


















.png)
OpenAvatarChat:系统架构和Handler协作机制的详细说明
OpenAvatarChat:系统架构和Handler协作机制的详细说明
📋 目录
一、整体架构
1.1 系统层次结构
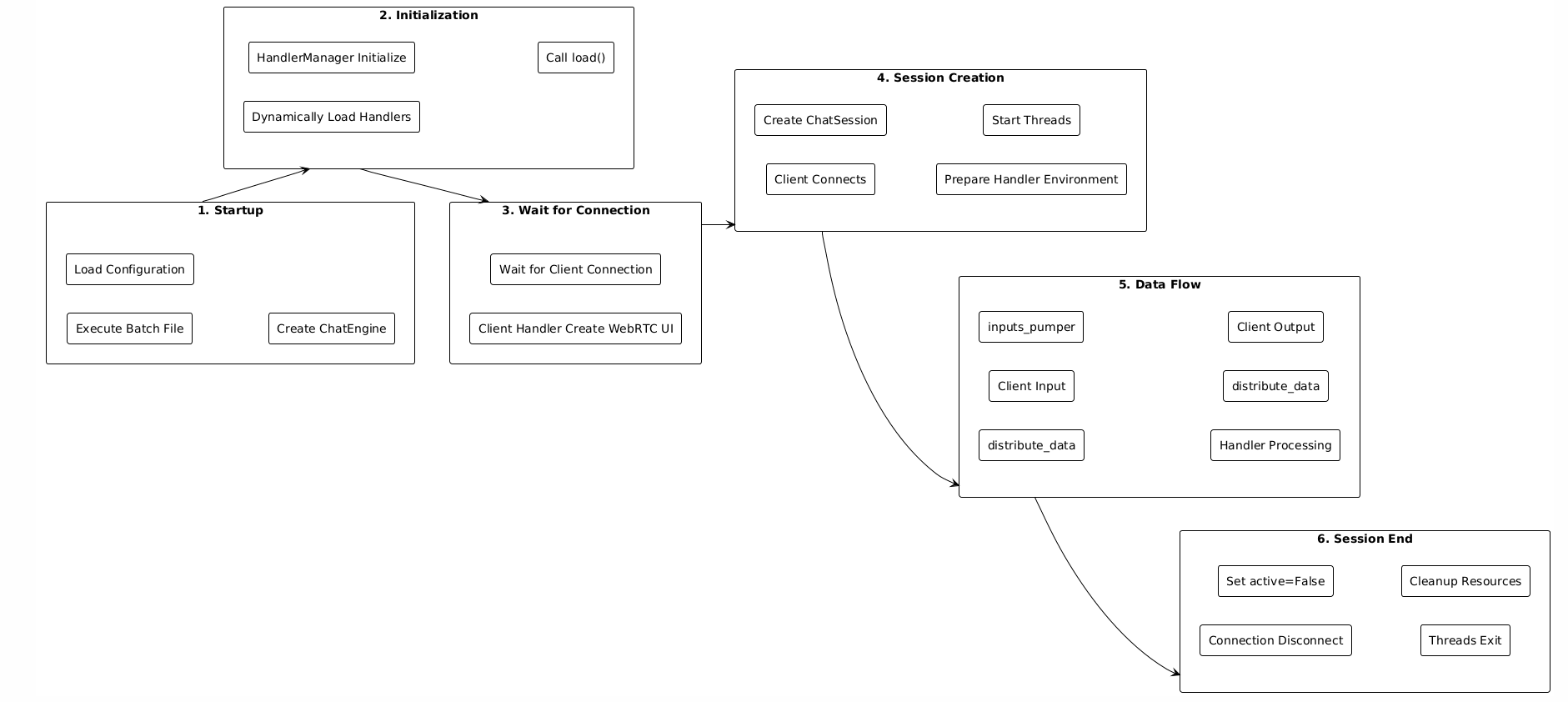
OpenAvatarChat采用分层架构,从顶层到底层分为三个层次:
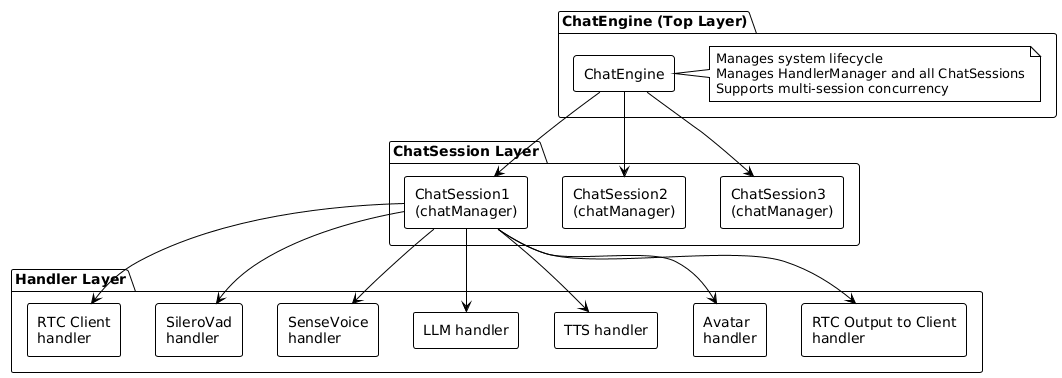
架构说明:
-
ChatEngine(顶层)
- 系统核心,管理整个对话引擎
- 负责初始化、配置加载、Handler管理
- 支持多会话并发,每个会话独立运行
-
ChatSession(中间层)
- 对应一个用户会话(一个WebRTC连接)
- 管理该会话中的所有Handler实例
- 管理数据流转、线程、队列
-
Handler(底层)
- 功能模块,负责具体任务处理
- 包括:RTC客户端、VAD、ASR、LLM、TTS、Avatar等
- 每个Handler在会话启动时创建独立实例
1.2 核心组件说明
ChatEngine (src/chat_engine/chat_engine.py)
职责:
- 系统初始化和管理
- HandlerManager的创建和初始化
- 会话的创建和销毁
- 多会话并发管理
关键方法:
def initialize(engine_config, app=None, ui=None)
# 初始化HandlerManager
# 加载所有Handler
# 设置客户端Handler
def create_client_session(session_info, client_handler)
# 创建新的ChatSession
# 准备Handler环境
# 返回会话和Handler环境
def stop_session(session_id)
# 停止并销毁会话
HandlerManager (src/chat_engine/core/handler_manager.py)
职责:
- 从配置文件动态加载Handler模块
- 注册Handler实例
- 管理Handler生命周期
关键数据结构:
handler_registries = {
"RtcClient": HandlerRegistry(
base_info=HandlerBaseInfo(...),
handler=RtcClient实例,
handler_config=配置对象
),
"SileroVad": HandlerRegistry(...),
...
}
ChatSession (src/chat_engine/core/chat_session.py)
职责:
- 管理单个会话的数据流
- 创建和管理Handler实例
- 数据路由和分发
- 线程管理
关键数据结构:
# 数据路由表:数据类型 → Handler输入队列
data_sinks = {
ChatDataType.MIC_AUDIO: [
DataSink(owner="SileroVad", sink_queue=vad_queue),
],
ChatDataType.HUMAN_TEXT: [
DataSink(owner="LLM_Bailian", sink_queue=llm_queue),
],
}
# Handler记录:Handler名称 → Handler环境
handlers = {
"SileroVad": HandlerRecord(env=HandlerEnv(...)),
...
}
二、数据运行流程
2.1 完整数据流转架构图
完整的数据流转如下:
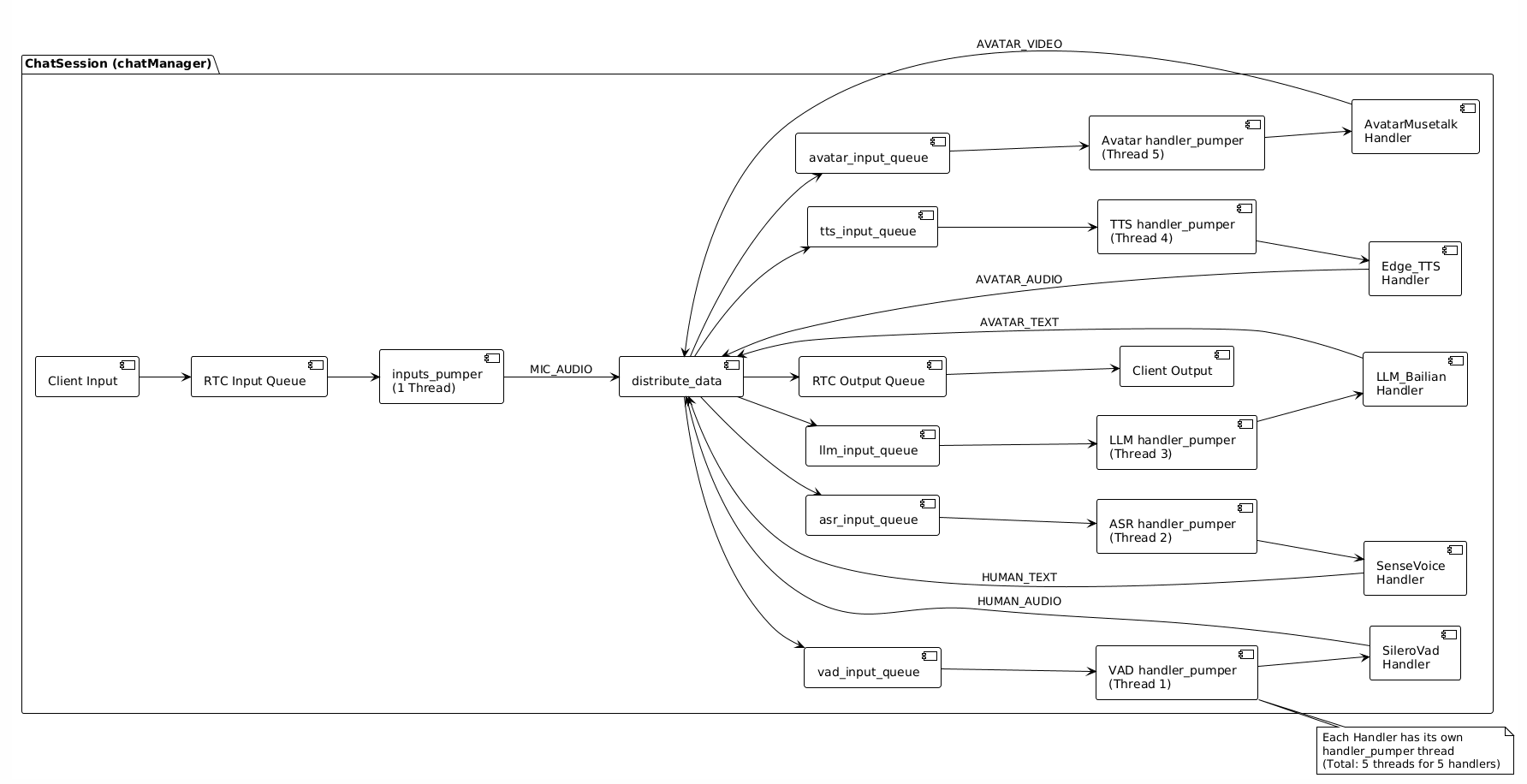
2.2 数据流转详细流程
步骤1:客户端输入
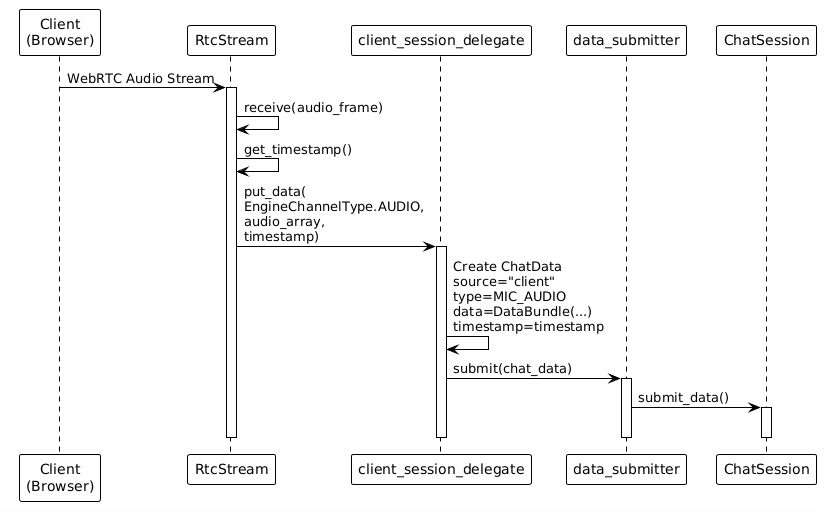
步骤2:数据分发(订阅分发)
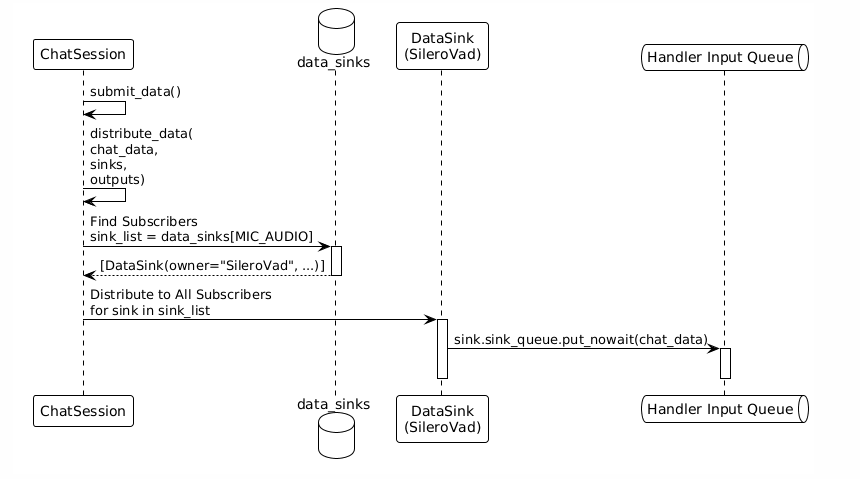
关键机制:
data_sinks是数据类型到Handler输入队列的映射表- 系统根据数据类型自动查找所有订阅者
- 数据同时分发到所有订阅该类型的Handler
步骤3:Handler处理
每个Handler都有独立的处理线程,从自己的输入队列读取数据:
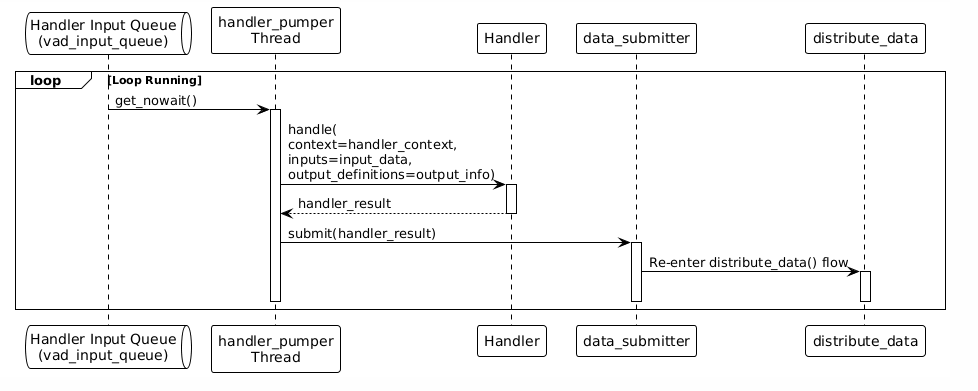
步骤4:数据链式流转
数据按照Handler的输入输出定义,自动形成处理链:
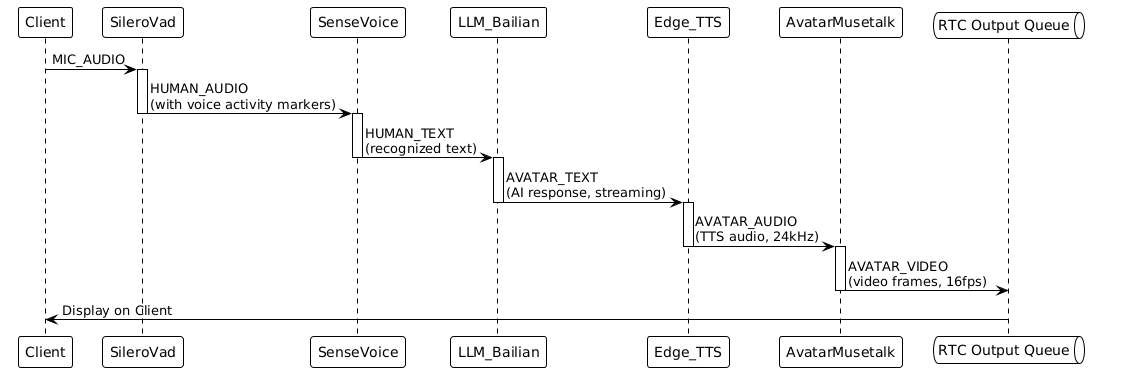
步骤5:客户端输出
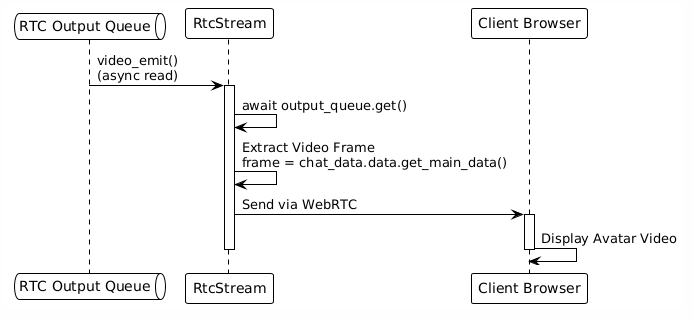
2.3 关键数据结构:队列与路由
输入队列:
# 客户端输入队列(由RTC客户端Handler创建)
input_queues = {
EngineChannelType.AUDIO: asyncio.Queue(),
EngineChannelType.VIDEO: asyncio.Queue(),
EngineChannelType.TEXT: asyncio.Queue(),
}
Handler输入队列:
# 每个Handler有自己的输入队列
vad_input_queue = queue.Queue() # SileroVad的输入队列
asr_input_queue = queue.Queue() # SenseVoice的输入队列
llm_input_queue = queue.Queue() # LLM_Bailian的输入队列
tts_input_queue = queue.Queue() # Edge_TTS的输入队列
avatar_input_queue = queue.Queue() # AvatarMusetalk的输入队列
数据路由表(data_sinks):
# 数据类型 → 订阅该类型的Handler列表
data_sinks = {
ChatDataType.MIC_AUDIO: [
DataSink(owner="SileroVad", sink_queue=vad_input_queue),
],
ChatDataType.HUMAN_AUDIO: [
DataSink(owner="SenseVoice", sink_queue=asr_input_queue),
],
ChatDataType.HUMAN_TEXT: [
DataSink(owner="LLM_Bailian", sink_queue=llm_input_queue),
],
ChatDataType.AVATAR_TEXT: [
DataSink(owner="Edge_TTS", sink_queue=tts_input_queue),
],
ChatDataType.AVATAR_AUDIO: [
DataSink(owner="AvatarMusetalk", sink_queue=avatar_input_queue),
],
}
输出队列映射:
# (Handler名称, 数据类型) → 输出队列
outputs = {
("AvatarMusetalk", ChatDataType.AVATAR_VIDEO): DataSink(
sink_queue=output_queues[EngineChannelType.VIDEO]
),
}
三、Handler的本质
3.1 Handler是什么?
Handler是独立的功能模块,每个Handler负责一个特定的任务:
- RTC客户端Handler:管理WebRTC连接,接收用户输入,发送输出
- SileroVad Handler:语音活动检测(VAD),识别用户是否在说话
- SenseVoice Handler:语音识别(ASR),将语音转换为文本
- LLM Handler:大语言模型,生成回复文本
- TTS Handler:文本转语音,将文本转换为音频
- Avatar Handler:数字人驱动,根据音频生成视频
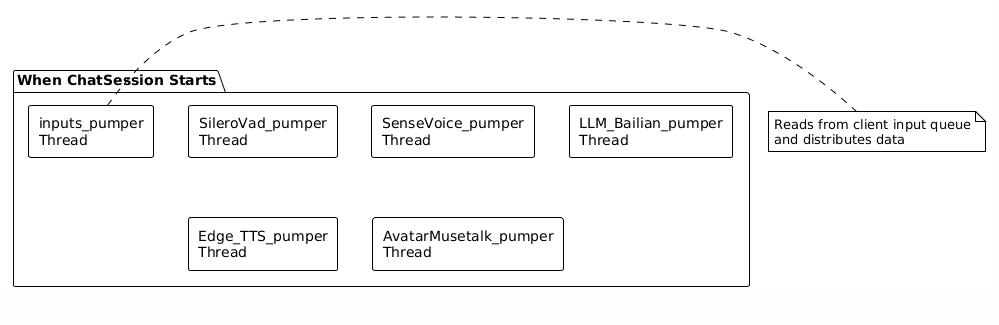
3.2 Handler的实质:独立线程
关键理解:每个Handler在会话启动时,会创建一个独立的线程。
线程运行模式:
# handler_pumper线程的核心循环
def handler_pumper(session_context, handler_env, sinks, outputs):
shared_states = session_context.shared_states
input_queue = handler_env.input_queue # Handler的输入队列
while shared_states.active: # 会话活跃时持续运行
try:
# 1. 从输入队列读取数据
input_data = input_queue.get_nowait()
except queue.Empty:
time.sleep(0.03) # 队列为空时休眠30ms
continue
# 2. 调用Handler处理
handler_result = handler_env.handler.handle(
handler_env.context,
input_data,
handler_env.output_info
)
# 3. 提交处理结果
ChatDataSubmitter.submit(handler_result)
│
└─→ distribute_data() # 分发到下一个Handler
3.3 Handler的生命周期
阶段1:加载(load)
系统启动时,每个Handler执行一次加载:
handler.load(engine_config, handler_config)
作用:
- 加载模型文件
- 初始化全局资源
- 准备Handler运行环境
示例:
- SileroVad:加载VAD模型
- SenseVoice:加载ASR模型
- LLM:初始化API客户端
- Avatar:加载数字人模型
阶段2:创建上下文(create_context)
每个会话创建时,为每个Handler创建独立的上下文:
handler_context = handler.create_context(session_context, handler_config)
作用:
- 创建会话相关的状态
- 例如:LLM创建对话历史,ASR创建音频缓冲区
阶段3:处理(handle)
会话运行期间,Handler持续处理数据:
handler_result = handler.handle(context, inputs, output_definitions)
特点:
- 每个Handler在自己的线程中运行
- 从自己的输入队列读取数据
- 处理完成后输出结果
阶段4:销毁上下文(destroy_context)
会话结束时,清理Handler上下文:
handler.destroy_context(handler_context)
作用:
- 释放会话相关的资源
- 清理状态数据
3.4 Handler的接口定义
所有Handler都继承自HandlerBase,必须实现以下接口:
class HandlerBase(ABC):
@abstractmethod
def load(self, engine_config, handler_config):
"""加载Handler(加载模型等)"""
pass
@abstractmethod
def create_context(self, session_context, handler_config):
"""创建Handler上下文"""
pass
@abstractmethod
def handle(self, context, inputs, output_definitions):
"""处理输入数据"""
pass
@abstractmethod
def get_handler_detail(self, session_context, context):
"""声明输入输出数据类型"""
return HandlerDetail(
inputs={...}, # 输入类型定义
outputs={...} # 输出类型定义
)
@abstractmethod
def destroy_context(self, context):
"""销毁Handler上下文"""
pass
3.5 Handler的关键方法:get_handler_detail
这是Handler与系统交互的关键方法,Handler通过它声明自己的输入输出:
def get_handler_detail(self, session_context, context) -> HandlerDetail:
return HandlerDetail(
inputs={
ChatDataType.MIC_AUDIO: HandlerDataInfo(
type=ChatDataType.MIC_AUDIO,
# 其他配置...
)
},
outputs={
ChatDataType.HUMAN_AUDIO: HandlerDataInfo(
type=ChatDataType.HUMAN_AUDIO,
definition=数据定义,
)
}
)
系统如何使用:
- 在
prepare_handler()阶段,系统调用get_handler_detail() - 根据返回的
inputs,系统创建数据路由:for input_type, input_info in io_detail.inputs.items(): sink_list = data_sinks.setdefault(input_type, []) data_sink = DataSink( owner=handler_name, sink_queue=handler_input_queue ) sink_list.append(data_sink) - 当该类型的数据到达时,系统自动分发到Handler的输入队列
四、Handler协同工作机制
4.1 数据订阅机制
核心思想:Handler通过声明输入类型来"订阅"数据,系统自动建立数据路由。
订阅关系的建立
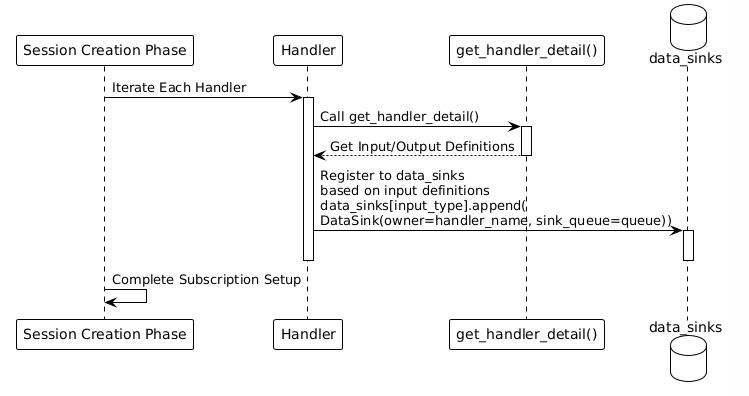
订阅关系示例
以glut3.yaml配置为例:
# SileroVad订阅MIC_AUDIO
data_sinks[ChatDataType.MIC_AUDIO] = [
DataSink(owner="SileroVad", sink_queue=vad_queue),
]
# SenseVoice订阅HUMAN_AUDIO(SileroVad的输出)
data_sinks[ChatDataType.HUMAN_AUDIO] = [
DataSink(owner="SenseVoice", sink_queue=asr_queue),
]
# LLM_Bailian订阅HUMAN_TEXT(SenseVoice的输出)
data_sinks[ChatDataType.HUMAN_TEXT] = [
DataSink(owner="LLM_Bailian", sink_queue=llm_queue),
]
# Edge_TTS订阅AVATAR_TEXT(LLM的输出)
data_sinks[ChatDataType.AVATAR_TEXT] = [
DataSink(owner="Edge_TTS", sink_queue=tts_queue),
]
# AvatarMusetalk订阅AVATAR_AUDIO(TTS的输出)
data_sinks[ChatDataType.AVATAR_AUDIO] = [
DataSink(owner="AvatarMusetalk", sink_queue=avatar_queue),
]
4.2 数据分发机制(订阅分发)
当数据到达时,系统通过distribute_data()自动分发:
def distribute_data(data: ChatData, sinks, outputs):
# 1. 检查是否是最终输出(直接发送到客户端)
source_key = (data.source, data.type)
if source_key in outputs:
outputs[source_key].sink_queue.put_nowait(data)
# 2. 查找所有订阅该数据类型的Handler
sink_list = sinks.get(data.type, [])
# 3. 分发到所有订阅者
for sink in sink_list:
if sink.owner == data.source:
continue # 跳过数据源自身
sink.sink_queue.put_nowait(data) # 放入Handler的输入队列
关键点:
- 数据根据类型自动路由
- 一个数据可以同时分发给多个订阅者
- Handler之间完全解耦,不知道彼此的存在
4.3 Handler并行处理机制
并行运行
所有Handler线程同时运行,互不阻塞:
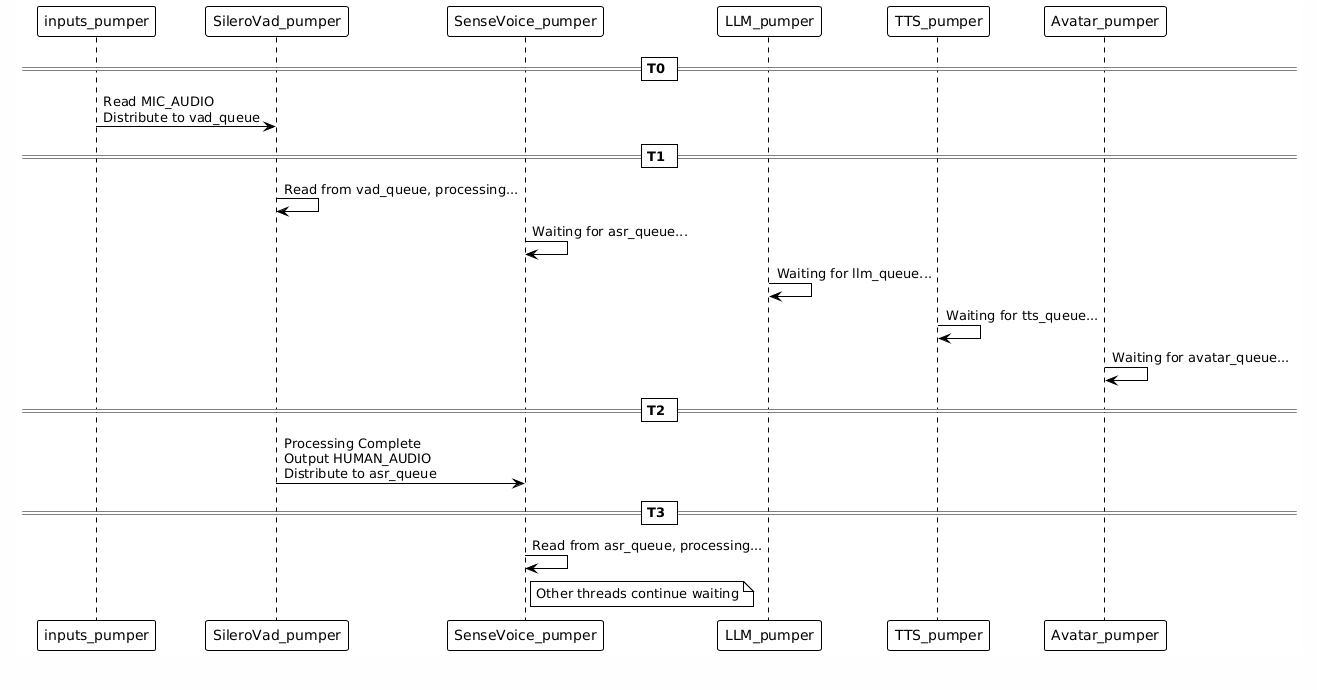
数据流顺序保证
虽然Handler并行运行,但数据流是顺序的:
MIC_AUDIO → HUMAN_AUDIO → HUMAN_TEXT → AVATAR_TEXT → AVATAR_AUDIO → AVATAR_VIDEO
为什么顺序能保证:
-
数据类型驱动:
- SileroVad输出
HUMAN_AUDIO - SenseVoice订阅
HUMAN_AUDIO(不是MIC_AUDIO) - 只有当
HUMAN_AUDIO数据产生时,SenseVoice才会收到
- SileroVad输出
-
队列缓冲:
- 每个Handler有独立的输入队列
- 队列自动缓冲数据,保证顺序
-
VAD的语音结束标记:
- VAD在处理过程中会输出
human_speech_end标记 - ASR等待这个标记后才进行推理
- 确保完整的语音段被处理
- VAD在处理过程中会输出
4.4 Handler之间的解耦
完全解耦
Handler之间不直接通信,只通过数据类型交互:
❌ 错误方式(紧耦合):
SileroVad → 直接调用 → SenseVoice.handle()
✅ 正确方式(解耦):
SileroVad → 输出HUMAN_AUDIO → 系统分发 → SenseVoice输入队列
解耦的好处
- 易于扩展:添加新Handler只需声明输入输出,无需修改现有Handler
- 灵活组合:通过配置文件灵活组合Handler
- 易于测试:每个Handler可以独立测试
- 易于维护:Handler职责清晰,互不干扰
4.5 会话结束机制
共享标志控制
所有线程共享一个标志:shared_states.active
# 会话运行时
shared_states.active = True
# 所有线程循环检查
while shared_states.active:
# 处理数据
...
# 会话结束时
shared_states.active = False
# 所有线程自动退出循环
结束流程
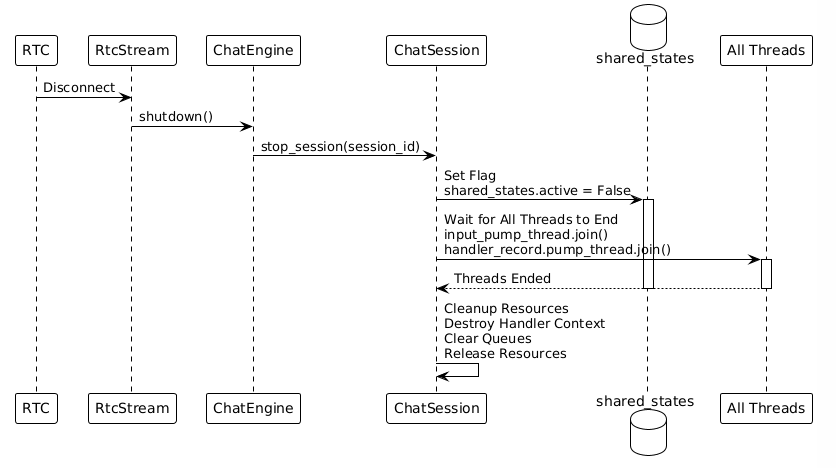
五、Handler详解
5.1 RTC客户端Handler
功能:管理WebRTC连接,负责与客户端的双向通信
输入:客户端音频/视频/文本(通过WebRTC接收)
输出:数字人视频/音频(通过WebRTC发送)
关键代码位置:
src/handlers/client/rtc_client/client_handler_rtc.pysrc/service/rtc_service/rtc_stream.py
工作流程:
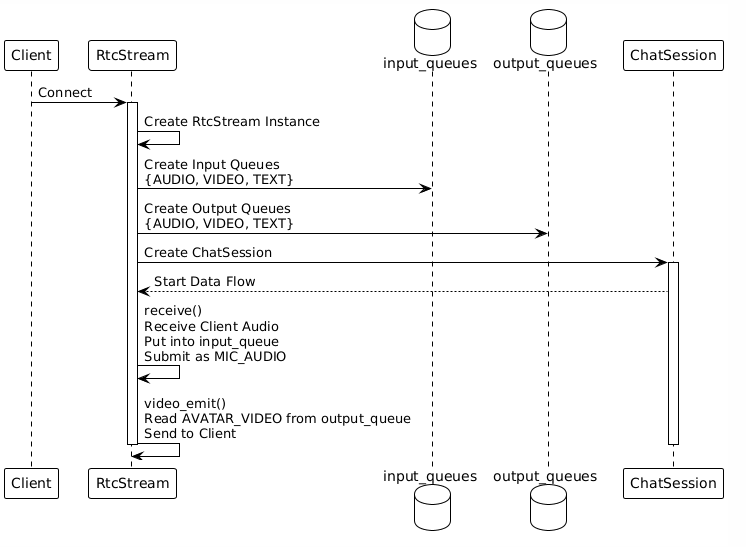
5.2 SileroVad Handler(语音活动检测)
功能:检测用户是否在说话,过滤静音
输入:ChatDataType.MIC_AUDIO(原始音频)
输出:ChatDataType.HUMAN_AUDIO(人声音频,包含语音活动标记)
关键代码位置:src/handlers/vad/silerovad/vad_handler_silero.py
关键方法:
def get_handler_detail(self, ...):
return HandlerDetail(
inputs={
ChatDataType.MIC_AUDIO: HandlerDataInfo(...)
},
outputs={
ChatDataType.HUMAN_AUDIO: HandlerDataInfo(...)
}
)
def handle(self, context, inputs, output_definitions):
# 1. 从输入中提取音频
audio_data = inputs.data.get_main_data()
# 2. VAD模型推理
is_speech = self.model(audio_data)
# 3. 如果检测到语音,输出HUMAN_AUDIO
if is_speech:
yield ChatData(type=HUMAN_AUDIO, data=audio_data)
特点:
- 实时处理,流式输出
- 输出包含
human_speech_start和human_speech_end标记 - ASR依赖这些标记来确定何时进行识别
5.3 SenseVoice Handler(语音识别)
功能:将语音转换为文本
输入:ChatDataType.HUMAN_AUDIO(人声音频)
输出:ChatDataType.HUMAN_TEXT(识别出的文本)
关键代码位置:src/handlers/asr/sensevoice/asr_handler_sensevoice.py
关键方法:
def get_handler_detail(self, ...):
return HandlerDetail(
inputs={
ChatDataType.HUMAN_AUDIO: HandlerDataInfo(...)
},
outputs={
ChatDataType.HUMAN_TEXT: HandlerDataInfo(...)
}
)
def handle(self, context, inputs, output_definitions):
# 1. 累积音频数据
context.audio_buffer.append(inputs.data.get_main_data())
# 2. 检查是否有human_speech_end标记
if inputs.data.has_meta('human_speech_end'):
# 3. 进行ASR推理
text = self.model(context.audio_buffer)
# 4. 输出识别文本
yield ChatData(type=HUMAN_TEXT, data=text)
# 5. 清空缓冲区
context.audio_buffer.clear()
特点:
- 累积音频,等待语音结束标记
- 一次性识别完整语音段
- 输出文本格式:
<|zh|><|NEUTRAL|><|Speech|><|woitn|>你好
5.4 LLM Handler(大语言模型)
功能:理解用户输入,生成回复文本
输入:ChatDataType.HUMAN_TEXT(用户文本)
输出:ChatDataType.AVATAR_TEXT(AI回复文本)
关键代码位置:src/handlers/llm/openai_compatible/llm_handler_openai_compatible.py
关键方法:
def get_handler_detail(self, ...):
return HandlerDetail(
inputs={
ChatDataType.HUMAN_TEXT: HandlerDataInfo(...)
},
outputs={
ChatDataType.AVATAR_TEXT: HandlerDataInfo(...)
}
)
def handle(self, context, inputs, output_definitions):
# 1. 更新对话历史
context.history.add_user_message(inputs.data.get_main_data())
# 2. 调用LLM API(流式)
response = self.client.chat.completions.create(
model=self.model_name,
messages=context.history.get_messages(),
stream=True
)
# 3. 流式输出文本
for chunk in response:
text = chunk.choices[0].delta.content
if text:
yield ChatData(type=AVATAR_TEXT, data=text)
特点:
- 维护对话历史
- 支持流式输出
- 可以配置不同的LLM模型(百炼、OpenAI兼容等)
5.5 Edge_TTS Handler(文本转语音)
功能:将文本转换为语音
输入:ChatDataType.AVATAR_TEXT(AI回复文本)
输出:ChatDataType.AVATAR_AUDIO(生成的音频)
关键代码位置:src/handlers/tts/edgetts/tts_handler_edgetts.py
关键方法:
def get_handler_detail(self, ...):
return HandlerDetail(
inputs={
ChatDataType.AVATAR_TEXT: HandlerDataInfo(...)
},
outputs={
ChatDataType.AVATAR_AUDIO: HandlerDataInfo(...)
}
)
def handle(self, context, inputs, output_definitions):
# 1. 累积文本
context.text_buffer += inputs.data.get_main_data()
# 2. 检查是否有文本结束标记
if inputs.data.has_meta('text_end'):
# 3. 调用TTS API生成音频
audio = edge_tts.generate(
text=context.text_buffer,
voice=self.voice
)
# 4. 输出音频流
for audio_chunk in audio:
yield ChatData(type=AVATAR_AUDIO, data=audio_chunk)
# 5. 清空缓冲区
context.text_buffer = ""
特点:
- 累积文本,等待完整句子
- 支持多种语音(通过配置选择)
- 输出24kHz音频
5.6 AvatarMusetalk Handler(数字人驱动)
功能:根据音频生成数字人视频(唇形同步)
输入:ChatDataType.AVATAR_AUDIO(TTS生成的音频)
输出:ChatDataType.AVATAR_VIDEO(数字人视频帧)
关键代码位置:src/handlers/avatar/musetalk/avatar_handler_musetalk.py
关键方法:
def get_handler_detail(self, ...):
return HandlerDetail(
inputs={
ChatDataType.AVATAR_AUDIO: HandlerDataInfo(...)
},
outputs={
ChatDataType.AVATAR_VIDEO: HandlerDataInfo(...)
}
)
def handle(self, context, inputs, output_definitions):
# 1. 累积音频数据
context.audio_buffer.append(inputs.data.get_main_data())
# 2. 检查是否有音频结束标记
if inputs.data.has_meta('audio_end'):
# 3. MuseTalk模型处理
video_frames = self.model(
audio=context.audio_buffer,
avatar_image=context.avatar_image
)
# 4. 输出视频帧流
for frame in video_frames:
yield ChatData(type=AVATAR_VIDEO, data=frame)
# 5. 清空缓冲区
context.audio_buffer.clear()
特点:
- 精确的唇形同步
- 支持16fps视频输出
- 使用MuseTalk模型进行推理
5.7 Handler处理链总结
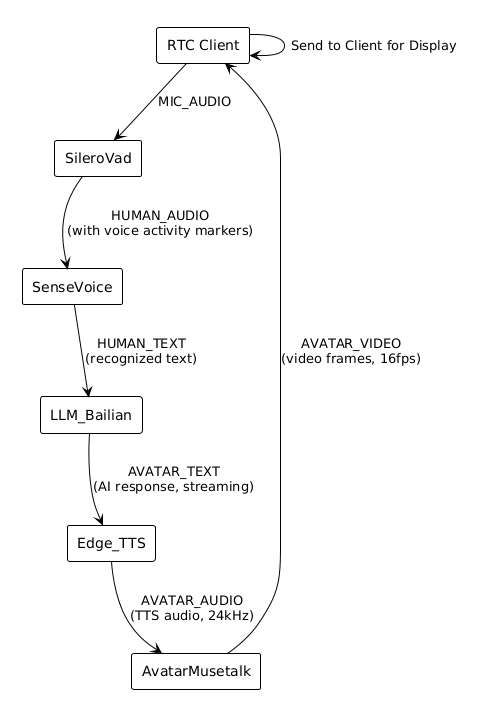
六、快速参考
6.1 关键代码位置
| 功能 | 文件路径 | 关键方法 |
|---|---|---|
| 主入口 | src/glut.py | main() |
| 引擎初始化 | src/chat_engine/chat_engine.py | ChatEngine.initialize() |
| Handler加载 | src/chat_engine/core/handler_manager.py | HandlerManager.initialize() |
| 会话创建 | src/chat_engine/chat_engine.py | ChatEngine.create_client_session() |
| 数据分发 | src/chat_engine/core/chat_session.py | ChatSession.distribute_data() |
| 输入处理 | src/chat_engine/core/chat_session.py | ChatSession.inputs_pumper() |
| Handler处理 | src/chat_engine/core/chat_session.py | ChatSession.handler_pumper() |
6.2 关键数据结构
数据类型(ChatDataType):
MIC_AUDIO # 麦克风音频
HUMAN_AUDIO # 人声音频
HUMAN_TEXT # 用户文本
AVATAR_TEXT # AI回复文本
AVATAR_AUDIO # TTS音频
AVATAR_VIDEO # 数字人视频
数据路由表(data_sinks):
data_sinks: Dict[ChatDataType, List[DataSink]]
# 数据类型 → 订阅该类型的Handler列表
Handler注册表:
handler_registries: Dict[str, HandlerRegistry]
# Handler名称 → Handler注册信息
6.3 核心执行流程
6.4 模块化关键特性
- 配置驱动:通过YAML配置文件定义Handler组合
- 动态加载:运行时根据配置动态导入和实例化Handler
- 数据驱动路由:基于数据类型自动分发,Handler无需知道其他Handler
- 异步处理:每个Handler在独立线程中运行,通过队列通信
- 松耦合:Handler之间不直接依赖,只依赖数据类型
- 易于扩展:添加新Handler只需实现HandlerBase接口
总结
OpenAvatarChat采用分层、模块化的架构设计:
- 顶层(ChatEngine):管理整个系统,支持多会话并发
- 中间层(ChatSession):管理单个会话,协调Handler协同工作
- 底层(Handler):独立的功能模块,通过数据类型进行通信
核心机制:
- 数据订阅:Handler通过声明输入类型订阅数据
- 自动路由:系统根据数据类型自动分发数据
- 并行处理:Handler在独立线程中并行运行
- 队列通信:通过队列实现异步、解耦的通信
这种设计实现了高内聚、低耦合的架构,使得系统易于扩展、维护和测试。
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝
