


















.png)
数字人系列(8):音视频同步算法与 WebSocket TIME_WAIT 问题
一、前言:构建“实时感”系统的双重挑战
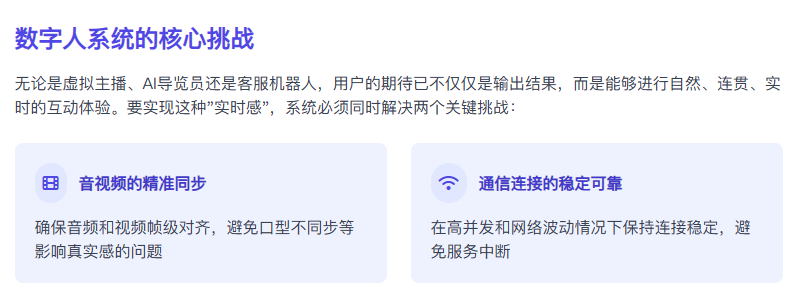
在当下的 AI 应用浪潮中,数字人系统正在迅速从“内容生成工具”演变为“可交互的智能体”。不论是虚拟主播、AI 导览员,还是数字人客服、陪伴型机器人,我们对它们的要求已不再是单向输出,而是具有真实感、连贯性与稳定性的实时交互体验。
而要实现这样的“实时感”,并非只靠语音合成、动画驱动或者模型能力就足够了。从系统工程角度看,一个成功的数字人系统必须同时解决两个核心问题:
第一,是如何做到“说得准”——也就是音视频同步精确。当数字人发声时,画面中嘴型必须跟得上语音节奏,不能出现延迟、错帧或静音画面。如果说得对嘴、神态协调,用户才会有“她真的在和我说话”的感受。
第二,是如何保证“活得稳”——也就是连接状态稳定可靠。在高并发或网络不稳定环境下,频繁的连接断开重连不仅影响用户体验,还可能拖垮整个系统资源。尤其在使用 WebSocket 作为实时信令通道时,TCP 的
TIME_WAIT状态管理不当,会导致系统连接端口迅速被耗尽,影响新连接建立。
这两个问题,一个关乎用户体验质量,一个关乎系统稳定性与可扩展性。前者决定了数字人“看起来是否真实”,后者决定了系统“能否长期运行”。
在我们的实际项目中,这两方面都曾经历过反复调试与结构重构。我们从音视频不同时间轴的对齐入手,结合 WebRTC 协议栈和 Python 异步调度机制,构建了一套帧级同步的媒体推送模型。同时,也在 WebSocket 通信层面深入分析 TCP 状态管理机制,优化 TIME_WAIT 导致的连接阻塞与资源耗尽问题。因此,这篇博客将围绕这两个问题展开:(1)如何通过帧级控制实现 WebRTC 的音视频同步;(2)如何在高并发场景下优化 WebSocket 的连接管理,规避 TIME_WAIT 陷阱。
这既是一份技术方案的还原,也是我们在构建数字人底层通信系统过程中的一段经验记录。希望对正在构建实时 AI 交互系统的你,也能带来一些启发与实用参考。
二、精确同步:音视频协调的幕后机制
在数字人系统中,音视频同步不仅关乎体验质量,更直接决定了拟人交互的真实感。一旦画面与语音不同步,即使语义正确、语调自然,也会让人感觉“出戏”。在这部分,我们将深入剖析一套基于 WebRTC + Python 的实时同步推送机制,从底层架构到协程调度,全面还原音视频“对嘴输出”的实现逻辑。
2.1 同步为何难:技术层面上的非对称性
音视频的同步在概念上看似简单——让“嘴型”对得上“声音”,实则涉及多个技术难点:
音频数据的特性:通常为流式、体积小,采样频率高(如 24kHz),每 20ms 推送一块数据,传输粒度较细。
视频帧的特性:图像帧大、计算开销高,帧率有限(如 30FPS),处理与网络传输更易引发延迟或丢帧。
时间对齐的复杂性:两类媒体使用不同的采样率和时间单位,系统需统一时钟基准,确保它们能“看起来同步”。
这些差异使得音视频在工程上进行帧级同步不仅是时序问题,更涉及系统设计、时间轴建模、任务调度和延迟容忍度的权衡。
2.2 系统架构与关键模块
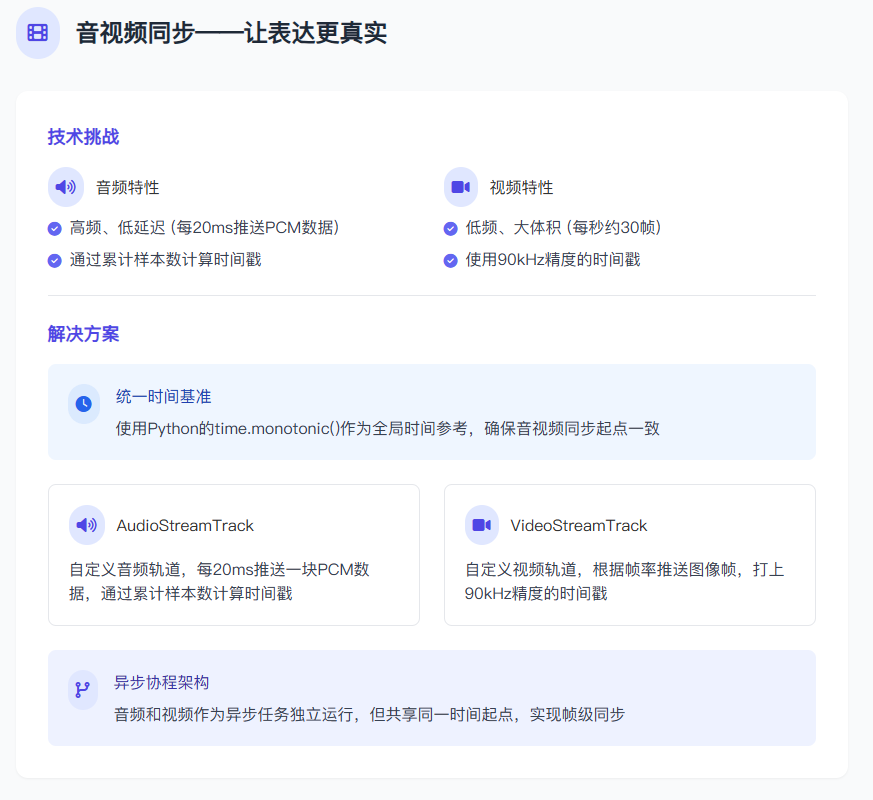
为实现低延迟、高可控的实时传输,本系统采用如下核心架构:
媒体通道:基于 WebRTC 的低延迟传输
通过
aiortc实现自定义的AudioStreamTrack与VideoStreamTrack
流轨设计:
SingleFrameVideoStreamTrack:每次recv()返回当前帧图像,基于time.monotonic()计算 PTS(单位 90kHz)SingleFrameAudioStreamTrack:以recv()拉取方式发送音频 PCM 数据,单位为 20ms 一个块,使用 sample 数进行累计
这两条轨道通过统一的“推送任务” push_av_segment() 启动,并共享同一个起始时间基准。详细构建如下:
2.2.1 SingleFrameVideoStreamTrack:帧级可控的视频轨道
class SingleFrameVideoStreamTrack(VideoStreamTrack):
def __init__(self, frame=None, fps=30):
super().__init__()
self._current_frame = frame if frame is not None else np.zeros((2160, 3840, 3), dtype=np.uint8)
self._start_time = time.monotonic()
self._time_base = fractions.Fraction(1, 90000) # 90kHz timebase
self._fps = fps
async def recv(self):
elapsed = time.monotonic() - self._start_time
pts = int(elapsed * 90000) # Timestamp in 90kHz
if isinstance(self._current_frame, VideoFrame):
frame = self._current_frame
else:
frame = VideoFrame.from_ndarray(self._current_frame, format="bgr24")
frame.pts = pts
frame.time_base = self._time_base
return frame
async def update_frame(self, new_frame):
if isinstance(new_frame, VideoFrame):
arr = new_frame.to_ndarray(format="bgr24")
else:
arr = new_frame
self._current_frame = arr关键特性解析:
recv()是 WebRTC 拉取视频帧的核心方法。每调用一次就返回一帧图像;使用
monotonic()计算经过时间,并乘以 90000,生成标准 WebRTC PTS;外部通过
update_frame()更新当前图像帧,下一次recv()就会返回这张新帧;time_base为 1/90000,是视频行业常用的时钟单位;由于帧不主动送出,而是被 WebRTC 拉取,因此时间控制权实际上掌握在系统播放节奏上。
2.2.2 SingleFrameAudioStreamTrack:精细切块的音频轨道
class SingleFrameAudioStreamTrack(AudioStreamTrack):
kind = "audio"
def __init__(self, sample_rate=24000, channels=1):
super().__init__()
self.sample_rate = sample_rate
self.channels = channels
self._time_base = fractions.Fraction(1, sample_rate)
self.audio_queue = deque(maxlen=100)
self._samples_sent = 0
async def recv(self):
if self.readyState != "live":
raise MediaStreamError
while not self.audio_queue:
await asyncio.sleep(0.001)
pcm = self.audio_queue.popleft()
samples = pcm.shape[0]
frame = AudioFrame(format="s16", layout="mono", samples=samples)
frame.sample_rate = self.sample_rate
frame.time_base = self._time_base
frame.planes[0].update(pcm.tobytes())
frame.pts = self._samples_sent
self._samples_sent += samples
return frame
def push_audio_data(self, pcm_int16: np.ndarray):
self.audio_queue.append(pcm_int16)关键特性解析:
使用 一个音频缓冲队列(
deque)缓存 20ms 小块的 PCM 音频;recv()每次取出一块音频,计算该块samples数,并设置对应的 PTS;pts = self._samples_sent表示累计已发送的样本数;time_base = 1/24000,因为采样率是 24000 Hz;外部通过
push_audio_data(pcm)来不断塞入新的音频块(在audio_task()中执行);recv()和视频不同,它是持续被 WebRTC 拉取,因此系统必须确保队列始终有新数据,否则会断流。
2.3 时间轴对齐机制
音视频同步的核心不是“统一帧率”,而是“统一时间起点 + 独立节奏推进”。在本系统中,这一机制通过 push_av_segment() 方法实现。
2.3.1 统一时间基准:start_time = time.monotonic()
start_time = time.monotonic()使用 Python 的 monotonic() 函数获取单调递增的系统时间,避免因系统时钟跳变导致时间轴错乱。此 start_time 成为音频和视频协程的共同参考起点,确保两个轨道“在同一时间开始跑”。
2.3.2 音频协程:每 20ms 精准推送一个音频块
sample_rate = 24000
audio_chunk_duration = 0.02 # 20 ms
chunk_samples = int(sample_rate * audio_chunk_duration)
async def audio_task():
pos = 0
idx = 0
while pos < total_samples and not share_state.in_break and not share_state.should_stop:
# Calculate when to push the next audio chunk
target = start_time + idx * audio_chunk_duration
now = time.monotonic()
if now < target:
await asyncio.sleep(target - now)
# Slice and normalize PCM samples
end = min(pos + chunk_samples, total_samples)
block = waveform[pos:end]
if len(block) < chunk_samples:
block = np.pad(block, (0, chunk_samples - len(block)))
pcm = (block * 32767).astype(np.int16) # Convert float32 to int16 PCM
audio_track.push_audio_data(pcm) # Send to aiortc AudioStreamTrack
pos = end
idx += 1解释要点:
每 20ms 推送一次数据,精确控制节奏;
将 float PCM 音频归一化后转为 16bit 整数格式;
调用
audio_track.push_audio_data(pcm)将数据送入队列,由recv()提取送出;时间对齐通过
target = start_time + idx * 0.02精确定位每一块应当播放的时刻。
2.3.3 视频协程:每帧依帧率精准更新,并打上 pts
fps = 30 # Video frame rate
async def video_task():
for i in range(frame_count):
if share_state.in_break or share_state.should_stop:
break
# Calculate when to show the i-th frame
target = start_time + i / fps
now = time.monotonic()
if now < target:
await asyncio.sleep(target - now)
img = frames[i]
vf = VideoFrame.from_ndarray(img, format="bgr24")
# Stamp pts using elapsed time in 90kHz units
t_sec = time.monotonic() - start_time
vf.pts = int(t_sec * 90000)
vf.time_base = fractions.Fraction(1, 90000)
await track.update_frame(vf)解释要点:
每一帧都等到确切播放时间后才推送;
使用
time.monotonic()与起始时间start_time计算经过时间;然后通过
pts = t_sec * 90000转换为 WebRTC 视频使用的90kHz 时基单位;update_frame(vf)更新当前帧数据,供recv()发送给 WebRTC 引擎。
2.3.4 并行执行:音视频异步协程启动
task_a = asyncio.create_task(audio_task())
task_v = asyncio.create_task(video_task())
await task_a
task_v.cancel() # Stop video task once audio ends解释:
音频与视频各自跑在独立的协程中,互不阻塞;
音频任务完成后主动取消视频任务,保证播放周期对齐;
这种架构为帧级同步提供了良好的容错与可控性。
2.3.5 总结:时间对齐机制的关键点
| 机制 | 实现方式 | 功能说明 |
|---|---|---|
| 时间统一基准 | start_time = time.monotonic() |
精确同步起点 |
| 音频节奏控制 | 每 20ms 切片推送 + 睡眠控制 | 精细控制声音节奏 |
| 视频帧时间戳 | pts = elapsed_time * 90000 |
准确对应画面时间 |
| 异步非阻塞 | asyncio.create_task() |
避免互相干扰、降低抖动 |
| 精度保证 | 使用 Fraction(1, 90000) 与 int16 PCM |
满足 WebRTC 对时基与采样精度要求 |
三、WebSocket 与 TIME_WAIT 状态深析
如果说音视频同步是“说得准”的技术核心,那么连接管理就是“活得稳”的系统地基。在真实部署环境中,我们注意到一个被许多实时系统忽略的痛点:TIME_WAIT 状态堆积导致 WebSocket 连接难以维持稳定性。本章将聚焦这个问题,从 TCP 协议原理讲起,逐步分析 WebSocket 在高并发场景下的连接风险,并给出系统级与架构级的缓解策略。
3.1 TIME_WAIT 的设计初衷
TIME_WAIT 是 TCP 协议中一个必要的安全机制,并非错误状态。其背景来源于连接的关闭流程——TCP 四次挥手:
