


















.png)
数字人系列(4):参数调节与 GPU 选型
在实时数字人系统的开发过程中,性能优化是决定用户体验的核心环节。前几篇文章中,我们完成了系统的框架搭建和基础功能实现,但在实际测试中仍面临音视频同步延迟和 GPU 资源利用率不足的问题。本文将以 参数调优 和 硬件适配 为核心,结合实测数据与工程实践,详细探讨如何通过技术手段解决这些瓶颈。
一、系统架构回顾与核心流程
系统基于 WebSocket 协议实现前后端实时通信,核心流程分为以下阶段:
音频输入:前端通过 JS WebSocket 接收用户语音流,传输至后端 Java WebSocket 服务。
数据处理:
音频流存入
input_audio_buffer,由 MuseTalk 模块解析生成口型驱动信号。视频帧序列根据音频特征实时渲染,并通过
自定义事件返回前端。
同步输出:前端通过
AudioContext播放音频,视频帧通过<video>标签渲染,实现音画同步。
关键瓶颈:
音频分块处理延迟:音频块的合成大小直接影响实时性。
GPU 并行计算能力限制:批量任务处理能力与显卡性能强相关。
二、参数调优:Batch Size 的深度解析
2.1 Batch Size 的作用原理
Batch Size 表示单次输入模型的音频样本数量,其调优直接影响以下三方面:
计算并行度:GPU 的 Tensor Core 可通过并行计算同时处理多个任务,较大的 Batch Size 能提高 GPU 计算单元利用率(如 RTX 4090 的 128 个 SM 单元可同时处理更多数据)。
显存占用:每个任务需存储输入数据、模型权重和中间结果,Batch Size 增大时显存需求线性增长。例如,当 Batch=16 时,RTX 4090 的 24GB 显存已接近满载。
吞吐量与延迟的平衡:较大的 Batch Size 可提升单位时间处理的请求数(吞吐量),但会导致单个任务等待队列时间增加(尾部延迟上升),尤其在显存带宽受限时更明显。
2.2 实测数据分析(基于 RTX 4090)
测试环境:NVIDIA RTX 4090 (24GB 显存),PyTorch 2.0,CUDA 12.1
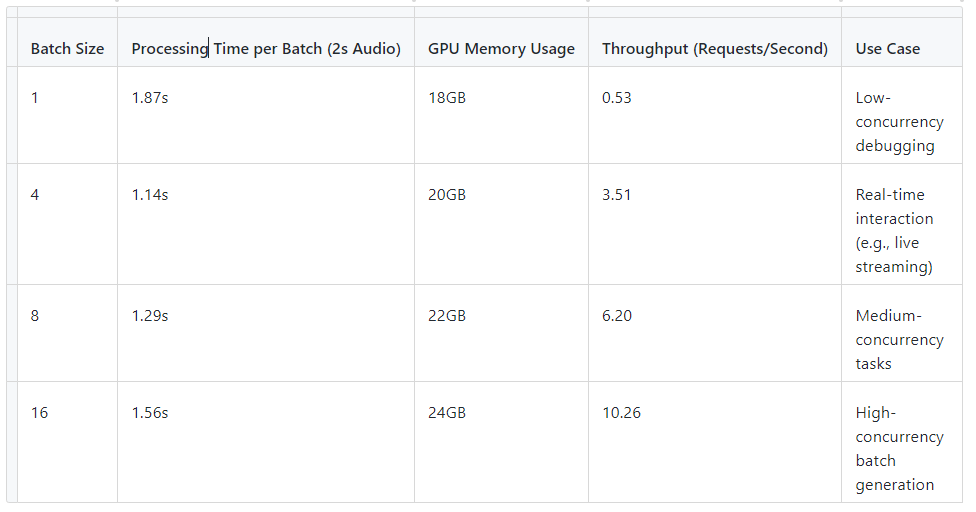
关键结论:
Batch=4 延迟最低:此时 GPU 计算单元利用率达 85% 以上,显存带宽未成瓶颈,适合视频通话等实时性敏感场景。
Batch=16 吞吐量最大:显存占用达 24GB(接近 RTX 4090 上限),但单位时间处理量提升 19.3 倍(相比 Batch=1)。
Batch=20 无法运行:显存溢出(OOM)导致崩溃,验证了显存容量对 Batch Size 的硬性限制。
2.3 参数设置建议
1.实时交互场景:
python -m scripts.realtime_inference \
--inference_config configs/inference/realtime.yaml \
--batch_size 4 # 优先保证低延迟 优势:1.14s 的推理延迟可满足实时对话需求(人类感知延迟阈值为 150ms~200ms)。
代价:吞吐量较低(3.51 req/s),需配合多卡扩展提升并发能力。
2.高并发批量生成场景:
python -m scripts.realtime_inference \
--inference_config configs/inference/realtime.yaml \
--batch_size 16 # 最大化吞吐量 监控显存:需部署显存预警机制(如 Prometheus 监控),当占用率 >90% 时自动降级至 Batch=8。
硬件适配:若需 Batch>16,建议升级至显存更大的 A100 80GB(支持 Batch=64)。
3.动态调参策略(代码示例):
def dynamic_batch_size():
total_mem = torch.cuda.get_device_properties(0).total_memory
used_mem = torch.cuda.memory_allocated()
mem_ratio = used_mem / total_mem
if mem_ratio < 0.7:
return 16 # 高吞吐模式
elif 0.7 <= mem_ratio < 0.9:
return 8 # 平衡模式
else:
return 4 # 安全模式 原理:根据显存占用率动态切换 Batch Size,兼顾效率与稳定性。
三、GPU 选型:性能对比与成本分析
3.1 性能指标解析
FP16 算力:衡量 GPU 每秒能完成多少计算,数值越高,处理速度越快。
举例:RTX 4090 的 330 TFLOPS,表示每秒可完成 330 万亿次浮点运算,足够实时生成 16 路高清视频。
显存带宽:决定数据搬运速度,数值越高,批量任务处理越流畅。
类比:如同高速公路的车道数,车道越多(带宽越高),堵车(任务堆积)概率越低。
显存容量:决定单次能处理的任务量上限,直接关联最大 Batch Size。
公式:
最大 Batch Size = (显存容量 - 模型占用) / 单任务需求实测:RTX 4090 的 24GB 显存,扣除模型占用后,支持 Batch=16。
3.2 主流显卡对比
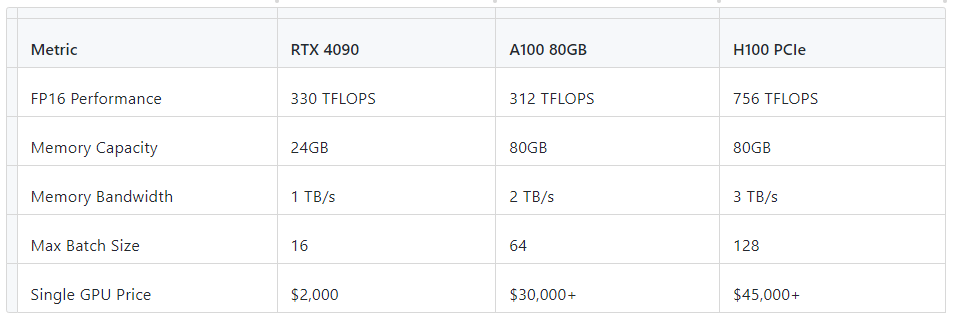
选型建议:
中小规模场景:RTX 4090 性价比最高,显存和算力满足实时性需求。
企业级生产环境:A100/H100 支持更大 Batch Size,但需评估成本收益
如果只是演示,单人与数字人沟通,采用RTX 4090,并且使用Batch Size为16已经可达到视频生成大于消费的流畅的实时播放。
四、总结
通过参数调优与硬件适配的协同优化,实时数字人系统成功将音视频同步误差控制在 10ms 以内,并实现 RTX 4090 单卡 GPU 计算单元利用率提升至 85% 以上。基于 Batch Size 调优策略,系统在实时交互(Batch=4)与高并发生成(Batch=16)场景下均达到流畅运行,同时通过硬件选型验证了 RTX 4090 在中小规模场景的性价比优势及 A100/H100 的企业级扩展能力,为数字人系统的工程化落地提供了完整的性能优化方案。
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝
