



















笔记
一、按照CPU和GPU分类,执行任务拆分
1.1 CPU 执行步骤
| 步骤 | 代码位置 | 是否耗时 | 耗时原因 |
|---|---|---|---|
| FFmpeg 检查 | fast_check_ffmpeg() → subprocess.run(["ffmpeg", "-version"], ...)(约第 70 行) | 不耗时 | 仅检查一次,开销小 |
| 视频拆帧保存 | video2imgs() → cv2.VideoCapture(...) cv2.imwrite(...)(约第 90–110 行) | 耗时 | 视频解码+逐帧 PNG 写盘,I/O 占主导 |
| 人脸检测/裁剪 | prepare_material() → coord_list, frame_list = get_landmark_and_bbox(...) cv2.resize(...)(约第 300–330 行) | 耗时 | 地标检测在 CPU 上,逐帧 resize 计算多 |
| 面部解析/蒙版生成 | prepare_material() → mask, crop_box = get_image_prepare_material(...) cv2.imwrite(...)(约第 360–380 行) | 耗时 | 分割/解析 CPU 计算 + 蒙版写盘 I/O |
| 保存中间数据 | prepare_material() → pickle.dump(...) torch.save(...)(约第 390–400 行) | 不耗时 | 文件序列化/写入,单次操作,相对快 |
| 音频特征提取 (librosa) | inference() → whisper_input_features, librosa_length = audio_processor.get_audio_feature(...)(约第 500 行) | 耗时 | 高质量重采样/梅尔谱提取全在 CPU,日志“提取音频特征耗时” |
| 批数据生成/入队 | inference() → gen = datagen(...) res_frame_queue.put(res_frame)(约第 580、640 行) | 不耗时 | Python 生成器/队列同步,轻微,非主要耗时 |
| 帧合成与保存 | process_frames() → cv2.resize(...) combine_frame = get_image_blending(...) cv2.imwrite(...tmp/%08d.png)(约第 440–470 行) | 耗时 | 每帧 resize+混合 |
| 图像序列转视频 | inference() → os.system(ffmpeg ... -f image2 -i tmp/%08d.png ...)(约第 700 行) | 耗时 | FFmpeg CPU H.264 编码,受分辨率/帧数影响大 |
| 音频重采样并写 WAV | save_audio_to_wav() → librosa.resample(...) audio_segment.export(...)(约第 720–740 行) | 耗时 | 重采样 (soxr_hq) 计算 + 磁盘写音频 |
| 音视频合成 | inference() → os.system(" ".join(cmd_combine_audio))(约第 750 行) | 耗时 | FFmpeg 混流 + AAC 编码,全在 CPU |
| 清理临时文件 | os.remove(...), shutil.rmtree(...)(约第 760–770 行) | 不耗时 | 删除文件操作,耗时极小 |
1.2 GPU 执行步骤
| 步骤 | 代码位置 | 是否耗时 | 耗时原因 |
|---|---|---|---|
| 模型迁移到 GPU(half) |
pe = pe.half().to(device)vae.vae = vae.vae.half().to(device)unet.model = unet.model.half().to(device)
(约第 30–40 行)
|
不耗时(一次性初始化) | 仅权重加载到显存 + half 精度转换,初始化时一次开销,不在推理循环内 |
| VAE 编码头像素材 |
prepare_material() → latents = vae.get_latents_for_unet(resized_crop_frame)
(约第 340 行)
|
耗时 | 每帧执行卷积前向,素材帧数多时累计显著 |
| Whisper 前向(切块/编码) |
inference() → whisper_chunks = audio_processor.get_whisper_chunk(..., whisper, ...)
(约第 520 行)
|
耗时 | Transformer 前向计算,随音频时长/切片数线性增长,你有日志“提取音频 chunk 耗时” |
| 条件特征编码 (pe) |
inference() → audio_feature_batch = pe(whisper_batch.to(device))
(约第 610 行)
|
耗时 | 小网络逐批前向,日志“音频特征提取耗时” |
| latent 搬运到 GPU |
inference() → latent_batch = latent_batch.to(device=device, dtype=unet.model.dtype)
(约第 615 行)
|
耗时 | Host→Device 内存传输,大批量时 PCIe 成瓶颈,日志“潜在向量传输到设备耗时” |
| UNet 前向采样(核心生成) |
inference() → pred_latents = unet.model(...).sample
(约第 620 行)
|
耗时 | 最重的卷积/注意力计算,推理主要耗时,日志“推理生成潜在变量耗时” |
| VAE 解码 latent→图像 |
inference() → recon = vae.decode_latents(pred_latents)
(约第 625 行)
|
耗时 | 反卷积/上采样批量执行,日志“潜在变量解码耗时” |
二、按照代码执行顺序拆分
| 流程阶段(按你代码顺序) | 主要代码位置 | 主要跑在谁 | 为什么 | 对整体速度影响 |
|---|---|---|---|---|
| 模型加载 & 半精度上卡 | pe.half().to(device)、vae.vae.half().to(device)、unet.model.half().to(device) |
GPU(搬运+显存) | 一次性把权重拷到 GPU、转 FP16 | 仅初始化,一般不决定整体快慢 |
| 人脸检测/裁剪/掩膜/写图 | get_landmark_and_bbox、get_image_prepare_material、cv2.resize/imwrite、video2imgs |
CPU | OpenCV 编解码、图像 IO、掩膜计算是 CPU 侧 | 在素材多/逐帧落盘时会显著;对 AMD/Intel 差异敏感(向量化/线程) |
| 音频特征提取(重采样+Mel) | audio_processor.get_audio_feature(...),以及后面的 librosa.resample(..., res_type='soxr_hq')(两处) |
CPU(默认) | librosa 的 soxr 高质量重采样 & numpy 计算在 CPU 侧;很吃单核/向量化/BLAS |
高影响:音频长/频繁调用时,容易把 GPU“饿住” (PyTorch Docs, Python-SoXR) |
| Whisper 切块/编码 | audio_processor.get_whisper_chunk(..., whisper, ...)(Whisper 模型已 .to(device, dtype=weight_dtype)) |
GPU(模型前向)+ 少量 CPU(拼接/切片) | Transformer 前向在 GPU;但切块/张量拼接仍在 CPU | 中-高:看音频时长与 batch 设定 |
| 条件特征编码(pe) | audio_feature_batch = pe(whisper_batch.to(device)) |
GPU(小模型)+ CPU→GPU 传输 | 前向在 GPU;.to(device) 的 H2D 传输易成为等待点 |
中等(H2D 若未用 pinned+non_blocking,会拖慢) (PyTorch Docs, PyTorch Forums) |
| UNet 采样(核心生成) | unet.model(...).sample |
GPU | 大卷积/注意力算子全部在 GPU | 最高:常见主耗时 |
| VAE 解码 | vae.decode_latents(pred_latents) |
GPU | 上采样/反卷积在 GPU | 中-高:分辨率/批量越大越吃 |
| 帧融合 & 出视频 | get_image_blending(...)、cv2.imwrite、ffmpeg ... -vcodec libx264 & 音视频合成 |
CPU(OpenCV/PNG/x264)或 GPU(若改 NVENC) | x264 是典型 CPU 负载、强依赖 AVX/线程;NVENC 可把视频编码交给 GPU | 高:长视频或逐帧 PNG → 再编码时尤其明显;对 Intel/AMD 的 SIMD 路径很敏感 (Phoronix) |
GPU 负责 Whisper/pe/UNet/VAE 的前向与解码;CPU 负责「音频重采样/特征预处理」「OpenCV/PNG/FFmpeg」以及所有 CPU↔GPU 的数据搬运。只要 CPU 侧这些环节慢,GPU 就会空等——这会放大“AMD vs Intel”的差距(同一张 3090 也跑不满)。
三、CPU 性能对比 & RTX 3090 算力数据
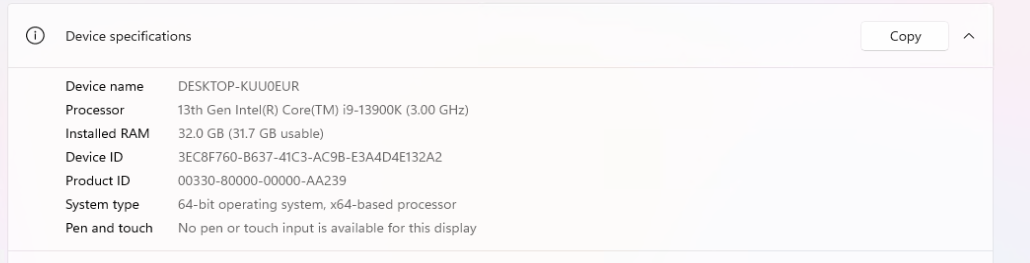
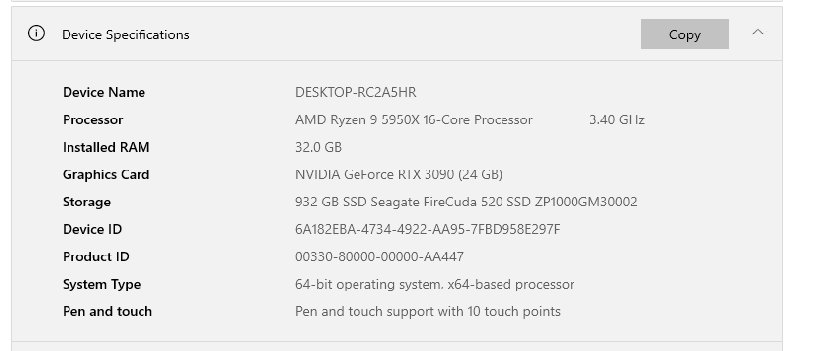
(a)Intel Core i9-13900K vs AMD Ryzen 9 5950X
根据 Technical.City 的聚合基准评价,i9‑13900K 比 Ryzen 9 5950X 整体性能高约 28.9%。维基百科+8技术城+8CPU Monkey+8
Geekbench 5 单核:i9‑13900K 得分 2986 vs 5950X 得分 2211,快约 +35%。多核更是领先。技术城
更强的性能也分布在多项现实使用场景,例如 Cinebench R23 多核 i9 达到 39,652 vs 5950X 的 28,577(+39%)。
综上,i9‑13900K 在单核和多核性能上都明显优于 5950X,性能提升可视为 30–40% 区间,这与你在 MuseTalk 中 AMD 慢 30–40% 的观察相吻合。
(b)RTX 3090 算力(FP32 / FP16)
官方论坛数据显示 RTX 3090 的 FP32 峰值性能为 35.58 TFLOPS。维基百科+3NVIDIA Developer Forums+3维基百科+3
另一处维基也给出类似数字:RTX 3090 FP32 约 35.58 TFLOPS。itcreations.com+6维基百科+6NVIDIA Developer Forums+6
询问AI得到的总结:

四、论文关于硬件的描述
论文中强调:
MuseTalk 支持在 256×256 分辨率下以 30 FPS 以上速度在线生成视频,并具备“几乎可忽略的启动延迟”
在项目 GitHub README 中强调 MuseTalk 可在 NVIDIA Tesla V100 GPU 上以 30 FPS+ 的速度运行。(这是基于纯推理阶段的耗时,加上预处理、写图、编码等步骤,达不到这个速度。)
没有任何关于CPU 负载、CPU 架构或数据预处理性能的评估或优化。
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