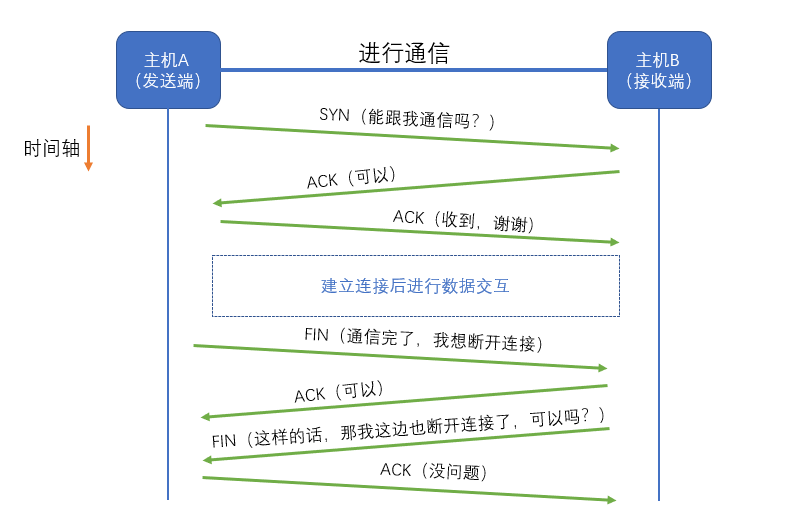
客户端发起 FIN:表示“我不再发送数据了”;
服务端回应 ACK:确认收到;
服务端发送 FIN:通知“我也发送完了”;
客户端回应 ACK:连接关闭。
此后,客户端进入 TIME_WAIT 状态,持续 2MSL 时间(通常为 30~120s),以确保最后一条 ACK 报文可靠送达,并阻止潜在的“旧连接干扰新连接”。
TIME_WAIT 的设计目的:
防止残留数据包混入新连接;
确保服务端已完全收到 ACK,避免重传;
避免端口重用引发连接混淆。
所以,从协议角度看,TIME_WAIT 并非问题,而是"设计之善意"。但当这个机制出现在 WebSocket 频繁连接/断开场景中,问题就来了。
3.2 WebSocket 中 TIME_WAIT 爆发的典型场景
3.2.1 问题一:频繁断开连接,导致 TIME_WAIT 堆积
在以下常见业务或开发行为中,TIME_WAIT 连接迅速累积:
调试过程中短连接不断重建;
心跳逻辑异常,频繁断连重连;
服务端或中间件崩溃,客户端不断重试;
客户端为规避断流问题,主动定期重连。
由于 WebSocket 建立在 TCP 之上,而WebSocket 客户端通常为主动发起连接者,因此 TIME_WAIT 状态主要堆积在客户端或 API 网关侧。
3.2.2 问题二:高并发连接压力下,系统端口枯竭
TIME_WAIT 堆积会直接导致:
本地端口资源(65535个)迅速耗尽;
导致
connect()返回Address already in use错误;新连接创建失败,业务请求阻断;
系统表现为“间歇性断流”、“客户端连不上”等难以复现的问题。
3.3 从系统到底层的缓解方案
为解决上述问题,可从操作系统内核、socket 配置等层面做优化。
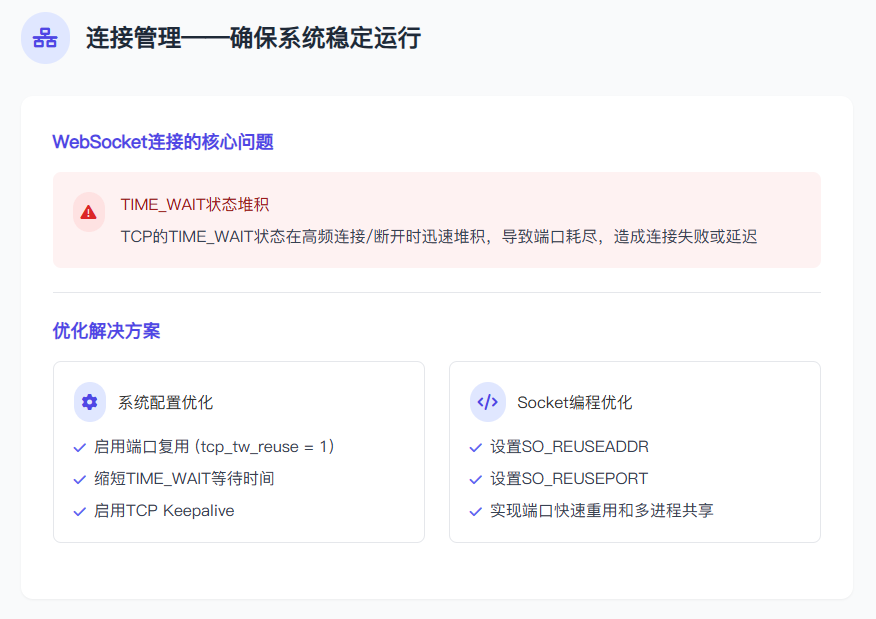
3.3.1 操作系统参数优化(Linux)
可通过 sysctl 调整以下参数,减少 TIME_WAIT 影响:
# 启用连接重用(推荐)
net.ipv4.tcp_tw_reuse = 1
# 减少连接保留时间(适度降低)
net.ipv4.tcp_fin_timeout = 30
# TCP 保活机制(确保连接不假死)
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_keepalive_intvl = 30
net.ipv4.tcp_keepalive_probes = 3windows中通过
netsh int tcp set global TcpTimedWaitDelay=30命令,设置存活时间为30秒
3.3.2 Socket 层配置建议
在 WebSocket 服务器端/客户端代码中设置:
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEPORT, 1)SO_REUSEADDR:允许快速重用处于 TIME_WAIT 状态的端口;SO_REUSEPORT:多进程/线程复用监听端口,提高系统扩展性。
四、结语:稳定的系统,是体验的地基
在构建数字人系统的过程中,“是否能对嘴说话”听起来像个 UX 问题,实则是技术体系成熟度的投影。而“是否能持续在线”更是底层工程稳定性的试金石。
音视频同步与连接管理,这两个看似分离的问题,其实分别决定了:
体验的真实感 —— 语音和嘴型对得上,用户才相信这是“人”;
系统的可持续性 —— 连接不断、状态稳定,用户才觉得“活着”。
数字人是一种极度依赖“实时感”的交互形式。你以为你在做 AI,其实你在做流媒体;你以为你在写 WebSocket,其实你在设计操作系统和网络协议边界的容错系统。
稳定,不是附属品,它是用户信任的前提,是体验真实的地基。
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝
