



















基于 ElevenLabs WebSocket API 实现实时语音对话:完整开发指南
最近在研究实时语音对话的实现,发现 ElevenLabs Agents Platform 提供了非常强大的 WebSocket API。经过一番探索,我完成了一个可以直接在浏览器中运行的实时语音对话 demo。今天就来分享一下这个项目的实现细节和使用体验。
项目链接:https://demo.navtalk.ai/11labs/zh/index.html
一、为什么选择 ElevenLabs?
在开始之前,你可能想知道为什么选择 ElevenLabs 而不是其他方案。我对比了 ElevenLabs 和 OpenAI Realtime API,发现 ElevenLabs 在音色选择、模型灵活性等方面有独特优势。不过这个对比我会在文章后面详细展开。
二、项目概览
这个 demo 基于 ElevenLabs Agents Platform WebSocket API 实现,支持:
- ✅ 完整的 WebSocket 连接管理
- ✅ 实时语音输入输出
- ✅ 文本消息支持
- ✅ 丰富的自定义配置选项
- ✅ 完整的消息处理机制
整个项目可以直接在浏览器中运行,无需后端服务器,非常适合快速原型开发和学习。
三、核心功能特性
3.1 完整的 WebSocket 连接
项目实现了完整的 WebSocket 连接管理,包括:
- 自动获取签名 URL
- 建立安全的 WSS 连接
- 完善的连接状态和错误处理
3.2 实时语音对话
语音处理是核心功能,包括:
- 麦克风音频采集
- 16kHz PCM 音频编码
- 实时音频流传输
- Agent 音频播放
3.3 完整的消息处理
支持 ElevenLabs 提供的所有消息类型:
conversation_initiation_metadata- 会话初始化user_transcript- 用户语音转文字agent_response- Agent 文字回复agent_response_correction- Agent 回复修正audio- Agent 音频响应interruption- 打断检测ping/pong- 心跳检测client_tool_call- 工具调用支持contextual_update- 上下文更新vad_score- 语音活动检测分数
3.4 文本消息支持
除了语音输入,还支持发送文本消息到 Agent,并且有一个很实用的特性:文本消息可以打断 Agent 正在进行的语音回应,这让对话更加自然。
3.5 自定义配置
提供了丰富的配置选项:
- 自定义 Agent Prompt
- 自定义首次消息
- 语言覆盖
- TTS 语音 ID 覆盖
- 动态变量支持
- 自定义 LLM 参数(temperature / max_tokens)
四、详细使用方法
4.1 准备配置
打开文件
使用浏览器打开 https://demo.navtalk.ai/11labs/zh/index.html 即可开始使用。
必需配置项
API Key (xi-api-key):
- ElevenLabs API Key
- 格式:
sk-...或xi-api-key - 获取方式: 登录 ElevenLabs 控制台,创建或查看 API Key
Agent ID:
- ElevenLabs Agent ID
- 格式:
agent_... - 获取方式: 在 ElevenLabs Agents 页面 创建或查看 Agent,复制 Agent ID
可选配置项(按界面顺序)
自定义 Prompt:
- 覆盖 Agent 的默认 prompt
- 留空则使用 Agent 配置中的默认 prompt
- 可用于临时修改 Agent 的行为和对话风格
首次消息:
- Agent 连接后说的第一句话
- 留空则使用 Agent 配置中的默认首次消息
- 例如: "你好,我是你的 AI 助手,有什么可以帮助你的吗?"
语言:
- 覆盖 Agent 的默认语言设置
- 支持的语言代码:
en(英语)、zh(中文)、es(西班牙语)、fr(法语)、de(德语)、ja(日语) 等 - 留空则使用 Agent 配置中的默认语言
TTS 语音:
- 覆盖 Agent 的默认语音设置
- 从下拉菜单中选择不同的语音 ID
- 留空则使用 Agent 配置中的默认语音
- 注意: 需要先填写 API Key 才能加载语音列表
动态变量:
- 用于在对话中动态替换 Prompt 中的变量占位符
- 格式: JSON 对象,例如
{"user_name": "John", "greeting": "Hello"} - 使用场景: 当 Agent 的 Prompt 中包含变量(如
{{user_name}}、{{greeting}})时,可以通过动态变量传入实际值 - 示例:
{ "user_name": "张三", "company": "ABC公司", "product": "智能助手" } - 如果 Agent 的 Prompt 中包含
你好,{{user_name}},欢迎使用{{product}},动态变量会自动替换为你好,张三,欢迎使用智能助手 - 留空则不使用动态变量
LLM Temperature:
- 控制 LLM 生成文本的随机性和创造性
- 取值范围: 0.0 - 2.0
- 值越低,输出越确定和一致(更保守);值越高,输出越随机和创造性(更灵活)
- 推荐值: 0.7 - 1.0(平衡创造性和一致性)
- 留空则使用 Agent 配置中的默认值
LLM Max Tokens:
- 限制 LLM 单次回复的最大 token 数量
- 取值范围: 正整数
- 用于控制回复长度,避免过长的回复
- 留空则使用 Agent 配置中的默认值
2. 开始对话
- 点击 "连接并开始对话" 按钮
- 浏览器会请求麦克风权限,请允许
- 连接成功后会自动开始录音
- 开始说话,Agent 会实时响应
3. 功能操作
- 停止录音: 停止发送音频,但保持连接
- 断开连接: 完全断开 WebSocket 连接
- 文本消息: 在文本输入框中输入消息并发送
API 文档参考
demo 实现基于 ElevenLabs Agents Platform WebSocket API
WebSocket 端点
wss://api.elevenlabs.io/v1/convai/conversation?agent_id={agent_id}
完整通话流程
1. 连接建立阶段
步骤 1: 建立 WebSocket 连接
客户端 → 服务器: 建立 WebSocket 连接
wss://api.elevenlabs.io/v1/convai/conversation?agent_id={agent_id}
步骤 2: 发送初始化数据
- 连接成功后,立即发送
conversation_initiation_client_data消息 - 包含 Agent 配置覆盖(可选)、动态变量(可选)、自定义 LLM 参数(可选)
- 等待服务器返回
conversation_initiation_metadata事件
步骤 3: 接收会话元数据
- 服务器返回
conversation_initiation_metadata事件 - 需要处理的内容:
- 保存
conversation_id(用于后续会话管理) - 记录音频格式信息(
agent_output_audio_format、user_input_audio_format) - 开始音频采集(调用
getUserMedia获取麦克风权限)
- 保存
2. 对话进行阶段
音频输入流程:
用户说话 → 麦克风采集 → 音频处理(降采样到16kHz) → 转换为16-bit PCM → Base64编码 → 发送 user_audio_chunk
服务器响应流程:
服务器接收音频 → 语音识别(ASR)→ 发送 user_transcript → LLM 处理 → 生成回复 → 发送 agent_response → TTS 合成 → 发送 audio 块
关键事件处理顺序:
-
用户说话时:
- 持续发送
user_audio_chunk(每 4096 个采样点发送一次) - 服务器处理音频流,可能返回
vad_score(语音活动检测分数)
- 持续发送
-
服务器识别用户语音:
- 收到
user_transcript事件 - 可以在 UI 中显示用户说的话(用于调试)
- 收到
-
服务器生成回复:
- 收到
agent_response事件 - 可以在 UI 中显示 Agent 的文字回复
- 可能收到
agent_response_correction(如果 Agent 修正了回复)
- 收到
-
服务器发送音频:
- 收到
audio事件(可能多次,流式传输) - 处理方式:
- 将 Base64 音频数据解码
- 加入音频播放队列
- 按顺序播放音频块
- 收到
-
打断处理:
- 如果用户在 Agent 说话时发送新消息,可能收到
interruption事件 - 需要立即停止当前音频播放,清空音频队列
- 如果用户在 Agent 说话时发送新消息,可能收到
3. 心跳保持阶段
心跳机制:
- 服务器定期发送
ping事件 - 需要立即响应
pong消息,包含相同的event_id - 用于保持连接活跃,检测连接状态
4. 工具调用流程(如果启用)
工具调用步骤:
- 服务器发送
client_tool_call事件 - 处理流程:
- 解析工具调用信息(
tool_name、parameters、tool_call_id) - 执行相应的工具/函数
- 发送
client_tool_result返回结果
- 解析工具调用信息(
- 服务器继续处理,可能发送新的
agent_response和audio
5. 上下文更新流程(如果启用)
上下文更新:
- 客户端可以主动发送
contextual_update更新对话上下文 - 服务器也可能发送
contextual_update事件 - 根据业务需求处理上下文更新
6. 文本消息流程
发送文本消息:
- 客户端发送
user_message事件 - 特点:可以打断 Agent 正在进行的音频回应(ElevenLabs 特有功能)
- 处理方式:
- 如果 Agent 正在播放音频,立即停止播放(收到
interruption事件) - 等待服务器处理文本消息并返回新的回复
- 如果 Agent 正在播放音频,立即停止播放(收到
7. 连接关闭阶段
正常关闭:
- 停止发送音频(调用
stopRecording) - 关闭 WebSocket 连接
- 释放音频资源(关闭 AudioContext、停止 MediaStream)
异常处理:
- 监听 WebSocket 的
error和close事件 - 实现重连逻辑(可选)
- 清理所有资源
事件处理详细说明
客户端需要处理的事件
| 事件类型 | 何时收到 | 需要处理 | 可选操作 |
|---|---|---|---|
conversation_initiation_metadata | 连接建立后 | 保存 conversation_id,开始录音 | 显示会话信息 |
user_transcript | 用户说话后 | - | 显示用户说的话 |
agent_response | Agent 生成回复后 | - | 显示 Agent 文字回复 |
agent_response_correction | Agent 修正回复时 | - | 显示修正信息 |
audio | Agent 音频合成后 | 解码并播放音频 | 显示播放状态 |
interruption | 检测到打断时 | 停止播放,清空队列 | 显示打断提示 |
ping | 服务器心跳检测 | 立即发送 pong | - |
client_tool_call | Agent 需要调用工具时 | 执行工具并返回结果 | 显示工具调用信息 |
vad_score | 语音活动检测时 | - | 可视化语音活动 |
客户端发送消息的时机
| 消息类型 | 发送时机 | 频率 |
|---|---|---|
conversation_initiation_client_data | 连接建立后立即发送 | 1次 |
user_audio_chunk | 录音过程中持续发送 | 高频(约每 250ms) |
user_message | 用户输入文本时 | 按需 |
user_activity | 需要通知用户活动时 | 按需 |
pong | 收到 ping 时立即响应 | 按需 |
client_tool_result | 工具执行完成后 | 按需 |
contextual_update | 需要更新上下文时 | 按需 |
音频格式要求
ElevenLabs 对音频格式有明确要求:
- 采样率: 16kHz
- 声道: 单声道 (mono)
- 编码: 16-bit PCM
- 格式: Base64 编码的二进制数据
技术实现
音频处理流程
- 采集: 使用
getUserMediaAPI 获取麦克风音频流 - 处理: 使用
AudioContext和ScriptProcessorNode处理音频 - 降采样: 如果采样率不是 16kHz,自动降采样
- 编码: 将 Float32 音频数据转换为 16-bit PCM
- 编码: Base64 编码后通过 WebSocket 发送
音频播放流程
- 接收: 从 WebSocket 接收 Base64 编码的音频
- 解码: Base64 解码为二进制数据
- 播放: 优先尝试作为 MP3 播放,失败则作为 PCM 播放
ElevenLabs vs OpenAI Realtime API 详细对比
在开发过程中,我也研究了 OpenAI Realtime API,发现两个平台各有特色。下面是我整理的详细对比:
快速对比总览
| 对比项 | ElevenLabs Agents Platform | OpenAI Realtime API |
|---|---|---|
| 多模态支持 | ❌ 不支持,即不支持摄像头识别(图像输入) | ✅ 支持(GPT-4o) |
| 音色选择 | ✅ 100+ 种预设音色,支持语音克隆 | ⚠️ 10 种预设音色 |
| LLM 模型 | ✅ 多模型支持(ElevenLabs、OpenAI、Google、Anthropic) | ✅ GPT-4o、GPT-4o-mini |
| 知识库 | ✅ 支持 | ✅ 支持(通过 Assistants API) |
| Function Call | ✅ 支持 | ✅ 支持 |
| 文本打断 AI 回应 | ✅ 支持(发送文本消息可打断 AI 正在进行的回应) | ❌ 不支持 |
| 延迟 | ✅ 取决于模型(163ms-3.87s) | ✅ 低(300-800ms) |
| 价格 | 💰 按分钟计费(根据模型,0.0033-0.1956/分钟) | 💰 按 token 计费(GPT-4o-mini 更经济) |
详细对比信息请查看下方各功能点的详细说明。
各重点详细对比
1. 多模态支持(摄像头识别)
| 平台 | 支持情况 | 详细信息 | 参考链接 |
|---|---|---|---|
| ElevenLabs Agents Platform | ❌ 目前不支持 | 专注于语音对话,暂不支持视觉输入(摄像头/图像识别) | ElevenLabs Agents Platform WebSocket API 文档 |
| OpenAI Realtime API | ✅ 支持(通过 GPT-4o) | 支持视觉输入,可处理图像和视频帧,支持摄像头实时识别。GPT-4o 模型原生支持多模态输入 | OpenAI Realtime API 文档 OpenAI GPT-4o 视觉能力 |
说明:OpenAI Realtime API 基于 GPT-4o 模型,支持多模态输入,可以处理图像和视频内容。ElevenLabs 目前专注于语音对话场景,暂不支持视觉输入。
参考来源:
- ElevenLabs: 官方 WebSocket API 文档 - 未提及视觉输入支持
- OpenAI: Realtime API 官方文档 - 支持 GPT-4o 多模态能力
2. 音色选择性和对比
| 平台 | 音色数量 | 音色特点 | 自定义能力 | 参考链接 |
|---|---|---|---|---|
| ElevenLabs Agents Platform | ✅ 100+ 种预设音色 | 高质量、多语言、支持情感表达、语音克隆 | 支持自定义语音 ID、情感控制、语气调整、语音克隆 | ElevenLabs 语音库 ElevenLabs 语音克隆 |
| OpenAI Realtime API | ⚠️ 有限选择(10种音色) | 主要依赖 TTS API,提供 10 种预设音色(alloy, echo, fable, onyx, nova, shimmer...) | 音色控制能力有限,不支持语音克隆 | OpenAI TTS 文档 OpenAI TTS 音色列表 |
详细对比:
- ElevenLabs:提供超过 100 种预设音色,涵盖多种语言、年龄、性别和风格。支持语音克隆(Voice Cloning),可以从少量样本创建自定义音色。支持情感和语气控制,可调整音色的表达方式。音色质量高,适合专业应用。
- OpenAI:TTS API 提供 10 种预设音色(alloy, echo, fable, onyx, nova, shimmer...),选择相对有限。不支持语音克隆,音色控制能力较弱。
参考来源:
- ElevenLabs: 官方语音库 - 展示大量预设音色
- ElevenLabs: 语音克隆文档 - 支持自定义语音克隆
- OpenAI: TTS API 文档 - 列出 10 种可用音色
3. 支持的 LLM 模型
| 平台 | 支持的模型 | 模型特点 | 参考链接 |
|---|---|---|---|
| ElevenLabs Agents Platform | ✅ 多模型支持 | 支持 ElevenLabs 自有模型及多个第三方模型(OpenAI、Google、Anthropic 等),用户可根据需求选择,支持自定义 LLM 参数 | ElevenLabs Agents 文档 ElevenLabs LLM 配置 |
| OpenAI Realtime API | ✅ GPT-4o, GPT-4o-mini | 支持 GPT-4o(多模态、更强能力)和 GPT-4o-mini(轻量级、更快速、成本更低),可切换模型 | OpenAI Realtime API 模型 OpenAI 模型对比 |
ElevenLabs Agents Platform 支持的模型列表:
ElevenLabs 自有模型:
- GLM-4.5-Air: 适合 agentic use cases,延迟 ~631ms,成本 ~$0.0600/分钟
- Qwen3-30B-A3B: 超低延迟,延迟 ~163ms,成本 ~$0.0168/分钟
- GPT-OSS-120B: 实验性模型(OpenAI 开源模型),延迟 ~314ms,成本 ~$0.0126/分钟
其他提供商模型(在 ElevenLabs 平台上可用):
OpenAI 模型:
- GPT-5 系列:GPT-5(延迟 ~1.14s,成本 ~0.0826/分钟)、GPT-5.1、GPT-5 Mini(延迟 ~855ms,成本 ~0.0165/分钟)、GPT-5 Nano(延迟 ~788ms,成本 ~$0.0033/分钟)
- GPT-4.1 系列:GPT-4.1(延迟 ~803ms,成本 ~0.1298/分钟)、GPT-4.1 Mini、GPT-4.1 Nano(延迟 ~478ms,成本 ~0.0065/分钟)
- GPT-4o(延迟 ~771ms,成本 ~0.1623/分钟)、GPT-4o Mini(延迟 ~738ms,成本 ~0.0097/分钟)
- GPT-4 Turbo(延迟 ~1.28s,成本 ~0.6461/分钟)、GPT-3.5 Turbo(延迟 ~494ms,成本 ~0.0323/分钟)
Google 模型:
- Gemini 3 Pro Preview(延迟 ~3.87s,成本 ~$0.1310/分钟)
- Gemini 2.5 Flash(延迟 ~752ms,成本 ~0.0097/分钟)、Gemini 2.5 Flash Lite(延迟 ~505ms,成本 ~0.0065/分钟)
- Gemini 2.0 Flash(延迟 ~564ms,成本 ~0.0065/分钟)、Gemini 2.0 Flash Lite(延迟 ~547ms,成本 ~0.0049/分钟)
Anthropic 模型:
- Claude Sonnet 4.5(延迟 ~1.5s,成本 ~0.1956/分钟)、Claude Sonnet 4(延迟 ~1.31s,成本 ~0.1956/分钟)
- Claude Haiku 4.5(延迟 ~703ms,成本 ~$0.0652/分钟)
- Claude 3.7 Sonnet(延迟 ~1.12s,成本 ~0.1956/分钟)、Claude 3.5 Sonnet(延迟 ~1.14s,成本 ~0.1956/分钟)
- Claude 3 Haiku(延迟 ~608ms,成本 ~$0.0163/分钟)
自定义模型:
- 支持添加自定义 LLM
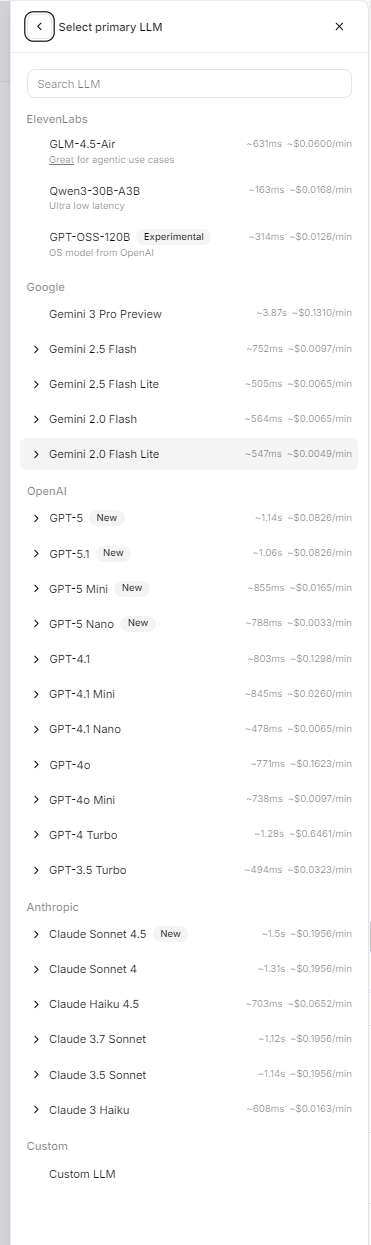
上图展示了 ElevenLabs Agents Platform 中可选择的 LLM 模型列表,包括延迟和价格信息
详细说明:
- ElevenLabs:提供丰富的模型选择,包括自有模型和多个第三方提供商的模型。用户可以根据延迟、成本和功能需求选择最适合的模型。支持通过
custom_llm_extra_body自定义 LLM 参数(如 temperature、max_tokens)。 - OpenAI:明确支持 GPT-4o(支持多模态、更强推理能力)和 GPT-4o-mini(更快速、成本更低),用户可以根据需求选择。两个模型都支持实时对话。
参考来源:
- ElevenLabs: Agents Platform 文档 - 模型选择界面
- ElevenLabs: WebSocket API - 自定义 LLM 参数
- OpenAI: Realtime API 文档 - 支持 GPT-4o 和 GPT-4o-mini
- OpenAI: 模型对比文档 - 详细模型信息
4. 知识库支持
| 平台 | 知识库支持 | 实现方式 | 参考链接 |
|---|---|---|---|
| ElevenLabs Agents Platform | ✅ 支持 | 通过 Agent 配置支持知识库集成,可上传文档和设置知识库,Agent 可在对话中引用知识库内容 | ElevenLabs Agents 文档 ElevenLabs Agent 配置 |
| OpenAI Realtime API | ✅ 支持(通过 Assistants API 或 Function Calling) | 可通过 Assistants API 集成知识库(文件上传、向量存储),或通过 function calling 访问外部数据源和 API | OpenAI Assistants API OpenAI Function Calling |
详细说明:
- ElevenLabs:在 Agent 配置中支持知识库功能,可以上传文档供 Agent 参考。知识库内容会在对话中被自动引用。
- OpenAI:通过 Assistants API 可以创建带知识库的助手(支持文件上传和向量存储),或通过 function calling 访问外部数据源和 API,实现更灵活的知识检索。
参考来源:
- ElevenLabs: Agents Platform 文档 - 提及知识库支持
- ElevenLabs: Agent 配置文档 - 知识库配置说明
- OpenAI: Assistants API 文档 - 知识库和文件上传功能
- OpenAI: Function Calling 文档 - 外部数据访问
5. Function Call 支持
| 平台 | 支持情况 | 实现方式 | 参考链接 |
|---|---|---|---|
| ElevenLabs Agents Platform | ✅ 支持 | 通过 client_tool_call 和 client_tool_result 消息类型实现工具调用,支持在 Agent 中定义工具 | ElevenLabs WebSocket API - 工具调用 ElevenLabs Agent 工具配置 |
| OpenAI Realtime API | ✅ 支持 | 通过 tool_calls 和 tool_results 事件实现 function calling,支持在会话中定义工具 | OpenAI Realtime API - Function Calling OpenAI Function Calling 指南 |
详细对比:
- ElevenLabs:使用
client_tool_call事件请求客户端执行工具,通过client_tool_result返回结果。工具在 Agent 配置中定义。 - OpenAI:使用标准的 function calling 机制,通过
tool_calls事件触发,通过tool_results返回结果。支持在会话中动态定义工具。
参考来源:
- ElevenLabs: WebSocket API - client_tool_call - 工具调用实现
- ElevenLabs: Agent 配置 - 工具定义
- OpenAI: Realtime API Function Calling - 实时 API 工具调用
- OpenAI: Function Calling 指南 - 详细实现说明
6. 文本打断 AI 回应
| 平台 | 支持情况 | 详细信息 | 参考链接 |
|---|---|---|---|
| ElevenLabs Agents Platform | ✅ 支持 | 发送文本消息(user_message)可以打断 AI 正在进行的语音回应,实现更自然的对话交互 | ElevenLabs WebSocket API - 用户消息 |
| OpenAI Realtime API | ❌ 不支持 | 发送文本消息无法打断 AI 正在进行的回应,需要等待当前回应完成 | OpenAI Realtime API 文档 |
详细对比:
- ElevenLabs:支持通过发送文本消息打断 AI 正在进行的回应。当用户在 AI 说话时发送文本消息,AI 会立即停止当前回应并处理新的文本输入,这使得对话更加自然和流畅,类似于真人对话中的打断行为。
- OpenAI:不支持文本消息打断功能。如果 AI 正在回应,用户发送的文本消息需要等待当前回应完成后才会被处理,这可能会影响对话的流畅性和实时性。
使用场景:
- ElevenLabs:适合需要快速交互和打断的场景,如实时客服、快速问答等
- OpenAI:适合需要完整回应的场景,但交互可能不够灵活
7. 延迟对比
| 平台 | 延迟表现 | 优化特点 | 参考链接 |
|---|---|---|---|
| ElevenLabs Agents Platform | ✅ 取决于模型选择 | 延迟范围从 163ms 到 3.87s,取决于选择的 LLM 模型。低延迟模型如 Qwen3-30B-A3B(~163ms)适合实时交互,高性能模型如 GPT-5(~1.14s)或 Claude Sonnet(~1.5s)延迟较高但能力更强。支持流式响应 | ElevenLabs Agents Platform 文档 ElevenLabs WebSocket API |
| OpenAI Realtime API | ✅ 低延迟 | 实时流式响应,延迟通常在 300-800ms(取决于模型和网络),GPT-4o-mini 通常更快 | OpenAI Realtime API 文档 OpenAI 性能优化 |
详细说明:
- ElevenLabs:延迟取决于选择的 LLM 模型。如果选择低延迟模型(如 Qwen3-30B-A3B ~163ms、GPT-3.5 Turbo ~494ms),延迟可以很低,适合实时交互。如果选择高性能模型(如 GPT-5 ~1.14s、Claude Sonnet ~1.5s),延迟会更高但推理能力更强。支持流式音频响应,减少首字节延迟。
- OpenAI:延迟相对稳定,GPT-4o-mini 通常比 GPT-4o 响应更快。支持流式响应优化。
实际延迟会受以下因素影响:
- 网络条件和地理位置
- 模型选择(ElevenLabs 平台上有多种模型可选,OpenAI 主要是 GPT-4o vs GPT-4o-mini)
- 请求复杂度
- 服务器负载
以上数据为典型值,实际表现可能因使用场景而异。
参考来源:
- ElevenLabs: Agents Platform 文档 - 强调低延迟优化
- OpenAI: Realtime API 文档 - 实时性能说明
- OpenAI: 延迟优化指南 - 性能优化建议
8. 价格对比
| 平台 | 计费方式 | 价格详情 | 参考链接 |
|---|---|---|---|
| ElevenLabs Agents Platform | 💰 按对话分钟数计费(根据选择的模型) | 价格取决于选择的 LLM 模型,通常包含语音合成、语音识别和 LLM 调用的综合费用。具体模型价格请参考上面的"支持的 LLM 模型"部分 | ElevenLabs 定价页面 ElevenLabs 计费说明 |
| OpenAI Realtime API | 💰 按 token 和音频时长计费 | GPT-4o: 输入 2.50/1M tokens,输出 10/1M tokens GPT-4o-mini: 输入 0.15/1M tokens,输出 0.60/1M tokens 音频输入/输出:$0.015/分钟 (价格可能随时间变化) | OpenAI 定价页面 OpenAI Realtime API 定价 |
详细对比:
- ElevenLabs:采用按对话分钟数计费的模式,价格取决于选择的 LLM 模型。通常包含语音合成、语音识别和 LLM 调用的综合费用,计费方式简单明了。具体模型价格请参考上面的"支持的 LLM 模型"部分。
- OpenAI:采用按 token 计费的模式,不同模型价格差异较大:
- GPT-4o-mini:更经济,适合高频使用场景
- GPT-4o:功能更强但价格更高,适合需要多模态或更强推理能力的场景
- 音频处理按分钟额外计费
成本估算示例(仅供参考):
- 短对话场景(5分钟,约1000 tokens):OpenAI GPT-4o-mini 约 0.0015 + 0.075 = $0.0765
- 长对话场景(30分钟,约5000 tokens):OpenAI GPT-4o-mini 约 0.0075 + 0.45 = $0.4575
建议:根据实际使用场景和预算选择合适的平台:
- 如果主要使用语音对话且使用量大,ElevenLabs 的按分钟计费可能更简单,可根据需求选择不同模型以平衡成本和性能
- 如果需要多模态能力或更强的 LLM 能力,OpenAI 可能更合适
- 对于高频使用,GPT-4o-mini 通常更经济
参考来源:
- ElevenLabs: 官方定价页面 - 最新价格信息
- ElevenLabs: Agents Platform 文档 - 计费说明
- OpenAI: 官方定价页面 - 最新价格信息(2024-2025)
- OpenAI: Realtime API 文档 - 计费详情
总结
ElevenLabs Agents Platform WebSocket API 为实时语音对话提供了强大的支持。通过这个 demo,我实现了完整的实时语音对话功能,包括音频采集、处理、传输和播放。
相比 OpenAI Realtime API,ElevenLabs 在音色选择、模型灵活性等方面有明显优势,特别适合需要特定音色或语音克隆的场景。不过,如果需要多模态能力,OpenAI 可能是更好的选择。
如果你也想尝试实现实时语音对话,这个 demo 应该能给你提供一个不错的起点。项目代码已经开源,你可以直接使用或在此基础上进行扩展。
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝
