




基于 MuseTalk + Realtime API 的实时数字人系统:打造低延迟、高互动的未来交互体验
随着人工智能技术的不断发展,数字人作为新一代虚拟助手和互动媒介,正在迅速进入各行各业。数字人的应用场景包括虚拟客服、在线教育、智能助手、娱乐行业等,涉及文本、语音、图像和视频等多种交互方式。然而,尽管这些系统已经取得了显著进展,如何在实时交互中保证自然流畅的表现仍然是一个亟待解决的问题。
本文将深入探讨基于 MuseTalk 和 OpenAI Realtime API 的创新性实时数字人系统,介绍这一系统如何解决传统技术的不足,并推动数字人技术向更自然、更高效的方向发展。
一、MuseTalk + OpenAI Realtime API 的创新性优势
传统的数字人技术往往存在以下几个关键挑战:
延迟问题:在处理实时语音和视频时,由于系统需要经过多个处理环节(如语音识别、文本生成、音频同步、视频渲染等),系统往往存在较高的延迟,导致互动体验不流畅。
口型同步的难题:虽然有很多技术可以进行面部动画和口型同步,但在实际应用中,音频和口型常常出现不协调的情况,给用户带来不自然的感觉。
交互质量不高:传统的数字人技术大多依赖于预设模型,难以处理复杂的自然语言交互,导致互动时显得机械化、单一化。
而基于 MuseTalk 和 OpenAI Realtime API 的创新性解决方案,能够突破这些瓶颈,提供更自然流畅的实时互动体验。具体优势如下:
更高的实时性与低延迟:采用 MuseTalk 和 OpenAI Realtime API 的组合,能够实时处理音频输入并同步生成高质量的口型动画。
流畅的口型同步与自然表达:MuseTalk 利用潜空间修复技术(Latent Space Inpainting)来生成精确的口型同步动画,消除了传统方法中卡顿和不流畅的口型同步问题。
跨模态的互动能力:OpenAI 的强大自然语言处理能力帮助数字人理解复杂的对话内容,让数字人的表现更加多样化。
更低的成本效益与硬件需求:采用 MuseTalk 和 OpenAI Realtime API 结合的方式,极大降低了对高端硬件的依赖。只需要基本的音频输入和基础的面部动画生成技术,即可实现高质量的实时口型同步和语音输出。
高精度的语音与语境理解:OpenAI Realtime API 基于先进的预训练模型,能够理解复杂的语境和多轮对话。
更强的适应性与灵活性:OpenAI Realtime API 的灵活性使得我们可以快速适配不同的语言、情感表达和场景需求。
支持大规模的实时互动场景:借助 OpenAI Realtime API 的低延迟、高效响应能力,我们的系统可以处理大规模的实时互动。
可扩展性与持续优化:由于MuseTalk 和 OpenAI Realtime API 为我们提供了更强的可扩展性,我们可以迅速加入新的功能(如语音情感分析、个性化对话管理等),并进行持续优化。
二、系统架构与设计
为了实现上述优势,我们设计了一个灵活、高效、低延迟的系统架构,确保音频、视频和自然语言处理的无缝对接。
2.1 系统概览
基于 MuseTalk 和 OpenAI Realtime API 的实时数字人系统设计以高效的音视频同步为核心,支持低延迟的实时交互和自然流畅的面部动画。系统由以下模块构成:
前端数字人交互界面:
提供用户与系统的入口,通过用户点击操作触发音频处理和动画生成。
WebSocket 通信模块:
采用 Java 和 JS 的 WebSocket 连接,处理音频的传输与对话生成,确保流式数据的实时性。
MuseTalk 音视频生成模块:
接收来自 OpenAI Realtime API 的音频数据,将其转化为口型同步的动画视频。
音频与视频文件管理:
系统通过文件夹监控音频输入和视频输出,实时处理和清理音视频文件,避免资源堆积。
2.2 系统架构设计
下图展示了系统的完整架构设计,包括用户交互、数据流和模块功能的详细流程:
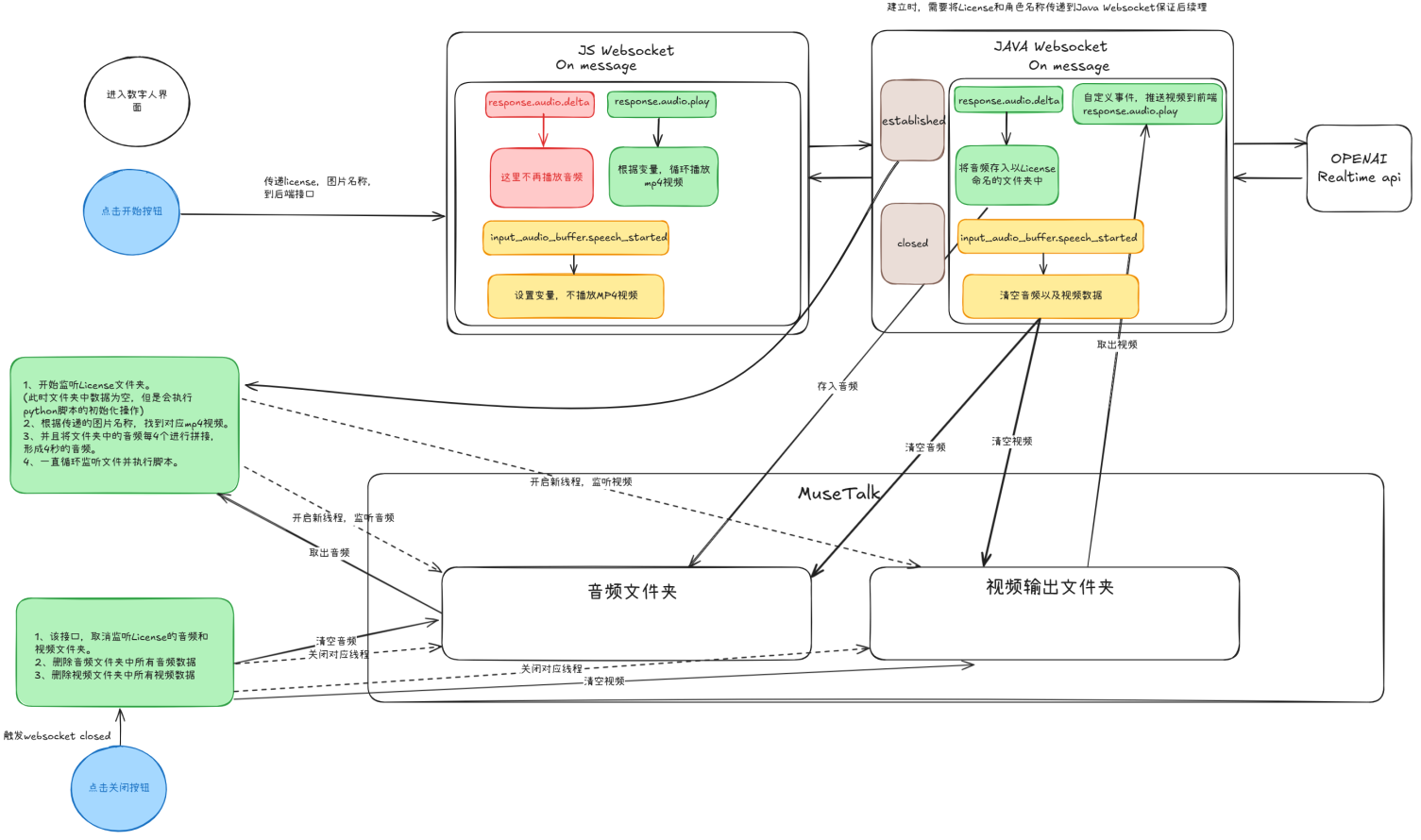
用户启动:
用户通过前端界面点击“开始按钮”,触发音频录制、WebSocket 通信及后端处理逻辑。
系统在启动后会创建必要的音频和视频文件夹,同时初始化 MuseTalk 的处理线程,以及视频结果的读取线程。
前端界面将循环播放静默的数字人MP4视频。
WebSocket 数据通信:
前端与后端分别通过 JS 和 Java WebSocket 实现数据交互。
JS WebSocket 负责监听 OpenAI Realtime API 的返回消息(除音频流即response.audio.delta事件外的其他事件),并根据返回的事件类型处理播放视频流,打断视频播放等。
Java WebSocket 负责处理 OpenAI Realtime API 返回的音频流并存储在指定音频文件夹下。同时将获取到的视频文件夹下的结果,通过视频流的形式返回给前端。
音频与口型同步:
MuseTalk 的处理线程,将一直读取音频文件夹中的内容,将 OpenAI Realtime API 返回的音频数据被传递到 MuseTalk,通过音频驱动面部动画生成口型同步的视频,并删除处理过的音频文件。
视频文件实时存储至文件目录,视频结果的读取线程,将结果以视频流的形式传递到前端界面播放,并删除处理过的视频文件。
用户打断:
当用户在数字人播放视频流图中,打断数字人说话,此时 OpenAI Realtime API 将返回 input_audio_buffer.speech_started 事件,此时将停止视频流的播放,并清空对应的音频以及视频文件夹
用户停止:
用户点击“停止按钮”后,系统终止 WebSocket 连接,清理所有临时文件,同时关闭MuseTalk 的处理线程,以及视频结果的读取线程。
前端界面将再次循环播放静默的数字人MP4视频。
2.3 关键技术点
实时流式处理
OpenAI Realtime API 的使用:支持流式传输音频输入并返回结果;流式数据的处理方式显著降低延迟。
WebSocket 的双向通信:数据格式设计保证音频、视频数据的独立流转;利用事件驱动机制提高交互效率。
MuseTalk 的音视频同步
源码修改:原项目通过命令的方式,能够实现输入一个不张嘴的人物视频+多个音频,输出多个音频与口型同步的视频。需要改写成实时处理音频的形式,但是不可能每次都通过调用命令的方式来运行,毫无疑问,这将增加额外的时间开销。
参数调整:在运行中,需要不断调试相关执行参数。比如调整bbox_shift值以达到最好的音频与口型同步效果。比如处理多少秒的音频(运行时间与处理的需要处理的音频时长成正比),能够使生成出的视频比前端播放的视频速度更快,保持产出速度快于消费速度。
多线程处理
避免线程阻塞:每个任务模块独立运行线程,避免互相阻塞:音频监听线程、视频生成线程、视频播放线程。
文件管理优化
动态文件夹监听:实时监听文件夹的新增内容,自动触发音频处理与视频生成;清理机制确保文件夹中仅存储当前处理的内容。
高效资源管理:避免文件堆积导致磁盘空间不足或处理延迟。
三、初步实现
初步实现只包含大致框架,如果存在部分语法问题,需自行修改。
同时部分内容涉及到开发核心细节,出于保密协议,未全部展示。
3.0 实现前准备
即使使用魔法上网,JVM虚拟机也无法绕过VPN限制,因此后端JAVA将无法与OpenAI Realtime API建立其连接。请确保你拥有一台国外服务器或者使用内网穿透。
按照第一篇文章中的介绍,安装好MuseTalk相关环境,并能够成功运行。
3.1 WebSocket连接建立
3.1.1 JS WebSocket
首先建立其最基本的WebSocket:
const websocketUrl = "ws://localhost:8900/api/realtime-api";
let socket;
async function startWebSocket() {
// Get license information
const license = "license001";
const characterName = "girl2";
const websocketUrlWithParams = `${websocketUrl}?license=${encodeURIComponent(license)}&characterName=${encodeURIComponent(characterName)}`;
// Initialize WebSocket
socket = new WebSocket(websocketUrlWithParams);
socket.binaryType = 'arraybuffer';
// Listen for WebSocket messages
socket.onmessage = (event) => {
if (typeof event.data === 'string') {
try {
const data = JSON.parse(event.data);
handleReceivedMessage(data); // Handle non-binary messages
} catch (e) {
console.error("Failed to parse JSON message:", e);
}
} else if (event.data instanceof ArrayBuffer) {
const arrayBuffer = event.data;
handleReceivedBinaryMessage(arrayBuffer); // Handle binary messages
} else {
console.warn("Unknown type of WebSocket message");
}
};
socket.onopen = function () {
console.log("WebSocket is connected");
};
socket.onerror = function (error) {
console.error("WebSocket error: ", error);
};
socket.onclose = async function (event) {
// Show message if points are insufficient
if (event.reason === 'Insufficient points') {
showErrorTip("You need more points to complete this action.");
}
console.log("WebSocket is closed", event.code, event.reason);
};
}
其次,我们需要处理Realtiem API返回的各种事件,常用的事件如下:
// Handle different WebSocket messages based on event type
async function handleReceivedMessage(data) {
switch (data.type) {
// Create session and send configuration
case "session.created":
console.log("Session created, sending session update.");
await sendSessionUpdate(); // Call the function to send session update
break;
// Session updated, ready to receive audio
case "session.updated":
console.log("Session updated. Ready to receive audio.");
startRecording(); // Start recording after session update
break;
// User starts speaking
case "input_audio_buffer.speech_started":
console.log("Speech started detected by server.");
stopCurrentAudioPlayback(); // Stop current audio playback
audioQueue = []; // Clear the current audio queue
isPlaying = false; // Reset the play status
playVideo = false; // Stop video playback
break;
// User stops speaking
case "input_audio_buffer.speech_stopped":
console.log("Speech stopped detected by server.");
break;
// Full user transcription received
case "conversation.item.input_audio_transcription.completed":
console.log("Received transcription: " + data.transcript);
// Render user's message
const userMessageContainer = document.createElement('div');
userMessageContainer.classList.add('character-chat-item', 'item-user');
const userMessage = document.createElement('span');
userMessage.textContent = data.transcript; // Display the transcribed user input text
userMessageContainer.appendChild(userMessage);
// Add user message to chat box
const chatContent = document.querySelector('.ah-character-chat');
chatContent.appendChild(userMessageContainer);
// Scroll to the latest message
chatContent.scrollTop = chatContent.scrollHeight;
// Update local chat history
currentChat.push({ role: "user", content: data.transcript });
activeCharacter.realtimeHistory = currentChat; // Update the selected character's history
setToChromeStorage('realtimeChatHistory', JSON.stringify(realtimeChatHistory)); // Update all characters' history
break;
// Streaming text response
case "response.audio_transcript.delta":
playVideo = true; // Start video playback
const transcript = data.delta; // Incremental content
const responseId = data.response_id;
// console.log("Transcript delta for response_id:", responseId, " Delta: ", transcript);
// Check if response_id already has a cached buffer
if (!markdownBuffer.has(responseId)) {
markdownBuffer.set(responseId, ""); // Initialize the buffer
}
// Accumulate incremental data into the buffer
const existingBuffer = markdownBuffer.get(responseId);
markdownBuffer.set(responseId, existingBuffer + transcript);
// Update the UI
let aiMessageSpan = responseSpans.get(responseId);
if (!aiMessageSpan) {
// If not found, create a new chat container
const aiMessageContainer = document.createElement('div');
aiMessageContainer.classList.add('character-chat-item', 'item-character');
// Create a span element to display the message
aiMessageSpan = document.createElement('span');
aiMessageSpan.classList.add('markdown-content'); // Add CSS class for styling
aiMessageContainer.appendChild(aiMessageSpan);
// Append the new container to the chat box
const chatContainer = document.querySelector('.ah-character-chat');
chatContainer.appendChild(aiMessageContainer);
// Associate the span element with the response_id
responseSpans.set(responseId, aiMessageSpan);
}
// Get the full content and parse it
const fullContent = markdownBuffer.get(responseId);
const parsedContent = marked.parse(fullContent); // Parse full Markdown content
// Update the UI with the new parsed content
aiMessageSpan.innerHTML = parsedContent;
// Highlight code blocks
Prism.highlightAllUnder(aiMessageSpan);
// Scroll to the latest message
const chatContainer = document.querySelector('.ah-character-chat');
chatContainer.scrollTop = chatContainer.scrollHeight;
break;
// Streaming audio response
case "response.audio.delta":
// If the audio delta exists, it would be processed here.
// Currently not implemented for streaming audio.
break;
// Complete transcription of audio response
case "response.audio_transcript.done":
console.log("Received transcription: " + data.transcript);
// Render AI response message
currentChat.push({ role: "assistant", content: data.transcript });
activeCharacter.realtimeHistory = currentChat; // Update the selected character's history
setToChromeStorage('realtimeChatHistory', JSON.stringify(realtimeChatHistory)); // Update all characters' history
break;
// Audio response complete
case "response.audio.done":
console.log("Audio response complete.");
isPlaying = false; // Mark audio playback as finished
playVideo = false; // Stop video playback
break;
// Function call result
case "response.function_call_arguments.done":
console.log("data:" + data);
handleFunctionCall(data); // Handle the function call
break;
default:
console.warn("Unhandled event type: " + data.type); // Handle any unhandled event types
}
}
OpenAI Realtiem API初始化的配置,包括选择的声音,function_call定义,历史对话记录等等:
// Session initialization configuration
async function sendSessionUpdate() {
// console.log("currentChatId:"+currentChatId)
// console.log("currentChat:"+JSON.stringify(currentChat))
const conversationHistory = currentChat ? currentChat : []; // Set conversation history or default to an empty array
// console.log("conversationHistory:"+JSON.stringify(conversationHistory))
let userLanguage = await getFromChromeStorage("userLanguage"); // Get user language preference from Chrome storage
// Session configuration
const sessionConfig = {
type: "session.update",
session: {
instructions: activeCharacter.characterDefinition + ".Please respond in " + userLanguage + ". Please greet the user with a friendly welcome message like:" + activeCharacter.greeting + ". Please use function call results to generate responses when the user's request requires a task beyond the current capabilities of yours. Now you can deal with anything. please use function call especially when the output is related to different modalities such as image, audio, and video. ",
turn_detection: {
type: "server_vad",
threshold: 0.5,
prefix_padding_ms: 300,
silence_duration_ms: 500
},
voice: activeCharacter.voice,
temperature: 1,
max_response_output_tokens: 4096,
modalities: ["text", "audio"],
input_audio_format: "pcm16",
output_audio_format: "pcm16",
input_audio_transcription: {
model: "whisper-1"
},
tools: [
{
type: "function",
name: "function_call_judge",
description: "Determines if the user's request requires a task beyond the current capabilities of yours. If you can't deal with, call the function to expand your capabilities to satisfy the user's needs.",
parameters: {
type: "object",
properties: {
userInput: {
type: "string",
description: "The user's input query or request."
}
},
required: ["userInput"]
}
}
]
}
};
// Send session update
try {
console.log("Sending session update:", JSON.stringify(sessionConfig));
socket.send(JSON.stringify(sessionConfig)); // Send the session configuration to WebSocket server
} catch (e) {
console.error("Error sending session update:", e);
}
// Send conversation history one by one
conversationHistory.forEach((msg) => {
const messageConfig = {
type: "conversation.item.create",
item: {
type: "message",
role: msg.role, // 'user' or 'assistant'
content: [
{
type: "input_text", // Change back to text
text: msg.content
}
]
}
};
// Send each historical conversation item
try {
console.log("Sending message:", JSON.stringify(messageConfig));
socket.send(JSON.stringify(messageConfig)); // Send the message to WebSocket server
} catch (e) {
console.error("Error sending message:", e);
}
});
}获取用户输入音频:
// Function to start recording audio from the user's microphone
function startRecording() {
navigator.mediaDevices.getUserMedia({ audio: true })
.then(stream => {
// Create a new AudioContext with a sample rate of 24000
audioContext = new (window.AudioContext || window.webkitAudioContext)({ sampleRate: 24000 });
audioStream = stream;
const source = audioContext.createMediaStreamSource(stream);
// Create an audio processor with a buffer size of 8192
audioProcessor = audioContext.createScriptProcessor(8192, 1, 1);
// Process the audio data on every audio frame
audioProcessor.onaudioprocess = (event) => {
if (socket && socket.readyState === WebSocket.OPEN) {
// Get the audio data from the input buffer
const inputBuffer = event.inputBuffer.getChannelData(0);
// Convert the float audio data to 16-bit PCM format
const pcmData = floatTo16BitPCM(inputBuffer);
// Encode the PCM data to base64
const base64PCM = base64EncodeAudio(new Uint8Array(pcmData));
// Send the audio in chunks of 4096 bytes
const chunkSize = 4096;
for (let i = 0; i < base64PCM.length; i += chunkSize) {
const chunk = base64PCM.slice(i, i + chunkSize);
// Send each chunk of audio data to the WebSocket
socket.send(JSON.stringify({ type: "input_audio_buffer.append", audio: chunk }));
}
}
};
// Connect the audio source to the processor and then to the audio context's destination (speakers)
source.connect(audioProcessor);
audioProcessor.connect(audioContext.destination);
console.log("Recording started");
})
.catch(error => {
// Log an error if the microphone cannot be accessed
console.error("Unable to access microphone: ", error);
});
}
// Function to convert 32-bit float audio data to 16-bit PCM format
function floatTo16BitPCM(float32Array) {
const buffer = new ArrayBuffer(float32Array.length * 2); // 2 bytes per sample
const view = new DataView(buffer);
let offset = 0;
for (let i = 0; i < float32Array.length; i++, offset += 2) {
// Clamp the value between -1 and 1
let s = Math.max(-1, Math.min(1, float32Array[i]));
// Convert the float to a 16-bit signed integer and store it in the buffer
view.setInt16(offset, s < 0 ? s * 0x8000 : s * 0x7fff, true);
}
return buffer;
}
// Function to encode the audio data (in uint8Array) into a base64 string
function base64EncodeAudio(uint8Array) {
let binary = '';
const chunkSize = 0x8000; // 32KB chunk size to keep the size manageable
for (let i = 0; i < uint8Array.length; i += chunkSize) {
const chunk = uint8Array.subarray(i, i + chunkSize);
// Convert each chunk into a binary string
binary += String.fromCharCode.apply(null, chunk);
}
// Convert the binary string into a base64 encoded string
return btoa(binary);
}
// Function to stop recording and clean up resources
function stopRecording() {
if (audioProcessor) {
// Disconnect the audio processor from the audio context
audioProcessor.disconnect();
}
if (audioStream) {
// Stop the microphone tracks
audioStream.getTracks().forEach(track => track.stop());
}
if (socket) {
// Close the WebSocket connection
socket.close();
}
}
3.1.2 JAVA WebSocket
后端建立于Realtime API的连接:
package com.company.project.web.api;
import com.company.project.util.RealTimeSpeechUtil;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import okhttp3.*;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
import org.springframework.web.socket.CloseStatus;
import org.springframework.web.socket.TextMessage;
import org.springframework.web.socket.WebSocketSession;
import org.springframework.web.socket.handler.TextWebSocketHandler;
import javax.sound.sampled.AudioFormat;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.math.BigDecimal;
import java.time.Instant;
import java.time.Duration;
import java.util.Base64;
import java.util.Date;
import java.util.UUID;
import java.util.concurrent.atomic.AtomicBoolean;
@Component
public class RealTimeSpeechWebsocket extends TextWebSocketHandler {
@Value("${apiKey}")
private String OPENAI_API_KEY; // API key for OpenAI
@Autowired
RealTimeSpeechUtil realTimeSpeechUtil; // Utility for real-time speech processing
private static final String OPENAI_WS_URL = "wss://api.openai.com/v1/realtime?model=gpt-4o-realtime-preview-2024-10-01"; // WebSocket URL for OpenAI
String license; // License string for the session
String audioPath; // Path where audio files are saved
private final OkHttpClient client = new OkHttpClient(); // HTTP client for OpenAI WebSocket connection
private WebSocket openAIWebSocket; // WebSocket connection to OpenAI
private WebSocketSession clientSession; // WebSocket session for the client
private Instant startTime; // Start time of the session
private double accruedDuration = 0.0; // Accumulated call duration
private BigDecimal sessionSurplusQuantity; // Local copy of points available
private Process pythonProcess; // Process for running Python scripts
private AtomicBoolean isDisplayThreadRunning; // Shared flag to control display thread
private final AudioFormat audioFormat = new AudioFormat(24000, 16, 1, true, false); // Audio format for recording (mono, 24kHz, 16-bit)
/**
* Extracts the license from the WebSocket session URI.
* @param session WebSocket session
* @return license string or null if not found
*/
private String getLicense(WebSocketSession session) {
String query = session.getUri().getQuery();
if (query != null && query.contains("license=")) {
String[] queryParams = query.split("&");
for (String param : queryParams) {
if (param.startsWith("license=")) {
String[] keyValue = param.split("=", 2);
if (keyValue.length == 2) {
return keyValue[1]; // Return the license value
}
}
}
}
return null; // No license parameter found
}
@Override
public void afterConnectionEstablished(WebSocketSession session) throws Exception {
this.clientSession = session;
// Retrieve the 'license' and 'characterName' parameters from the session URI
String license = getQueryParameter(session, "license");
String characterName = getQueryParameter(session, "characterName");
// Close the connection if either parameter is missing
if (license == null) {
session.close(CloseStatus.NORMAL.withReason("Missing license parameter"));
return;
}
if (characterName == null) {
session.close(CloseStatus.NORMAL.withReason("Missing characterName parameter"));
return;
}
// Set the path to save audio files
audioPath = "C:\\Users\\FrankFuRTX\\Desktop\\easyone\\" + license + "\\audio";
startTime = Instant.now(); // Record the start time
// Establish a WebSocket connection to OpenAI's Realtime API
Request request = new Request.Builder()
.url(OPENAI_WS_URL)
.addHeader("Authorization", "Bearer " + OPENAI_API_KEY) // Authorization header with API key
.addHeader("OpenAI-Beta", "realtime=v1") // Set the realtime mode
.build();
openAIWebSocket = client.newWebSocket(request, new WebSocketListener() {
@Override
public void onOpen(WebSocket webSocket, Response response) {
System.out.println("Connected to OpenAI Realtime API.");
// Prepare video name and path for further processing
String videoName = characterName;
String mp4Path = videoName;
String projectRootDir = "C:\\Users\\FrankFuRTX\\Desktop\\MuseTalk-main";
String outputDir = projectRootDir + "\\results\\avatars\\" + license + "\\vid_output";
isDisplayThreadRunning = new AtomicBoolean(true);
// Asynchronously execute the Python script for generating digital human content
pythonProcess = RealTimeSpeechUtil.generateDigitalHuman(
license,
audioPath,
characterName,
projectRootDir,
outputDir,
mp4Path,
isDisplayThreadRunning,
session
);
}
@Override
public void onMessage(WebSocket webSocket, String text) {
try {
// Parse the incoming JSON message
ObjectMapper objectMapper = new ObjectMapper();
JsonNode jsonNode = objectMapper.readTree(text);
// Check for 'response.audio.delta' type message
String eventType = jsonNode.get("type").asText();
if ("response.audio.delta".equals(eventType)) {
clientSession.sendMessage(new TextMessage(text)); // Forward the message to the client
String delta = jsonNode.has("delta") ? jsonNode.get("delta").asText() : "";
if (!delta.isEmpty()) {
byte[] audioData = Base64.getDecoder().decode(delta); // Decode the audio delta data
// Save the audio data as a WAV file
saveAudioAsWav(audioData);
System.out.println("Audio data saved as WAV file, size: " + audioData.length + " bytes");
}
} else if (clientSession.isOpen()) {
// For non-audio messages, forward them to the client
clientSession.sendMessage(new TextMessage(text));
}
} catch (Exception e) {
System.err.println("Error processing message: " + e.getMessage());
}
}
@Override
public void onFailure(WebSocket webSocket, Throwable t, Response response) {
System.err.println("OpenAI WebSocket connection failed: " + t.getMessage());
// Terminate Python process if the connection fails
if (pythonProcess != null && pythonProcess.isAlive()) {
pythonProcess.destroy();
}
// Stop the display thread
isDisplayThreadRunning.set(false);
}
@Override
public void onClosing(WebSocket webSocket, int code, String reason) {
System.out.println("OpenAI WebSocket closing: " + reason);
// Terminate Python process on WebSocket closing
if (pythonProcess != null && pythonProcess.isAlive()) {
pythonProcess.destroy();
}
// Stop the display thread
isDisplayThreadRunning.set(false);
}
});
}
@Override
protected void handleTextMessage(WebSocketSession session, TextMessage message) throws Exception {
// Forward the text message to the OpenAI WebSocket
if (openAIWebSocket != null) {
openAIWebSocket.send(message.getPayload());
}
}
@Override
public void afterConnectionClosed(WebSocketSession session, CloseStatus status) throws Exception {
// Close the OpenAI WebSocket connection
if (openAIWebSocket != null) {
openAIWebSocket.close(1000, "Client closed connection");
}
// Calculate the final call duration and log it
Instant endTime = Instant.now();
double duration = Duration.between(startTime, endTime).toMillis() / 1000.0;
double chargeableDuration = Math.max(duration, 5.0);
}
/**
* Retrieves the query parameter from the WebSocket session URI.
* @param session WebSocket session
* @param key The key of the parameter to retrieve
* @return The parameter value or null if not found
*/
private String getQueryParameter(WebSocketSession session, String key) {
String query = session.getUri().getQuery(); // Get the query string from the session URI
if (query != null && !query.isEmpty()) {
String[] pairs = query.split("&"); // Split query into key-value pairs
for (String pair : pairs) {
String[] keyValue = pair.split("="); // Split each pair into key and value
if (keyValue.length == 2 && keyValue[0].equals(key)) {
return keyValue[1]; // Return the value for the matching key
}
}
}
return null; // Return null if the parameter is not found
}
/**
* Converts PCM audio data to WAV format and saves it as a file.
* @param pcmData PCM byte data
*/
private void saveAudioAsWav(byte[] pcmData) {
try {
// Retrieve the license for saving the audio file
String license = getLicense(clientSession);
if (license == null) {
System.err.println("Unable to get license, audio file save failed.");
return;
}
// Create a WAV file using the PCM data
File wavFile = new File(audioPath + "\\" + license + ".wav");
try (FileOutputStream fos = new FileOutputStream(wavFile)) {
fos.write(pcmData); // Write the PCM data into the file
}
} catch (IOException e) {
System.err.println("Error saving audio as WAV: " + e.getMessage());
}
}
}3.2 修改Musetalk源码,实现读取音频文件夹
这里我们需要修改Musetalk项目,使其不依赖于命令运行,而是不停循环读取指定音频文件夹下的音频数据。同时太短的音频生成的视频效果并不好,我们将音频合成到2秒时,达到了视频产出略高于视频消费,同时音口同型的最佳输出。我们修改realtime_inference.py文件:
if __name__ == "__main__":
'''
This script simulates an online chat and performs necessary preprocessing steps,
such as face detection and face parsing. During the online chat, only the UNet
and VAE decoders are involved, which enables MuseTalk to achieve real-time performance.
'''
# Parse command-line arguments
parser = argparse.ArgumentParser()
parser.add_argument("--avatar_id",
type=str,
required=True,
help="Avatar ID")
parser.add_argument("--preparation",
type=str,
default="true",
help="Whether to perform data preparation (true/false)")
parser.add_argument("--bbox_shift",
type=int,
default=-7,
help="Bounding box offset")
parser.add_argument("--fps",
type=int,
default=25,
help="Video frame rate")
parser.add_argument("--batch_size",
type=int,
default=4,
help="Batch size")
parser.add_argument("--skip_save_images",
action="store_true",
help="Whether to skip saving images to improve generation speed")
parser.add_argument("--audio_folder",
type=str,
required=True,
help="Folder path for dynamically reading audio files")
parser.add_argument("--mp4_path",
type=str,
required=True,
help="MP4 file save path")
args = parser.parse_args()
# Parse the 'preparation' argument to boolean value
preparation = args.preparation.lower() == "true"
bbox_shift = args.bbox_shift
# Construct the mp4_path based on avatar_id
video_path = f"./data/video/{args.mp4_path}.mp4"
# Define temporary and images directories
tmp_dir = f"./results/avatars/{args.avatar_id}/tmp"
images_dir = f"./results/avatars/{args.avatar_id}/images"
os.makedirs(images_dir, exist_ok=True) # Ensure images directory exists
# Initialize Avatar instance, passing mp4_path parameter
avatar = Avatar(
avatar_id=args.avatar_id,
video_path=video_path,
bbox_shift=bbox_shift,
batch_size=args.batch_size,
preparation=preparation,
tmp_dir=tmp_dir,
images_dir=images_dir,
)
# Dynamically read audio files folder and build audio_clips dictionary
counter = 0 # Define counter
def get_audio_duration(audio_path):
"""
Get the duration of the audio file using ffprobe
"""
command = [
"ffprobe", "-i", audio_path, "-show_entries", "format=duration",
"-v", "quiet", "-of", "csv=p=0"
]
result = subprocess.run(command, stdout=subprocess.PIPE, stderr=subprocess.PIPE, check=True)
return float(result.stdout.strip())
while True:
# List all audio files in the folder that ends with .wav
audio_files = sorted(
[os.path.join(args.audio_folder, f) for f in os.listdir(args.audio_folder) if f.endswith(".wav")]
)
if not audio_files:
time.sleep(1)
continue
audio_to_merge = []
total_duration = 0.0
i = 0
n = len(audio_files)
while i < n:
audio_path = audio_files[i]
duration = get_audio_duration(audio_path)
if duration < 1.0:
# If the current audio file is less than 1 second, add to merge queue
audio_to_merge.append(audio_path)
total_duration += duration
i += 1
# If the total duration of merged files reaches 1 second, start processing
if total_duration >= 1.0:
# Merge the collected audio files
merged_audio_filename = f"{args.avatar_id}_{str(counter).zfill(8)}.wav"
merged_audio_path = os.path.join(args.audio_folder, merged_audio_filename)
# Create audio_list.txt for ffmpeg concat command
with open("audio_list.txt", "w") as f:
for audio in audio_to_merge:
f.write(f"file '{audio}'\n")
merge_command = [
"ffmpeg", "-f", "concat", "-safe", "0", "-i", "audio_list.txt",
"-c", "copy", merged_audio_path
]
subprocess.run(merge_command, stdout=subprocess.PIPE, stderr=subprocess.PIPE, check=True)
# Get the actual duration of the merged audio
merged_audio_duration = get_audio_duration(merged_audio_path)
print(f"Actual duration of merged audio: {merged_audio_duration:.2f} seconds")
# Infer using the merged audio
print("Inferring using merged audio:", merged_audio_path)
avatar.inference(merged_audio_path, merged_audio_filename, args.fps, args.skip_save_images)
# Delete processed audio files and merged file
for audio in audio_to_merge:
os.remove(audio)
print(f"Deleted processed audio file: {audio}")
os.remove(merged_audio_path)
print(f"Deleted merged temporary audio file: {merged_audio_path}")
# Clean up temporary files
if os.path.exists("audio_list.txt"):
os.remove("audio_list.txt")
# Increment the counter
counter += 1
# Clear the audio merge queue
audio_to_merge = []
total_duration = 0.0
else:
# If the current audio is greater than or equal to 1 second, merge in pairs
audio_to_merge.append(audio_path)
i += 1
if len(audio_to_merge) == 2:
# Prepare to merge two audio files
merged_audio_filename = f"{args.avatar_id}_{str(counter).zfill(8)}.wav"
merged_audio_path = os.path.join(args.audio_folder, merged_audio_filename)
# Create audio_list.txt for ffmpeg concat command
with open("audio_list.txt", "w") as f:
for audio in audio_to_merge:
f.write(f"file '{audio}'\n")
merge_command = [
"ffmpeg", "-f", "concat", "-safe", "0", "-i", "audio_list.txt",
"-c", "copy", merged_audio_path
]
subprocess.run(merge_command, stdout=subprocess.PIPE, stderr=subprocess.PIPE, check=True)
# Get the actual duration of the merged audio
merged_audio_duration = get_audio_duration(merged_audio_path)
print(f"Actual duration of merged audio: {merged_audio_duration:.2f} seconds")
# Infer using the merged audio
print("Inferring using merged audio:", merged_audio_path)
avatar.inference(merged_audio_path, merged_audio_filename, args.fps, args.skip_save_images)
# Delete processed audio files and merged file
for audio in audio_to_merge:
os.remove(audio)
print(f"Deleted processed audio file: {audio}")
os.remove(merged_audio_path)
print(f"Deleted merged temporary audio file: {merged_audio_path}")
# Clean up temporary files
if os.path.exists("audio_list.txt"):
os.remove("audio_list.txt")
# Increment the counter
counter += 1
# Clear the audio merge queue
audio_to_merge = []
time.sleep(0.5) # Control the frequency of the loop3.3 Musetalk启动线程,视频结果读取线程
我们已经建立其前端,后端,Realtime API 三者之间的双向通信。现在我们需要开启线程,执行Musetalk项目,这里以执行脚本的方式运行该项目。同时启动视频结果读取线程,通过websocket将生成好的一个个视频推送到前端。
package com.company.project.util;
import org.springframework.stereotype.Component;
import org.springframework.web.socket.BinaryMessage;
import org.springframework.web.socket.WebSocketSession;
import java.io.*;
import java.nio.file.Files;
import java.util.Arrays;
import java.util.Comparator;
import java.util.Map;
import java.util.UUID;
import java.util.concurrent.atomic.AtomicBoolean;
@Component
public class RealTimeSpeechUtil {
/**
* Generates a digital human with the given parameters.
*
* @param avatarId The avatar ID.
* @param audioDir The directory path containing audio files.
* @param characterName The character name (with extension).
* @param projectRootDir The root directory of the project.
* @param outputDir The directory where output will be saved.
* @param mp4Path The path to the MP4 video.
* @param runningFlag A flag to indicate whether the process is running.
* @param session The WebSocket session to send video frames.
* @return The Process object representing the running process.
*/
public static Process generateDigitalHuman(String avatarId, String audioDir, String characterName,
String projectRootDir, String outputDir, String mp4Path, AtomicBoolean runningFlag, WebSocketSession session) {
try {
// Ensure the output directory exists
File outputDirectory = new File(outputDir);
if (!outputDirectory.exists()) {
outputDirectory.mkdirs();
}
// Call the Python script to process the audio files
Process pythonProcess = callPythonScript(projectRootDir, avatarId, audioDir, mp4Path);
// Start a new thread to monitor and send video frames
Thread displayThread = new Thread(() -> {
try {
monitorAndSendVideo(outputDir, pythonProcess, runningFlag, session);
} catch (Exception e) {
e.printStackTrace();
}
});
displayThread.start();
return pythonProcess; // Return the running Process object
} catch (Exception e) {
e.printStackTrace();
}
return null; // Return null if an error occurs
}
/**
* Calls the Python script to process the digital human generation.
*
* @param projectRootDir The root directory of the project.
* @param avatarId The avatar ID.
* @param audioDir The directory containing audio files.
* @param mp4Path The path to the MP4 video.
* @return The running Process object.
* @throws IOException If there is an issue starting the process.
*/
private static Process callPythonScript(String projectRootDir, String avatarId, String audioDir, String mp4Path) throws IOException {
String[] command = {
"python",
"-u",
"-m", "scripts.realtime_inference",
"--avatar_id", avatarId,
"--preparation", "true", // Set to true since it's initialized on the Java side
"--bbox_shift", "-7",
"--fps", "25",
"--batch_size", "6",
"--audio_folder", audioDir,
"--mp4_path", mp4Path
};
ProcessBuilder pb = new ProcessBuilder(command);
pb.directory(new File(projectRootDir));
Map<String, String> env = pb.environment();
env.put("PATH", "C:\\Software\\ffmpeg-7.1-essentials_build\\bin;" + env.get("PATH"));
env.put("PYTHONIOENCODING", "utf-8");
pb.redirectErrorStream(true);
Process process = pb.start();
// Asynchronously print the output of the Python script
new Thread(() -> {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(process.getInputStream()))) {
String line;
while ((line = reader.readLine()) != null) {
System.out.println("[Python] " + line);
}
} catch (IOException e) {
e.printStackTrace();
}
}).start();
return process;
}
/**
* Monitors the video frame directory and sends video frames through WebSocket.
*
* @param framesDir The directory containing video frames.
* @param pythonProcess The running Python process.
* @param runningFlag A flag to indicate whether the process should continue running.
* @param session The WebSocket session to send the frames.
*/
private static void monitorAndSendVideo(String framesDir, Process pythonProcess, AtomicBoolean runningFlag, WebSocketSession session) {
File dir = new File(framesDir);
System.out.println("Started monitoring directory: " + framesDir);
while (runningFlag.get() && pythonProcess.isAlive()) {
long start = System.currentTimeMillis();
// Get all MP4 video files in the directory
File[] videoFiles = dir.listFiles((d, name) -> name.endsWith(".mp4"));
if (videoFiles != null && videoFiles.length > 0) {
// Sort the files by name to ensure correct order
Arrays.sort(videoFiles, Comparator.comparing(File::getName));
for (File videoFile : videoFiles) {
if (!runningFlag.get()) {
break; // Exit the loop if the running flag is cleared
}
try {
// Convert the video file to fragmented MP4 format
byte[] fmp4Data = convertToFragmentedMp4(videoFile);
long end = System.currentTimeMillis();
LogUtils.info("Time taken: " + (end - start));
// Send the fragmented MP4 data via WebSocket
if (session.isOpen()) {
session.sendMessage(new BinaryMessage(fmp4Data));
System.out.println("Sent fMP4 video segment: " + videoFile.getName());
}
// Delete the video file after sending
boolean deleted = videoFile.delete();
if (deleted) {
System.out.println("Deleted video file: " + videoFile.getName());
} else {
System.err.println("Failed to delete video file: " + videoFile.getName());
}
} catch (IOException e) {
System.err.println("Failed to read or send video file: " + videoFile.getAbsolutePath());
e.printStackTrace();
}
}
} else {
// If the folder is empty, wait for a while before checking again
try {
Thread.sleep(500); // Check the directory every 500 milliseconds
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
System.out.println("Video monitoring thread stopped");
}
/**
* Converts the video file to a fragmented MP4 format.
*
* @param videoFile The video file to be converted.
* @return The byte array of the fragmented MP4 data.
* @throws IOException If there is an issue with the file conversion.
*/
private static byte[] convertToFragmentedMp4(File videoFile) throws IOException {
File tempDir = new File("C:\\Users\\FrankFuRTX\\Desktop\\temp");
if (!tempDir.exists()) {
tempDir.mkdirs();
}
File tempFmp4File = new File(tempDir, "fragmented_" + System.currentTimeMillis() + ".mp4");
try {
if (!videoFile.exists()) {
throw new IOException("Input file does not exist: " + videoFile.getAbsolutePath());
}
// Get the total duration of the video
double totalDuration = getVideoDuration(videoFile.getAbsolutePath());
if (newDuration <= 0) {
throw new IOException("Video duration is less than or equal to 0.09 seconds, cannot trim.");
}
// Build the ffmpeg command to trim the last 0.09 seconds
String[] command = {
"ffmpeg",
"-i", videoFile.getAbsolutePath(),
"-t", String.valueOf(totalDuration ),
"-c:v", "libx264",
"-profile:v", "high",
"-level:v", "4.0",
"-c:a", "aac",
"-movflags", "frag_keyframe+empty_moov+default_base_moof", // Ensure each video segment includes initialization info
"-avoid_negative_ts", "make_zero",
tempFmp4File.getAbsolutePath()
};
ProcessBuilder pb = new ProcessBuilder(command);
pb.redirectErrorStream(true);
Process process = pb.start();
try (BufferedReader reader = new BufferedReader(new InputStreamReader(process.getInputStream()))) {
String line;
while ((line = reader.readLine()) != null) {
System.out.println("[FFMPEG] " + line);
}
}
int exitCode = process.waitFor();
if (exitCode != 0) {
throw new IOException("ffmpeg conversion failed, exit code: " + exitCode);
}
// Save the fMP4 file for debugging
System.out.println("fMP4 file generated: " + tempFmp4File.getAbsolutePath());
return Files.readAllBytes(tempFmp4File.toPath());
} catch (InterruptedException e) {
throw new IOException("ffmpeg conversion interrupted", e);
} finally {
// Commenting out deletion of the temporary file for debugging purposes
// if (tempFmp4File.exists() && !tempFmp4File.delete()) {
// System.err.println("Failed to delete temporary file: " + tempFmp4File.getAbsolutePath());
// }
}
}
/**
* Gets the duration of a video using ffmpeg.
*
* @param videoPath The path to the video file.
* @return The total duration of the video in seconds.
* @throws IOException If there is an issue with the ffmpeg process.
*/
private static double getVideoDuration(String videoPath) throws IOException {
ProcessBuilder pb = new ProcessBuilder("ffmpeg", "-i", videoPath);
Process process = pb.start();
try (BufferedReader reader = new BufferedReader(new InputStreamReader(process.getErrorStream()))) {
String line;
while ((line = reader.readLine()) != null) {
if (line.contains("Duration")) {
String[] parts = line.split(",")[0].split(" ")[1].split(":");
int hours = Integer.parseInt(parts[0]);
int minutes = Integer.parseInt(parts[1]);
double seconds = Double.parseDouble(parts[2]);
return hours * 3600 + minutes * 60 + seconds;
}
}
}
throw new IOException("Failed to retrieve video duration for: " + videoPath);
}
}3.4 前端接收传来的视频流,并显示
// 处理 WebSocket 中接收到的二进制 fMP4 数据
function handleReceivedBinaryMessage(arrayBuffer) {
try {
if (sourceBuffer && !sourceBuffer.updating) {
// 如果是流式数据,切换为流模式
if (!isStreaming) {
console.log("开始流式播放...");
isStreaming = true;
videoElement.src = URL.createObjectURL(mediaSource); // 切换到流媒体源
// 开始播放后,取消静音
videoElement.muted = false; // 恢复音频
console.log("恢复音频播放...");
}
// 如果缓冲区已经包含数据,可以移除旧数据
if (sourceBuffer.buffered.length > 0) {
let startTime = sourceBuffer.buffered.start(0);
let endTime = sourceBuffer.buffered.end(0);
if (endTime - startTime > 10) { // 如果视频已经播放了10秒,移除缓冲区的内容
console.log("缓冲区数据已播放,移除已播放部分...");
sourceBuffer.remove(0, startTime);
}
}
// 将接收到的 fMP4 数据传递到 SourceBuffer
console.log("接收到 fMP4 数据,正在添加到 SourceBuffer...");
sourceBuffer.appendBuffer(arrayBuffer);
// 在数据添加完毕后,确保视频能继续播放
sourceBuffer.addEventListener('updateend', () => {
// 强制播放
if (videoElement.paused) {
videoElement.play();
}
console.log("更新完成,视频继续播放...");
});
} else {
console.warn("SourceBuffer 正在更新,等待完成后再传送数据");
}
} catch (e) {
console.error("Error appending data to SourceBuffer:", e);
resetSourceBuffer(); // 如果遇到错误,尝试重置 SourceBuffer
}
}
自此我们搭建了一个较为完整的数字人框架,可以调试运行,看看具体的输出效果。
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝
