的 GPU,再异步触发新建 GPU 实例(Runpod);
不阻塞前端连接逻辑,真正做到边服务边准备下一块资源。
举个例子:
用户 A 成功连接 → 系统后台异步启动线程 → 尝试唤醒或创建下一块 GPU → 用户 B 点击进入时,就有 GPU 可以直接用。
为什么这样做很重要?
GPU 的唤醒或创建操作是“慢操作”(可能要几秒甚至更久),而连接请求是“快操作”。如果等用户来了再准备资源,就注定慢一步。而我们现在的策略是:
用户来了再连,GPU要先准备好。
这样,绝大多数用户连接时,GPU 都已经提前准备好,极大提升了连通率和响应速度。
4. Runpod 弹性扩展:动态增减 GPU 保证资源充足又不浪费
为了兼顾系统性能与成本控制,我们在 NavTalk 的 GPU 调度系统中引入了对 Runpod 的弹性调度机制。目标很明确:
不浪费 GPU 资源(节约云计算成本)
又能应对突发高并发流量(不让用户连接失败)
核心设计就两个参数 + 一个定时任务。这对应图中的右半部分:
4.1 两个关键参数:MIN_RUNNING_GPU 与 FREE_RUNNING_GPU
我们通过两个配置项控制系统中 GPU 的扩缩策略:
| 参数名 | 说明 | 举例 |
|---|---|---|
| MIN_RUNNING_GPU | 最少要维持的 GPU 数量,无论有没有用户,都要保持这么多 GPU 运行,以防突发 | 如设置为 5,则系统空闲也要维持至少 5 块 GPU |
| FREE_RUNNING_GPU | 系统允许保留的最大空闲 GPU 数量,如果超过这个值,就会主动释放 | 如设置为 2,则 GPU 空闲数超过 2 就回收 |
| Parameter | Description | Example |
|---|---|---|
| MIN_RUNNING_GPU | The minimum number of GPUs that must be kept running at all times, regardless of user activity, to handle sudden demand | If set to 5, the system will keep at least 5 GPUs running even when idle |
| FREE_RUNNING_GPU | The maximum number of idle GPUs allowed to stay running; if exceeded, the system will actively release them | If set to 2, any idle GPUs beyond 2 will be released |
这两个参数共同决定了系统 GPU 的最小保底和最大闲置空间,帮助系统在可用性与成本之间取得平衡。
4.2 每 x 秒执行一次定时任务,自动调度资源
我们设计了一个轻量级的调度器,每 x 秒执行一次巡检任务,逻辑如下:
检查空闲 GPU 数量(
state = 0);如果空闲数 > FREE_RUNNING_GPU:
主动回收空闲资源,优先释放 Runpod 云 GPU;
由于 Runpod 云 GPU 是按照运行时间计费的,如果没有合理释放机制,很容易在并发高峰后留下大量空闲云资源,造成不必要的支出。
因此,在释放 GPU 时我们做了明确优先级判断:
优先释放 Runpod 创建的 GPU;
保留本地部署的 GPU(不计费);
确保系统仍保有最低数量(
MIN_RUNNING_GPU)的运行资源。这样既保证了服务能力,也控制了运营成本。
如果空闲数 < MIN_RUNNING_GPU:
自动启动 GPU 创建流程,向 Runpod 请求新实例;
检查当前 GPU 总数是否达标,防止资源不足影响用户连接。
因为 GPU 创建需要一定时间,同时,当用户量突然暴增时,原本的 GPU 资源池可能很快被用光。我们通过合理配置
MIN_RUNNING_GPU提前保留一点缓冲空间(比如设置为 3~5),这样可以在瞬时高峰中迅速吸收压力。
这个定时器不断循环运行,确保系统时刻处于「不多不少刚刚好」的状态。
5. 大客户独立部署 GPU:自有资源、隔离调度、服务稳定
NavTalk 面向的用户群体中,既包括大量短时使用的 C 端用户,也服务一些具有高频、长时段使用需求的企业大客户。为了兼顾这两类用户的体验,我们设计了共享资源池 + 外部独立部署的双轨架构:
普通用户:通过共享 GPU 资源池进行统一调度;
企业客户:通过自费租赁 GPU,并将服务独立部署在客户指定环境中;
系统会主动避开这些 GPU,不参与调度和释放,实现彻底隔离。
5.1 为什么采用“共享 + 自主租用”的双轨机制?
GPU 是高价值资源,在并发高峰时尤为紧张。我们曾遇到一些客户,因使用场景特殊,需要数字人服务始终保持运行不中断,例如:
数小时不间断的线上直播;
全天候部署的企业数字助理;
高频调用、多用户并发访问的大型交互系统。
如果这类客户的访问仍依赖共享 GPU 池,会存在几个风险:
GPU 被长时间占用,普通用户连接率下降;
异常释放后重连代价高,影响客户稳定性;
公共资源池调度复杂度上升,难以统一管理。
因此,我们采用了更清晰的划分机制:
对这类客户提供单独部署建议;
客户可根据需求自行在 Runpod、AWS 或本地部署 GPU;
NavTalk 服务以“专属部署 + 私有接入点”方式运行,完全脱离共享调度体系;
系统内部逻辑会检测来源,自动跳过这些 GPU 实例,不纳入调度与释放流程。
6. 架构图详细解读:一次 GPU 请求从触发到释放的全过程
在 NavTalk 实时语音系统中,我们构建了一整套 GPU 调度和生命周期控制机制,保障数字人服务在面对大量用户并发接入时仍能稳定运行。而这套机制的全貌,正体现在当前的系统架构图中。
本节将结合架构图,从左到右梳理一次典型的连接请求如何在系统中被处理,包括 GPU 分配、资源状态变更、异步创建、连接建立与调度回收等关键步骤。
6.1 用户发起请求:连接入口与线程调度
用户点击网页前端的“启动数字人”按钮后,前端会通过 WebSocket 或 HTTP 请求与后端服务建立连接。后端立即进入连接处理流程:
创建一个线程任务(由线程池调度)处理该用户的 GPU 分配请求。
系统判断当前是否启用了 Runpod 云 GPU 支持:
若未启用,仅使用本地部署的 GPU。
若启用,则具备本地 GPU + 云 GPU 的联合调度能力。
6.2 GPU 分配优先级:空闲 → 唤醒 → 创建
在 GPU 分配过程中,系统会按如下优先级尝试分配资源:
查找空闲 GPU(
state = 0)
若资源池中有未被使用的 GPU,立即分配并建立连接。尝试唤醒暂停的 GPU(
state = 3)
若无空闲资源,系统尝试唤醒已暂停的 GPU。唤醒成功即进入连接流程;唤醒失败则转入销毁逻辑。异步创建新 GPU 实例
无空闲、可唤醒资源时,系统直接触发 GPU 创建流程,无需等待资源“耗尽”才执行。若开启 Runpod,会调用其 API 创建云端 GPU 实例;
否则,尝试启动本地 GPU;
创建是异步进行的,线程不会阻塞等待。
这意味着:每一个用户连接都会触发一次 GPU 唤醒或创建任务,以保证资源充足供后续用户使用。
6.3 建立连接与状态变更
当某个线程获取 GPU 后,将尝试建立连接:
若连接成功,该 GPU 状态变为
running,用户可以实时访问数字人服务。若连接失败(如端口不可达、WebSocket 异常等),系统会:
尝试释放该 GPU 并重建;
或标记为
failed状态,等待调度器后续清理。
资源状态管理是整个系统稳定性的基础,连接过程中会动态记录 GPU 状态,以便调度器获取最新资源视图。
6.4 资源回收与定时任务调度器
系统中内置了一个轻量级调度器,每隔固定时间(通常为 5 秒)执行一次资源检测与调度任务:
释放多余空闲 GPU:
若
idleGPU 数量 >FREE_RUNNING_GPU;优先释放 Runpod 创建的云端资源,避免计费浪费;
保留本地 GPU 以节省成本。
补充 GPU 容量:
若 GPU 总数 <
MIN_RUNNING_GPU;启动异步创建流程,保持资源预热,防止短期并发冲击导致连接失败。
通过这个定时机制,系统能够在无人为干预的情况下,自动调整 GPU 数量,实现“动态伸缩”。
7. 未来展望:从规则驱动走向智能调度
当前的 NavTalk GPU 调度系统,已基本具备高并发支持能力、资源弹性管理能力与服务稳定性保障能力。但我们也清楚地认识到,系统目前仍然依赖于人为配置的规则(如是否开启 Runpod、GPU 启动阈值等)。为了更好地支持未来更复杂、更动态的使用场景,我们正在规划进一步的能力演进。
7.1 Runpod 云服务开启的智能判断策略
目前 Runpod 是否启用仍通过手动配置控制。未来,我们计划基于用户活跃度、GPU使用趋势等指标,自动判断是否启用云端 GPU 支持。这样可以避免资源浪费,同时保证在需要时具备即时扩展能力。
7.2 GPU 启停策略将引入智能算法
现阶段的 MIN_RUNNING_GPU 与 FREE_RUNNING_GPU 参数是静态配置,调度逻辑也较为规则化。我们未来会引入更加智能的 GPU 启停策略,动态调整 GPU 保有量,使资源利用率与成本之间取得更优平衡。
7.3 用户排队机制将逐步引入
在极端并发情况下,如果所有 GPU 被占用,当前系统会直接返回“连接失败”。未来,我们将设计一套前端可感知的用户排队机制,保障用户体验的透明性与公平性。用户可以看到排队位置与预计等待时间,系统则会根据队列状态智能触发 GPU 启动逻辑。
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝
