


















.png)
DeepSeek本地部署指南:从模型选择到数据投喂,打造专属AI知识库
一、选择合适的DeepSeek版本
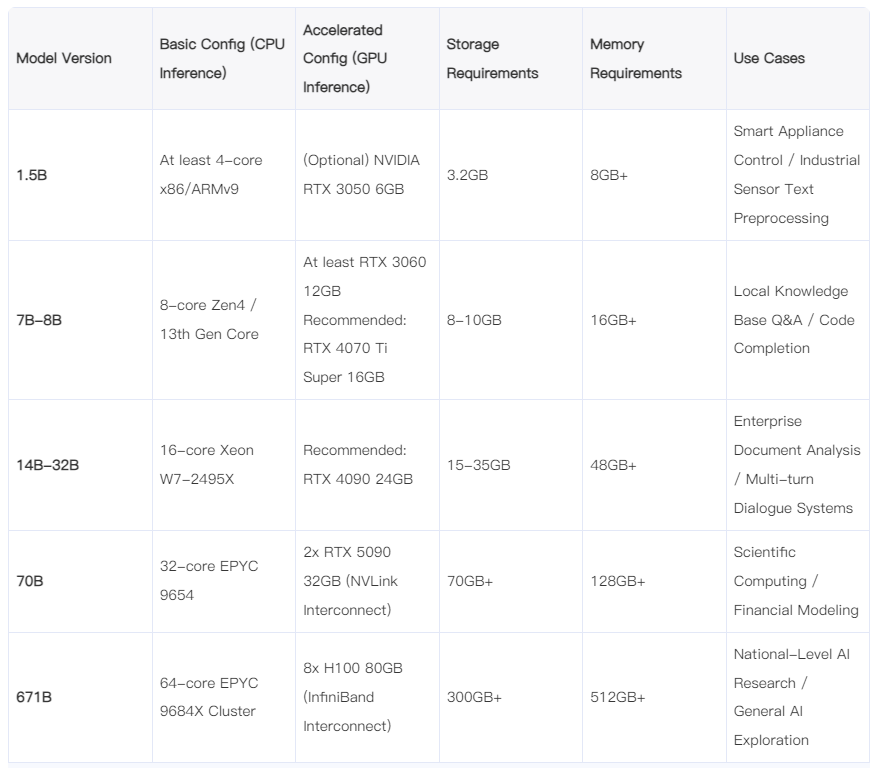
| 模型版本 | 基础配置(CPU推理) | 加速配置(GPU推理) | 存储需求 | 内存要求 | 适用场景 |
|---|---|---|---|---|---|
| 1.5B | 至少4核x86/ARMv9 | (非必需)NVIDIA RTX 3050 6GB | 3.2GB | 8GB+ | 智能家电控制/工业传感器文本预处理 |
| 7B-8B | 8核Zen4/13代酷睿 | 至少RTX 3060 12GB 推荐:RTX 4070 Ti Super 16GB |
8-10GB | 16GB+ | 本地知识库问答/代码补全 |
| 14B-32B | 16核至强W7-2495X | 推荐:RTX 4090 24GB | 15-35GB | 48GB+ | 企业级文档分析/多轮对话系统 |
| 70B | 32核EPYC 9654 | 2x RTX 5090 32GB(NVLink互联) | 70GB+ | 128GB+ | 科研计算/金融建模 |
| 671B | 64核EPYC 9684X集群 | 8x H100 80GB(InfiniBand互联) | 300GB+ | 512GB+ | 国家级AI研究/通用人工智能探索 |
根据电脑配置,选择合适的DeepSeek版本,这里我选择的是32B版本,这里我的电脑配置: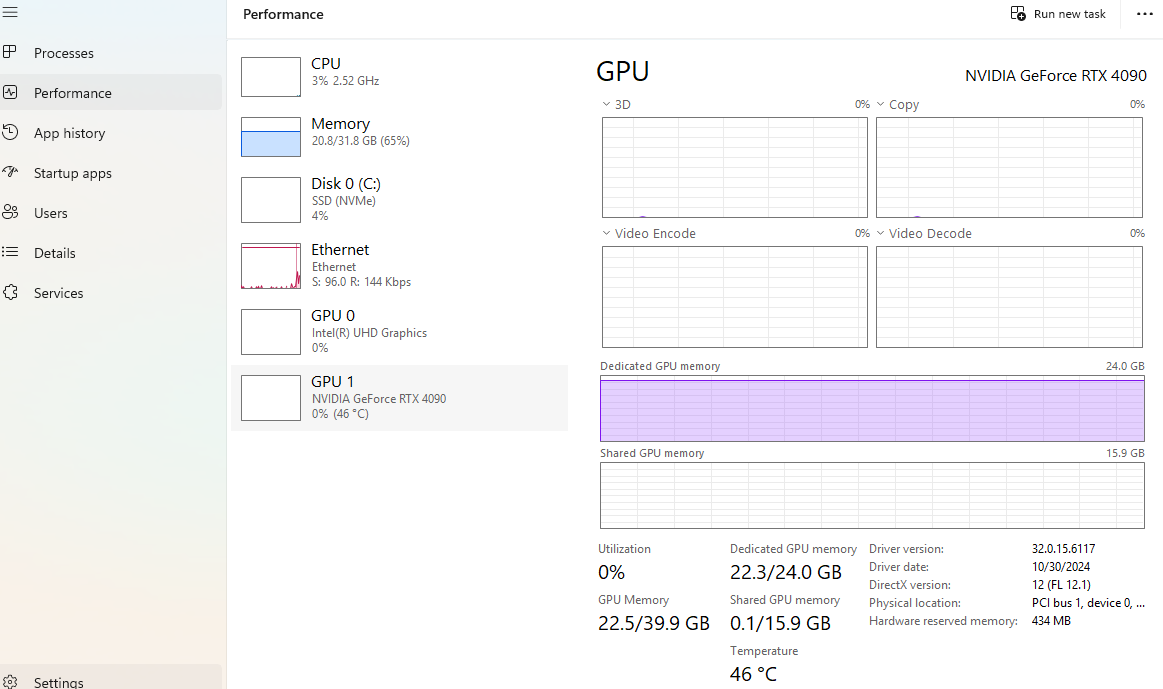
二、DeepSeek本地部署
1、安装Ollama
Ollama是一款功能强大的本地化大模型管理工具,能够帮助用户轻松部署和运行DeepSeek模型。
首先我们需要安装Ollama,它可以在本地运行和管理大模型。到Ollama官网 https://ollama.com,点击下载,然后选择适合自己系统的版本,这里选择Windows:

安装完成后,打开命令行界面并输入
ollama
如果屏幕上出现以下提示信息,那么恭喜你,Ollama 已经成功安装。

2、部署 DeepSeek R1 模型
首先,访问 Ollama 官网并点击页面顶部的「模型」(Models)选项,接着在列表中找到并点击「DeepSeek R1」:

在模型详情页面,根据我们计算机的显存容量选择合适的模型版本(详情参考第一章):

例如,电脑运行的是 Windows系统,拥有 4GB 的显存,因此我选择了1.5b 版本的模型。点击 1.5b 版本,页面右侧将显示下载指令:
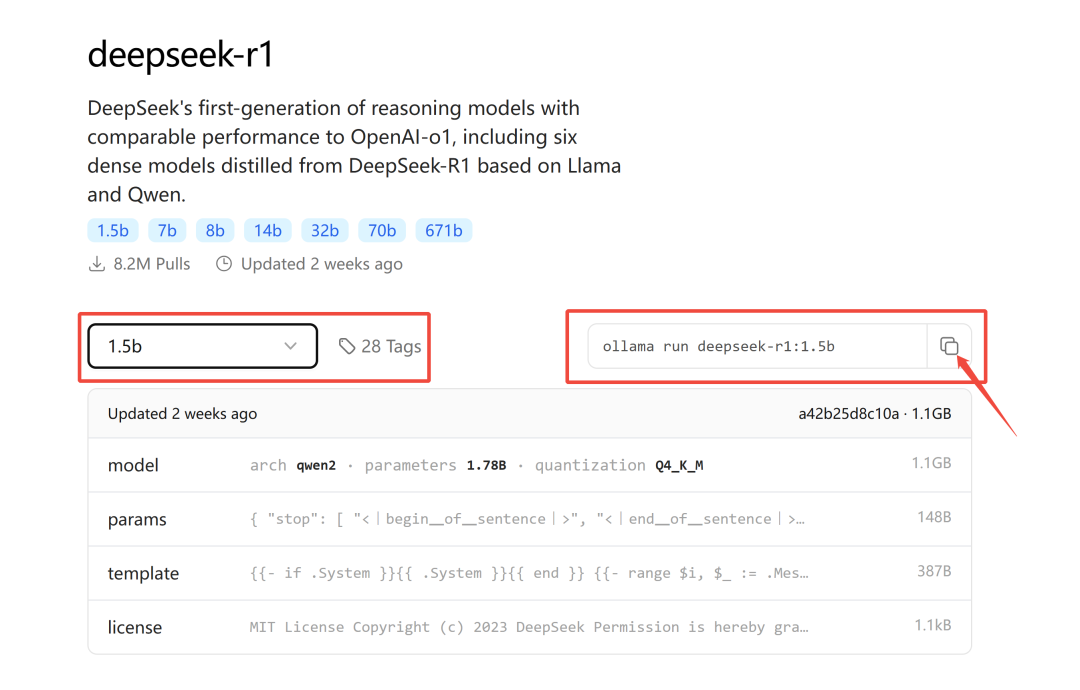
将此下载命令复制并粘贴到命令行中执行开始下载:
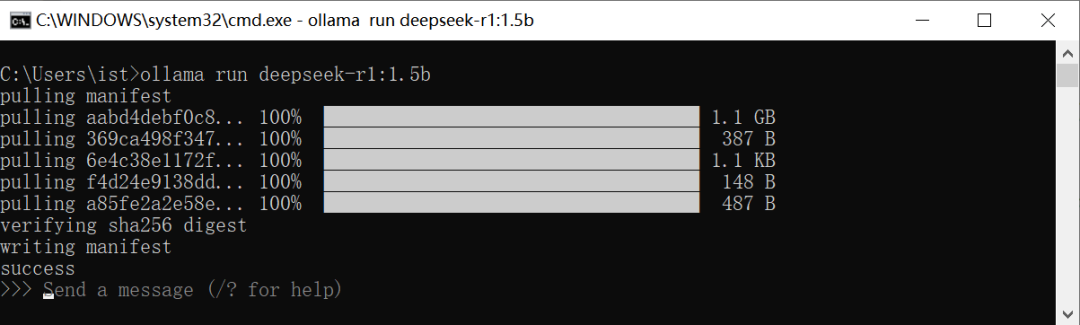
待命令执行完毕,就可以通过命令行与DeepSeek大模型进行交互了:

但是在命令行窗口下对话,还是太抽象,我们需要一个美观的图文交互界面。
3、通过ollama端口 API 访问原始模型
请求url:
http://localhost:11434/api/chat
{
"model": "deepseek-r1:1.5b",
"messages": [
{
"role": "system",
"content": "你是一个能够理解中文指令并帮助完成任务的智能助手。你的任务是根据用户的需求生成合适的分类任务或生成任务,并准确判断这些任务的类型。请确保你的回答简洁、准确且符合中英文语境。"
},
{
"role": "user",
"content": "写一个简单的 Python 函数,用于计算两个数的和"
}
],
"stream": false
}

三、WebUI可视化
WebUI可视化选择直接在浏览器安装Page Assist插件的方式来实现。
Page Assist是本地 AI 模型的 Web UI,可以使用本地运行的 AI 模型来辅助进行网络浏览,利用本地运行的AI模型,在浏览网页时进行交互,或者作为本地AI模型提供者(如Ollama、Chrome AI等)的网页界面。
仓库地址:https://github.com/n4ze3m/page-assist
当前功能:
各类任务的侧边栏
支持视觉模型
本地AI模型的简约网页界面
网络搜索功能
在侧边栏与PDF进行对话
与文档对话(支持pdf、csv、txt、md、docx格式)
要把DeepSeek可视化,首先在扩展中的管理扩展页面,搜索找到Page Assist

然后点击获取Page Assist

获取完成后,就可以在扩展中看到PageAssist插件,点击对应的插件就可以直接使用。

进入插件后,选择我们上面下载好的deepseek模型,然后就可以跟DeepSeek进行可视化对话了,如果需要获取最新的数据,需要打开下方的联网开关。

到这里,DeepSeek的WebUI可视化就完成了。
四、数据投喂训练AI
1、自定义AI知识库
nomic-embed-text是一款高效的嵌入式模型,专为数据投喂任务设计
实现数据投喂训练AI,需要下载nomic-embed-text和安装AnythingLLM。
下载nomic-embed-text:
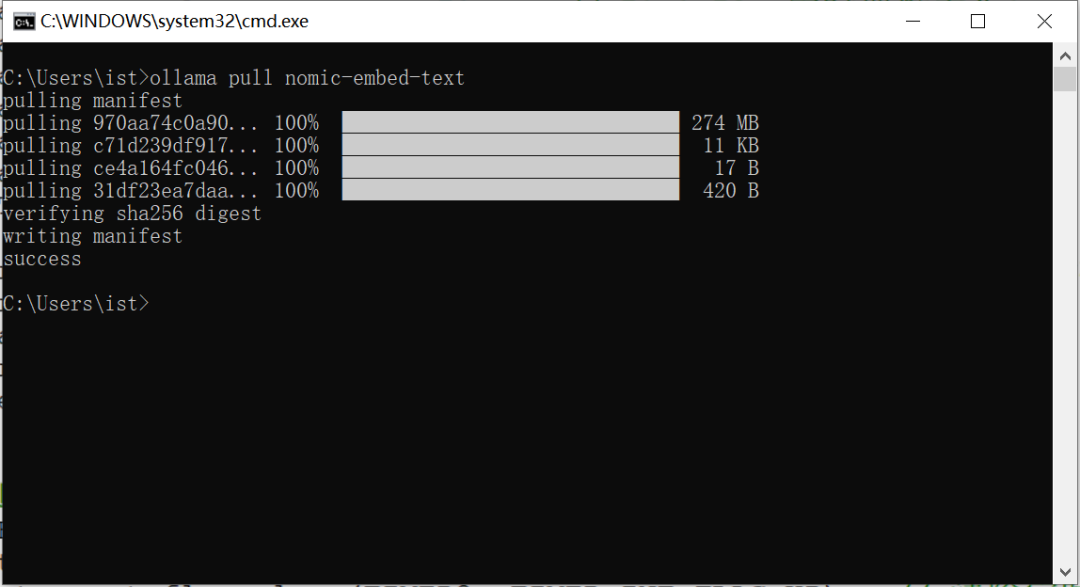
在终端输入 ollama pull nomic-embed-text 回车下载nomic-embed-text嵌入式模型(后面做数据投喂会用到)。
安装AnythingLLM:
进入官网 https://anythingllm.com/,选择对应系统版本的安装包进行下载


选择【所有用户】点击下一步。

修改路径地址中的首字符C可更改安装位置,本例安装到F盘,点击下一步。

点击完成。

软件打开后,点击【Get started】。

点击箭头,进行下一步。

输入工作区名称,点击下一步箭头。

点击【设置】,里面可以设置模型、界面显示语言等。

若软件显示英文,可在Customization外观定制里面选择Chinese即可。

AnythingLLM设置
在软件设置里面,LLM首选项界面,提供商选择Ollama,Ollama Model选择你前面下载的DeepSeek-R1系列模型1.5b~671b,然后点击Save changes。

在Embedder首选项界面,嵌入引擎提供商选择Ollama,Ollama Embedding Mode选择【nomic-embed-text】,然后点击保存更改。

①点击【工作区设置】,②点击聊天设置,③工作区LLM提供者选择【Ollama】,④工作区聊天模型选择【deepseek-r1】模型,⑤然后点击【Update workspace agent】。

代理配置界面,工作区代理LLM提供商选择【Ollama】,工作区代理模型选择【deepseek-r1】,然后点击【Update workspace agent】。

最后就是数据投喂训练AI:
在工作区界面,点击【上传】。

❶点击upload选择需要上传的文件(支持PDF、Txt、Word、Excel、PPT等常见文档格式)。❷勾选上传的文件,❸点击【Move to Workspace】。

点击【Save and Embed】。

没有投喂数据之前,输入正点原子公司名称是什么?AI是回答不了的,投喂后能够准确回答出来。

到这里数据投喂训练AI就完成啦,有需求的完全可以自己搭建一个智能知识库出来。
2、通过AnythingLLM端口 API 访问经训练的AI
注意:默认访问端口是关闭的,需要手动打开

请求url:
http://localhost:3001/api/v1/workspace/test/chat
这里的
test就是我们之前创建的工作区,不同工作区投喂的数据互不影响。意思就是,你新建一个工作区,将无法回答test工作区中已经投喂的相关数据的内容。
{
"message": "高垚淼是谁",
"mode": "chat",
"sessionId": "identifier-to-partition-chats-by-external-id",
"attachments": [
{
"name": "image.png",
"mime": "image/png",
"contentString": "data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAA..."
}
]
}额外的这里还需要在AnythingLLM上创建api key,在请求头上填写

请求,我们将看到如下返回:

其中各参数含义如下:
| 参数 | 类型 | 必填 | 描述 |
|---|---|---|---|
| message | string | 是 | 用户发送的消息内容,即需要模型处理的任务或问题。 |
| mode | string | 是 |
定义对话模式,可选值为 query 或 chat:- query:仅从向量数据库中检索相关信息,不依赖 LLM 的通用知识。- chat:结合 LLM 的通用知识和向量数据库中的信息生成回答。
|
| sessionId | string | 否 | 用于分区聊天会话的唯一标识符,便于跟踪和管理特定用户的对话历史。 |
| attachments | array | 否 | 附件列表,支持上传文件或图片作为上下文信息。 |
同时,点击这里能看到其他所有的API请求接口,可以进一步了解:
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝
